Pandas基础学习与Spark Python初探
1.Pandas是什么?
pandas是一个强大的Python数据分析工具包,是一个提供快速,灵活和表达性数据结构的python包,旨在使“关系”或“标记”数据变得简单直观。它旨在成为在Python中进行实用的真实世界数据分析的基本高级构建块。此外,它的更广泛的目标是成为最强大和最灵活的任何语言的开源数据分析/操作工具。
2.Pandas安装
这里使用pip包管理器安装(python版本为2.7.13)。在windows中,cmd进入python的安装路径下的Scripts目录,执行:
pip install pandas
即可安装pandas,安装完成后提示如下:
说明已成功安装pandas.这里同时安装了numpy等。
3.Pandas数据类型
pandas非常适合许多不同类型的数据:
- 具有非均匀类型列的表格数据,如在SQL表或Excel电子表格中
- 有序和无序(不一定是固定频率)时间序列数据。
- 带有行和列标签的任意矩阵数据(均匀类型或异质)
- 任何其他形式的观测/统计数据集。数据实际上不需要被标记就可以被放置到Pandas的数据结构中
4.Pandas基础
这里简单学习Pandas的基础,以命令模式为例,首先需要导入pandas包与numpy包,numpy这里主要使用其nan数据以及生成随机数:
import pandas as pd
import numpy as np
4.1 pandas之Series
通过传递值列表创建Series,让pandas创建一个默认整数索引:

4.2 pandas之DataFrame
通过传递numpy数组,使用datetime索引和标记的列来创建DataFrame:

查看DataFrame的头部和尾部数据:

显示索引,列和基础numpy数据:

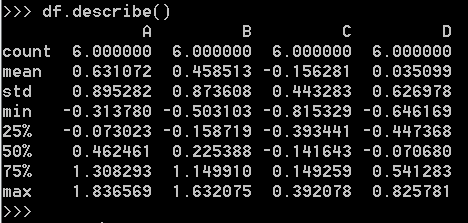
显示数据的快速统计摘要:
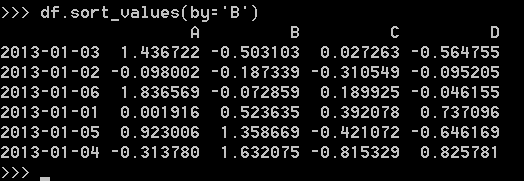
按值排序:
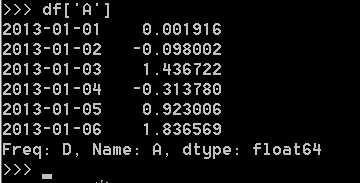
选择单个列,产生Series:
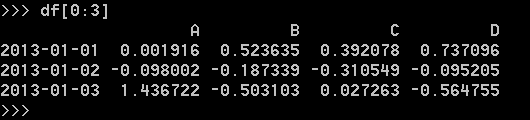
通过[]选择,通过切片选择行:
4.2.1 DataFrame读写csv文件
保存DataFrame数据到csv文件:

这里保存到c盘下,可以查看文件内容:
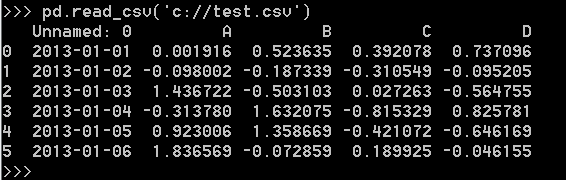
从csv文件读取数据:
4.2.2 DataFrame读写excel文件
保存数据到excel文件:

