Pandas 基础(9) - 组合方法 merge
首先, 还是以天气为例, 准备如下数据:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando'],
'temperature': [21, 24, 32],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando'],
'humidity': [89, 79, 80],
})
df = pd.merge(df1, df2, on='city')
输出: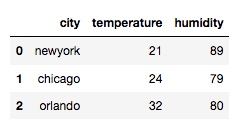
上面的例子就是以 'city' 为基准对两个 dataframe 进行合并, 但是两组数据都是高度一致, 下面调整一下:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando', 'baltimore'],
'temperature': [21, 24, 32, 29],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'san francisco'],
'humidity': [89, 79, 80],
})
df = pd.merge(df1, df2, on='city')
输出: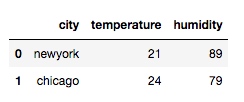
从输出我们看出, 通过 merge 合并, 会取两个数据的交集.
那么, 我们应该可以设想到, 可以通过调整参数, 来达到不同的取值范围.
取并集:
df = pd.merge(df1, df2, on='city', how='outer')
输出: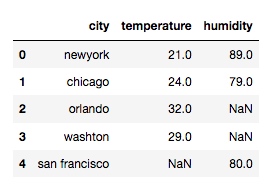
左对齐:
df = pd.merge(df1, df2, on='city', how='left')
输出:
右对齐:
df = pd.merge(df1, df2, on='city', how='right')


另外, 在我们取并集的时候, 我们有时可能会想要知道, 某个数据是来自哪边, 可以通过 indicator 参数来获取:
df = pd.merge(df1, df2, on='city', how='outer', indicator=True)
输出:
在上面的例子中, 被合并的数据的列名是没有冲突的, 所以合并的很顺利, 那么如果两组数据有相同的列名, 又会是什么样呢? 看下面的例子:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando', 'baltimore'],
'temperature': [21, 24, 32, 29],
'humidity': [89, 79, 80, 69],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'san francisco'],
'temperature': [30, 32, 28],
'humidity': [80, 60, 70],
})
df = pd.merge(df1, df2, on='city')
输出:
我们发现, 相同的列名被自动加上了 'x', 'y' 作为区分, 为了更直观地观察数据, 我们也可以自定义这个区分的标志:
df3 = pd.merge(df1, df2, on='city', suffixes=['_left', '_right'])
输出:
好了, 以上, 就是关于 merge 合并的相关内容, enjoy~~~
Pandas 基础(9) - 组合方法 merge的更多相关文章
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
- Pandas 基础(1) - 初识及安装 yupyter
Hello, 大家好, 昨天说了我会再更新一个关于 Pandas 基础知识的教程, 这里就是啦......Pandas 被广泛应用于数据分析领域, 是一个很好的分析工具, 也是我们后面学习 machi ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
- python学习笔记(四):pandas基础
pandas 基础 serise import pandas as pd from pandas import Series, DataFrame obj = Series([4, -7, 5, 3] ...
随机推荐
- js设计模式(二)---策略模式
策略模式: 定义: 定义一系列的算法,把他们一个个封装起来,并且是他们可以相互替换 应用场景: 要求实现某一个功能有多种方案可以选择.比如:条条大路通罗马 实现: 场景,绩效为 S的人年终奖有 4倍工 ...
- python——shopping car
# _Author:huang# date: 2017/11/26 # 简单的购物车程序money = input("money:") product_list = [ (&quo ...
- 线段树 || BZOJ1756: Vijos1083 小白逛公园 || P4513 小白逛公园
题面:小白逛公园 题解: 对于线段树的每个节点除了普通线段树该维护的东西以外,额外维护lsum(与左端点相连的最大连续区间和).rsum(同理)和sum……就行了 代码: #include<cs ...
- POJ 2689 - Prime Distance - [埃筛]
题目链接:http://poj.org/problem?id=2689 Time Limit: 1000MS Memory Limit: 65536K Description The branch o ...
- Web开发——HTML DOM基础
文档资料参考: 参考:HTML DOM 参考手册 参考:HTML DOM 教程 目录: 1.HTML DOM (文档对象模型) 2.查找 HTML 元素 2.1 通过 id 查找 HTML 元素 2. ...
- [daily][device][archlinux][trackpoint] 修改指点杆速度/敏捷度
修改指点杆速度,敏捷度: [root@T7 ~]# echo > /sys/devices/platform/i8042/serio1/serio2/sensitivity [root@T7 ~ ...
- spark-sql中的DataFrame文件格式转储示例
SparkConf sparkConf = new SparkConf() // .setMaster("local") .setAppName("DataFrameTe ...
- soapui调用redis,获取短信验证码
1.首先,调用redis需要引入redis的jar包,放入到soapui指定目录中,例如我的目录D:\Program Files\SmartBear\SoapUI-Pro-5.1.2\bin\ext ...
- 17.1-uC/OS-III消息管理(两种消息队列)
1.使用消息队列 消息队列函数: 函数名 功能 OSQCreate() 创建一个消息队列 OSQDel() 删除一个消息队列 OSQFlush() 清空一个消息队列 OSQPend() 任务等待消息 ...
- 15.1-uC/OS-III资源管理(锁调度器)
1.大部分独占资源的方法都是创建临界段:1) 关中断方式2) 锁调度器方式3) 信号量方式4) mutex方式 2.独占共享资源的最快和最简单方法是关中断 然而,关/开中断是和CPU相关的操作,其相关 ...