Pandas 基础(9) - 组合方法 merge
首先, 还是以天气为例, 准备如下数据:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando'],
'temperature': [21, 24, 32],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando'],
'humidity': [89, 79, 80],
})
df = pd.merge(df1, df2, on='city')
输出: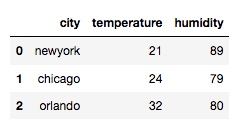
上面的例子就是以 'city' 为基准对两个 dataframe 进行合并, 但是两组数据都是高度一致, 下面调整一下:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando', 'baltimore'],
'temperature': [21, 24, 32, 29],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'san francisco'],
'humidity': [89, 79, 80],
})
df = pd.merge(df1, df2, on='city')
输出: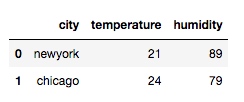
从输出我们看出, 通过 merge 合并, 会取两个数据的交集.
那么, 我们应该可以设想到, 可以通过调整参数, 来达到不同的取值范围.
取并集:
df = pd.merge(df1, df2, on='city', how='outer')
输出: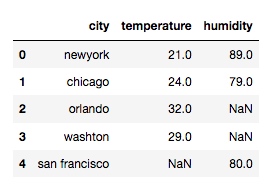
左对齐:
df = pd.merge(df1, df2, on='city', how='left')
输出:
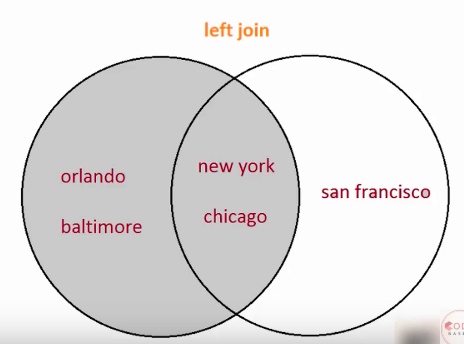
右对齐:
df = pd.merge(df1, df2, on='city', how='right')


另外, 在我们取并集的时候, 我们有时可能会想要知道, 某个数据是来自哪边, 可以通过 indicator 参数来获取:
df = pd.merge(df1, df2, on='city', how='outer', indicator=True)
输出:
在上面的例子中, 被合并的数据的列名是没有冲突的, 所以合并的很顺利, 那么如果两组数据有相同的列名, 又会是什么样呢? 看下面的例子:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando', 'baltimore'],
'temperature': [21, 24, 32, 29],
'humidity': [89, 79, 80, 69],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'san francisco'],
'temperature': [30, 32, 28],
'humidity': [80, 60, 70],
})
df = pd.merge(df1, df2, on='city')
输出:
我们发现, 相同的列名被自动加上了 'x', 'y' 作为区分, 为了更直观地观察数据, 我们也可以自定义这个区分的标志:
df3 = pd.merge(df1, df2, on='city', suffixes=['_left', '_right'])
输出:
好了, 以上, 就是关于 merge 合并的相关内容, enjoy~~~
Pandas 基础(9) - 组合方法 merge的更多相关文章
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
- Pandas 基础(1) - 初识及安装 yupyter
Hello, 大家好, 昨天说了我会再更新一个关于 Pandas 基础知识的教程, 这里就是啦......Pandas 被广泛应用于数据分析领域, 是一个很好的分析工具, 也是我们后面学习 machi ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
- python学习笔记(四):pandas基础
pandas 基础 serise import pandas as pd from pandas import Series, DataFrame obj = Series([4, -7, 5, 3] ...
随机推荐
- Java编程基础篇第四章
循环结构 循环结构的分类 for循环,while循环,do...while()循环 for循环 注意事项: a:判断条件语句无论简单还是复杂结果是boolean类型 b:循环体语句如果是一条语句,大括 ...
- JACKSON详解
Jackson 框架,轻易转换JSON Jackson可以轻松的将Java对象转换成json对象和xml文档,同样也可以将json.xml转换成Java对象. 前面有介绍过json-lib这个框架,在 ...
- 四则运算第三次 PSP
- 怎样把Word文档导入Excel表格
Word是现在办公中的基础文件格式了,很多的内容我们都通过Word来进行编辑,那么当我们需要将Word文档里的信息导入到Excel里面的时候,我们应该怎样做呢?下面我们就一起来看一下吧. 操作步骤: ...
- Linux命令 umask
umask: 文件预设权限 指定当前用户在创建文件或目录时的权限默认值. $ umask0002$ umask -Su=rwx,g=rwx,o=rx 创建文件时,预设没有x 权限,即只有rw 权限,最 ...
- web 容器
jboss简单使用(AS7): 将项目打成war包,放到jboss-as-web-7.0.0.Final\standalone\deployments下 访问 alias .name+port+war ...
- 01day
01 cpu 内存 硬盘 操作系统 CPU:中央处理器,相当于人大脑. (运行速度飞机) 内存:临时存储数据. 8g,16g, (高铁) 1,成本高. 2,断电即消 ...
- Gym 101873K - You Are Fired - [贪心水题]
题目链接:http://codeforces.com/gym/101873/problem/K 题意: 现在给出 $n(1 \le n \le 1e4)$ 个员工,最多可以裁员 $k$ 人,名字为 $ ...
- Unable to convert MySQL date/time value to System.DateTime问题解决方案
原因:可能是该字段(date/datetime)的值默认缺省值为:0000-00-00/0000-00-00 00:00:00,这样的数据读出来转换成System.DateTime时就会有问题: 解决 ...
- js 整数型数组和字符型数组相互转换
需求背景: 需要将 a = [1,2,3,4,5] 转换成 a = ['1','2','3','4','5'](整数型数组转换成字符型没找到直接的方法,思路就是先将数组转换成字符串,然后再将字符串转 ...