HBase 笔记3
数据模型
Namespace 表命名空间: 多个表分到一个组进行统一的管理,需要用到表命名空间
表命名空间主要是对表分组,对不同组进行不同环境设定,如配额管理 安全管理
保留表空间: HBase中有2个保留表空间是预先定义
HBase 系统表空间,用于HBase内部表
default: 哪些没有定义表空间的表都被分配到这个下面
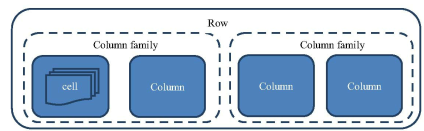
Table 表:由一个或多个列族组成
Row 行:一行包含多个列,这些列通过列族分类
ColumnFamily 列族:列族是多个列的集合
Column Qualifier列: 多个列组成一行,列可以随意定义的,一个行中的列不限名字,不限数量,只限定列族
cell 单元格: 一个列中可以存储多个版本的数据,每个版本称为一个单元格cell
Timestamp 时间戳:也可以称为版本号
HBase存储数据
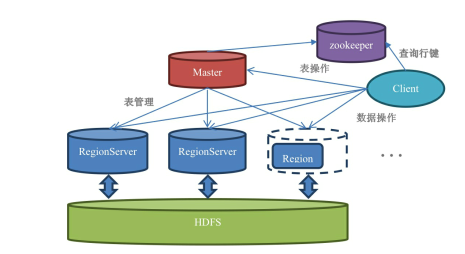
Master: 负责启动的时候分配Region到具体的Region Server,执行各种管理操作,如Region的分割和合并
RegionServer:一个Region Server上存在一个或多个Region,就是多个Region的集合
Region: 表的一部分数据,HBase是一个自动分片的数据库,一个Region相当于关系型数据库中分区表的一个分区,每个region都有其实起始rowkey和结束rowkey
HDFS:Hadoop一部分,HBASE与HDFS交互,HDFS是真正承载数据库的载体
Zookeeper:第三方组件,不属于HBase。client需要读取的元数据表hbase:meta位置存在zookeeper上
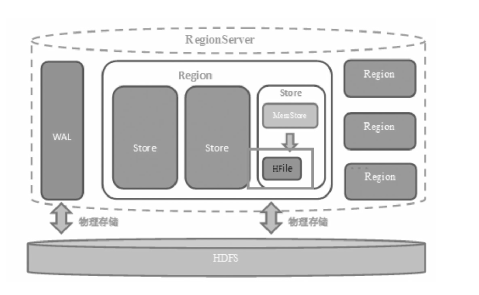
当操作到达Region时,HBase会把操作写入WAL(预写日志)中,同时数据存在基于内存的Memstore里,待达到一定数据量,刷写flush 到最终存储HFile内
故障恢复时,使用WAL可以恢复数据
Store:每个region中包含多个Store实例,一个Store对应一个列组的数据
memstore: 由于HDFS上文件不可修改, 数据会在memstore中整理成LSM树(顺序存储),之后刷写到HFile中,提高读取效率
读取数据时先读取blockcache,再读取HFile+memstore
WAL 预写日志是解决宕机之后的恢复问题
数据到达Region时先写入WAL,然后再加载到memstore中,WAL中数据存储再HDFS上,不会丢失
关闭/打开WAL

异步的同步WAL

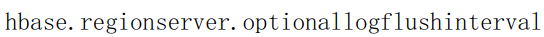 HBase间隔多久会把操作从内存写入WAL,默认1s
HBase间隔多久会把操作从内存写入WAL,默认1s
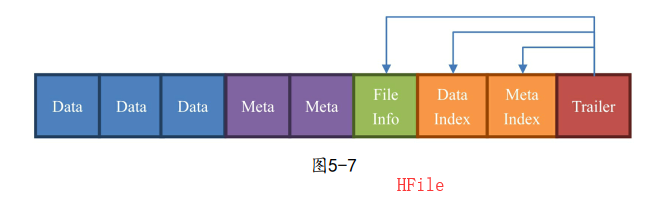
HFile由一个一个块组成,再HBase中一个块默认64KB,由列族上BLOCKSIZE属性定义
Data:数据块 存储HBase表中的数据
Meta: 元数据快 存储该HFile文件的元数据信息
FileInfo 文件信息,时HFile的必要组成部分,存储这个文件的信息,如最后一个Key,平均Key的长度
DataIndex 存储Data块索引信息的块文件么就是Data块的偏移值
MetaIndex : 存储Meta块索引信息的块文件
Trailer 必选,存储FileInfo DataIndex MetaIndex 块的偏移值'