这里保存到c盘下,可以查看文件内容:
注:此处需要安装openpyxl,同pandas安装相同,pip install openpyxl.
从excel文件读取:
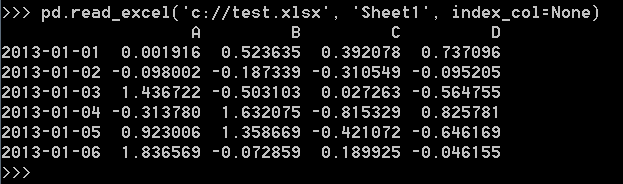
注:因为Excel需要单独的模块支持,所以需要安装xlrd,同pandas安装相同,pip install xlrd.
5.Pandas在Spark Python
这里测试读取一个已存在的parquet文件,目录为/data/parquet/20170901/,这里读取该目录下名字为part-r-00000开始的文件。将文件内容中的两列数据读取并保存到文件。代码如下:
#coding=utf-8 import sys
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.sql import SQLContext class ReadSpark(object):
def __init__(self, paramdate):
self.parquetroot = '/data/parquet/%s' # 这里是HDFS路径
self.thedate = paramdate
self.conf = SparkConf()
self.conf.set("spark.shuffle.memoryFraction", "0.5")
self.sc = SparkContext(appName='ReadSparkData', conf=self.conf)
self.sqlContext = SQLContext(self.sc) def getTypeData(self):
basepath = self.parquetroot % self.thedate
parqFile = self.sqlContext.read.option("mergeSchema", "true").option('basePath', basepath).parquet(
'%s/part-r-00000*' % (basepath))
resdata = parqFile.select('appId', 'os')
respd = resdata.toPandas()
respd.to_csv('/data/20170901.csv') #这里是Linux系统目录
print("--------------------data count:" + str(resdata.count())) if __name__ == "__main__":
reload(sys)
sys.setdefaultencoding('utf-8')
rs = ReadSpark('')
rs.getTypeData()
将代码命名为TestSparkPython.py,在集群提交,这里使用的命令为(参数信息与集群环境有关):
spark-submit --master yarn --driver-memory 6g --deploy-mode client --executor-memory 9g --executor-cores 3 --num-executors 50 /data/test/TestSparkPython.py
执行完成后,查看文件前五行内容,head -5 /data/20170901.csv:
总结:python编写spark程序还是非常方便的,pandas包在数据处理中的优势也很明显。在python越来越火的当下,值得深入学好python,就像python之禅写的那样……
Pandas基础学习与Spark Python初探的更多相关文章
- Python零基础学习系列之三--Python编辑器选择
上一篇文章记录了怎么安装Python环境,同时也成功的在电脑上安装好了Python环境,可以正式开始自己的编程之旅了.但是现在又有头疼的事情,该用什么来写Python程序呢,该用什么来执行Python ...
- Python基础学习笔记(一)python发展史与优缺点,岗位与薪资
相信有好多朋友们都是第一次了解python吧,可能大家也听过或接触过这个编程语言.那么到底什么是python呢?它在什么机缘巧合下诞生的呢?又为什么在短短十几年时间内就流行开来呢?就请大家带着疑问,让 ...
- pandas基础学习一
生成对象 用值列表生成 Series 时,Pandas 默认自动生成整数索引: In [3]: s = pd.Series([1, 3, 5, np.nan, 6, 8]) In [4]: s Out ...
- Python零基础学习系列之四--Python程序设计思想
前面我们把Python环境安装成功,同时也选择了自己合适的IDE工具来开启自己的编程之旅. 那么今天来说说怎么编程,程序设计需要什么步骤,我们应该怎么做才能编写自己的程序. 1-1.程序设计方法: I ...
- Pandas 基础学习
加载数据 Fun:pandas.read_csv >>> import pandas >>> food_info = pandas.read_csv("f ...
- numpy+pandas 基础学习
#-*- coding:utf-8 -*- import numpy as np; data1=[1,2,3,4,5] array1=np.array(data1) #创建数组/矩阵 # 使用nump ...
- pandas基础学习
1.导入两个数据分析重要的模块import numpy as npimport pandas as pd2.创建一个时间索引,所谓的索引(index)就是每一行数据的id,可以标识每一行的唯一值dat ...
- Python 读取UCI iris数据集分析、numpy基础学习
python基础.numpy使用.io读取数据集.数据处理转换与简单分析.读取UCI iris数据集中鸢尾花的萼片.花瓣长度数据,进行数据清理,去重,排序,并求出和.累积和.均值.标准差.方差.最大值 ...
- Python入门基础学习 三
Python入门基础学习 三 数据类型 Python区分整型和浮点型依靠的是小数点,有小数点就是浮点型. e记法:e就是10的意思,是一种科学的计数法,15000=1.5e4 布尔类型是一种特殊的整形 ...
随机推荐
- 首页音乐播放器添加"多首音乐"
添加音乐播放器可以去这个博主的网址参考学习 原文链接:http://www.cnblogs.com/RhinoC/p/4695509.html 以下是针对添加“多首音乐”的详细过程: (注:由于之前并 ...
- MD5加密Demo
package com.util; import java.security.MessageDigest; public class MD5 { public final static String ...
- Java大数据应用领域及就业方向
最难毕业季,2017高校毕业生达到795万,许多学生面临着毕业即失业的尴尬.面对着与日俱增的竞争形势和就业压力,很多毕业生选择去知了堂学习社区镀金,以提高自己的就业竞争力,其中Java大数据是学生选择 ...
- 用letsencrypt搭建免费的https网站
环境:阿里云服务器centos7.3,nignx,letsencrypt做免费的https证书 Let’s Encrypt官网:https://letsencrypt.org/ 1.服务器开放端口:4 ...
- 关于javascript在OJ系统上编程的注意事项
① 牛客网输入流: var line=readline().split(' '); ② 赛码网输入流: var line=read_line().split(' '); ③ 输出流: print(); ...
- 分享一个PHP文件上传类
该类用于处理文件上传,可以上传一个文件,也可以上传多个文件. 包括的成员属性有: private $path = "./uploads"; //上传文件保存的路径 private ...
- IEnumerable & IEnumerator
IEnumerable 只有一个方法:IEnumerator GetEnumerator(). INumerable 是集合应该实现的一个接口,这样,就能用 foreach 来遍历这个集合. IEnu ...
- npm的package.json字段含义中文文档
简介 本文档有所有package.json中必要的配置.它必须是真正的json,而不是js对象. 本文档中描述的很多行为都受npm-config(7)的影响. 默认值 npm会根据包内容设置一些默认值 ...
- 【整理】01. localhost_access_log 记录post请求参数
环境:apache-tomcat-7.0.57 利用Filter过去request请求参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ...
- 从 Vue 1.x 迁移 — Vue.js
闲聊: 又到周五啦,明天不用上班啦哈哈哈哈哈,想想就好开心啊,嘻嘻,小颖这周三的早晨做个一个美梦,把自己愣是笑醒了,梦的大概剧情我忘记了,总之宝宝是被笑醒的,行了之后还傻笑了一段时间,真希望每天早上都 ...