Data数据块的第一位存储的是块的类型,后面存储的是多个keyvalue键值对,也就是单元格cell的实现类
cell是一个接口,keyvalue是实现类

Row 行键 CF 列族 Col 列 TimeStamp 时间戳
增删改查真面目:
HBase的增删改查实际都是新增操作:
新增单元格时,HBase在HDFS上新增一条数据
修改一个单元格时,HBase在HDFS上又新增一条数据,只是版本号比之前的大
删除一个单元格时,HBase还是新增数据,只是数据没有value,类型为delete,并打上墓碑标记
数据真正删除时是HFile合并时,忽略墓碑标记的数据,完成删除
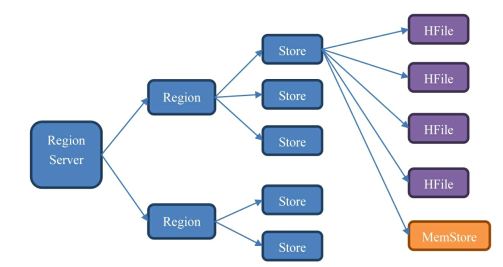
数据写入

数据发出的第一时间被写入WAL,随后数据会立即被放入memstore中整理,最后当memstore太大达到阈值后,Flush到存储在硬盘上的HFile文件
数据读取
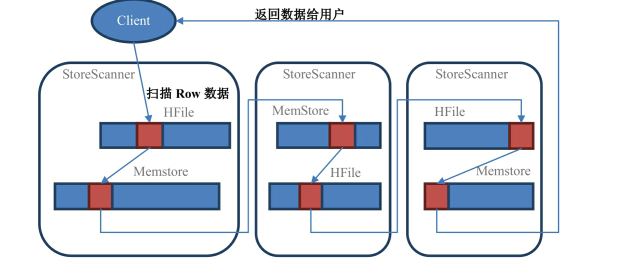
HBase 的scan操作会读取行键中的所有值,这样才能确定返回哪些数据(数据和墓碑标记不是存放在一起的)
在Scan时store会创建store scanner实例把么么store和hfile结合起来扫描,storescanner打开时,会先定位起始行键startRow上,开始往下扫描
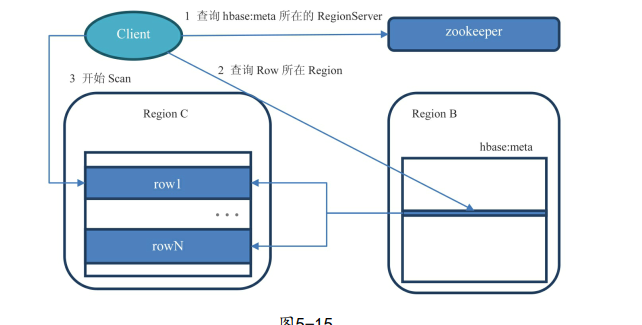
Region定位:

.META 元数据表,存储了所有的Region信息,一行记录就是一个Region,记录了Region的起始行,结束行,和该Region的连接信息,这样client可以通过这个来判断需要的数据在哪个region上
-ROOT- 存储.META.的表的表 ,即存储了.Meta.在什么Region上的信息
1)用户通过查找zookeeper上的/hbase/root-region-server节点获取-ROOT-表在哪个Region Server上
2)访问-ROOt-表,看数据在哪个.Meta.表上,这个表在哪个Region Server上
3)访问.Meta.表查询行键在哪个region里
4)连接具体数据所在的Region Server上,使用scan遍历row
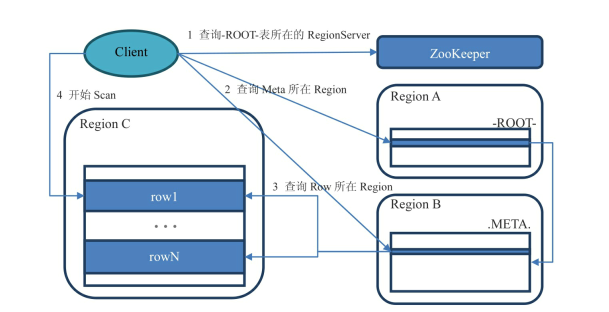
从0.96版本之后,三层查询架构改成二层,-ROOT-去掉,.Meta.表所在的region server信息存储在ZK中的/hbase/meta-region-server中,再后来引入namespace,.Meta.表修改为hbase:meta
HBase 笔记3的更多相关文章
- HBase笔记:对HBase原理的简单理解
早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了.现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbas ...
- Hbase笔记——RowKey设计
一).什么情况下使用Hbase 1)传统数据库无法承载高速插入.大量读取. 2)Hbase适合海量,但同时也是简单的操作. 3)成熟的数据分析主题,查询模式确立不轻易改变. 二).现实场景 1.电商浏 ...
- HBase笔记--自定义filter
自定义filter需要继承的类:FilterBase 类里面的方法调用顺序 方法名 作用 1 boolean filterRowKey(Cell cell) 根据row key过滤row.如果需要 ...
- HBase笔记--filter的使用
HBASE过滤器介绍: 所有的过滤器都在服务端生效,叫做谓语下推(predicate push down),这样可以保证被过滤掉的数据不会被传送到客户端. 注意: 基于字符串的比较器,如 ...
- HBase笔记--编程实战
HBase总结:http://blog.csdn.net/lifuxiangcaohui/article/details/39997205 (very good) Spark使用Java读取hbas ...
- HBase笔记--安装及启动过程中的问题
1.使用hbase shell的时候运行命令执行失败 例如:在shell下执行 status,失败. 可能的原因:节点之间的时间差距过大 解决方法调整两个节点的时间,使二者一致,这里用了个比较笨的方法 ...
- HBase笔记6 过滤器
过滤器 过滤器是GET或者SCAN时过滤结果用的,相当于SQL的where语句 HBase中的过滤器创建后会被序列化,然后分发到各个region server中,region server会还原过滤器 ...
- HBase笔记5(诊断)
阻塞急救: RegionServer内存设置太小: 解决方案: 设置Region Server的内存要在conf/hbase-env.sh中添加export HBASE_REGIONSERVER_OP ...
- HBase笔记4(调优)
Master/Region Server调优 JVM调优 默认的RegionServer内存是1G,而Memstore默认占40%,即400M,实在是太小了,可以通过HBASE_HEAPSIZE参数修 ...
随机推荐
- windows redis 连接错误Creating Server TCP listening socket 127.0.0.1:637 9: bind: No error
报错信息如下: [10036] 30 Dec 10:23:49.616 # Creating Server TCP listening socket 127.0.0.1:637 9: bind: No ...
- FlexCel 插入公式和插入新行
//http://www.tmssoftware.biz/flexcel/doc/vcl/api/FlexCel.Core/TExcelFile/InsertAndCopyRange.html#tex ...
- node-sass 安装失败 Failed at the node-sass@4.9.2 postinstall script的解决
控制台运行npm install时报错,报错信息如下: npm ERR! code ELIFECYCLEnpm ERR! errno 1npm ERR! node-sass@4.9.2 postins ...
- 【2019年04月09日】A股净资产收益率ROE最高排名
个股滚动ROE = 最近4个季度的归母净利润 / ((期初归母净资产 + 期末归母净资产) / 2). 查看更多个股ROE最高排名. 沈阳机床(SZ000410) - 滚动ROE:251.45% - ...
- Laravel Homestead 离线安装
一.写在之前,网络不够快想要安装Homestead,也是一个浩大的工程,对于下载一个 1.22G左右的 laravel/homestead box 也是非常的麻烦.那么如何才能离线安装呢? 接着往下看 ...
- VS F5不编译 F5总是重新编译
遇到奇怪的现象,F5不编译了 右键解决方案-配置管理器-确保项目的生成被勾选 另外一个情况,即使不修改任何代码,每次点击“生成”或者F5,都会重新编译(Debug模式没问题,Release有这个问题, ...
- 3D Object Classification With Point Convolution —— 点云卷积网络
今天刚刚得到消息,之前投给IROS 2017的文章收录了.很久很久没有写过博客,今天正好借这个机会来谈谈点云卷积网络的一些细节. 1.点云与三维表达 三维数据后者说空间数据有很多种表达方式,比如:RG ...
- 1.11 flask
2019-1-11 16:14:34 还有一天flask剩下的就是爬虫了! 越努力,越幸运!永远不要高估自己! 别人玩,你在默默努力!上帝不会亏待你的! Flask-SQLAlchemy参考连接 ht ...
- G - Throw nails
来源hde4393 The annual school bicycle contest started. ZL is a student in this school. He is so boring ...
- A - Black Box 优先队列
来源poj1442 Our Black Box represents a primitive database. It can save an integer array and has a spec ...