Apache Spark是什么?
简单地说,
Spark是发源于美国加州大学伯克利分校AMPLab的大数据分析平台,它立足于内存计算,从多迭代批量处理出发,兼顾数据仓库、 流处理和图计算等多种计算范式,是大数据系
统领域的全栈计算平台。
Spark是基于内存计算的大数据并行计算框架。 Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
更准确地说,Spark是一个计算框架,而Hadoop中包含计算框架MapReduce和分布式文件系统HDFS,Hadoop更广泛地说还包括在其生态系统上的其他系统,如Hbase、 Hive等。Spark是MapReduce的替代方案,而且兼容HDFS、 Hive等分布式存储层,可融入Hadoop的生态系统,以弥补缺失MapReduce的不足。
进一步地说,
Spark是整个BDAS的核心组件,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map函数和reduce函数及计算模型,还提供更为丰富的算子,如filter、join、groupByKey等。详细见 http://www.cnblogs.com/zlslch/p/5723857.html
Spark将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。其底层采用Scala这种函数式语言书写而成,并且所提供的API深度借鉴Scala函数式的编程思想,提供与Scala类似的编程接口。
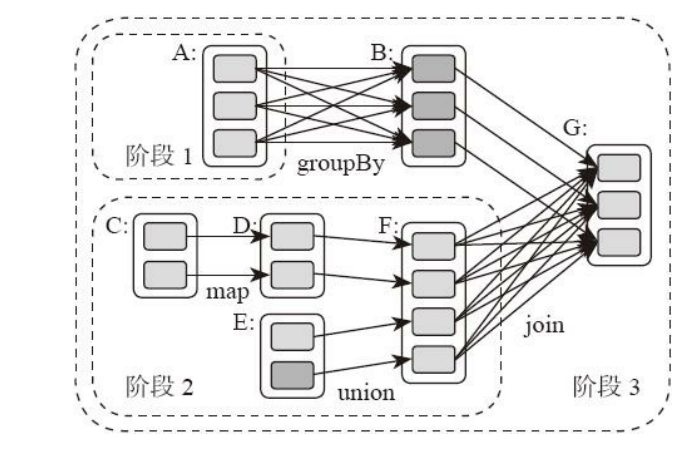
图1 Spark的任务处理流程图
Spark将数据在分布式环境下分区,然后将作业转化为有向无环图(DAG),并分阶段进行DAG的调度和任务的分布式并行处理。
科普Spark,Spark核心是什么,如何使用Spark(2)
Apache Spark是什么?的更多相关文章
- Apache Spark简单介绍、安装及使用
Apache Spark简介 Apache Spark是一个高速的通用型计算引擎,用来实现分布式的大规模数据的处理任务. 分布式的处理方式可以使以前单台计算机面对大规模数据时处理不了的情况成为可能. ...
- 关于Apache Spark
Apache Spark : https://www.oschina.net/p/spark-project
- Apache Spark源码剖析
Apache Spark源码剖析(全面系统介绍Spark源码,提供分析源码的实用技巧和合理的阅读顺序,充分了解Spark的设计思想和运行机理) 许鹏 著 ISBN 978-7-121-25420- ...
- [翻译]Apache Spark入门简介
原文地址:http://blog.jobbole.com/?p=89446 我是在2013年底第一次听说Spark,当时我对Scala很感兴趣,而Spark就是使用Scala编写的.一段时间之后,我做 ...
- Apache Spark技术实战之9 -- 日志级别修改
摘要 在学习使用Spark的过程中,总是想对内部运行过程作深入的了解,其中DEBUG和TRACE级别的日志可以为我们提供详细和有用的信息,那么如何进行合理设置呢,不复杂但也绝不是将一个INFO换为TR ...
- Apache Spark技术实战之8:Standalone部署模式下的临时文件清理
未经本人同意严禁转载,徽沪一郎. 概要 在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件,这些临时目录和文件又是在什么时候被清理,本文将就这些问题做深入细致的解答. 从 ...
- ERROR actor.OneForOneStrategy: org.apache.spark.SparkContext
今天在用Spark把Kafka的数据往ES写的时候,代码一直报错,错误信息如下: 15/10/20 17:28:56 ERROR actor.OneForOneStrategy: org.apache ...
- Apache Spark技术实战之6 -- spark-submit常见问题及其解决
除本人同意外,严禁一切转载,徽沪一郎. 概要 编写了独立运行的Spark Application之后,需要将其提交到Spark Cluster中运行,一般会采用spark-submit来进行应用的提交 ...
- Apache Spark源码走读之24 -- Sort-based Shuffle的设计与实现
欢迎转载,转载请注明出处. 概要 Spark 1.1中对spark core的一个重大改进就是引入了sort-based shuffle处理机制,本文就该处理机制的实现进行初步的分析. Sort-ba ...
- Apache Spark技术实战之4 -- 利用Spark将json文件导入Cassandra
欢迎转载,转载请注明出处. 概要 本文简要介绍如何使用spark-cassandra-connector将json文件导入到cassandra数据库,这是一个使用spark的综合性示例. 前提条件 假 ...
随机推荐
- MongoDB 学习笔记(三) MongoDB (replica set) 集群配置
MongoDB Replica Sets的结构类似于以集群,完全可以把他当成一个集群,因为他确实与集群实现的作用是一样的:如果其中一个节点出现故障,其他的节点会马上将业务接管过来.而无需停机操作 Mo ...
- jquery来跨域提交表单
说说用jquery来实现跨域提交表单 在jQuery中,我们使用json数据类型,通过getJSON方法来实现从服务端获取或发送数据,而当要向不同远程服务器端提交或者获取数据时,要采用jsonp数据类 ...
- c#中获取服务器IP,客户端IP以及Request.ServerVariables详细说明
客户端ip: Request.ServerVariables.Get("Remote_Addr").ToString(); 客户端主机名: Request.ServerVaria ...
- ui/ue设计师应该了解的原型设计软件
前段实践整理过一些原型设计用的软件,这里分享一下,喜欢对更多的PM战线的童鞋有所裨益.(因为交互原型工具Axure ui设计师都很常用了,文中就不专门介绍了) 首先分下类: •1.交互原型(产品能做什 ...
- BZOJ 1827 奶牛大集会
树型DP. #include<iostream> #include<cstdio> #include<cstring> #include<algorithm& ...
- HDU 1496 Equations 等式(二分+暴力,技巧)
题意:给出4个数字a,b,c,d,求出满足算式a*x1^2+b*x2^2+c*x3^2+d*x4^2=0的 (x1,x2,x3,x4) 的组合数.x的范围[-100,100],四个数字的范围 [-50 ...
- 【英语】Bingo口语笔记(10) - 常见词汇的缩读
- QR二维码(转)
二维码又称QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar Code条形码能存更多的信息,也能表示更多的数据类型:比如:字符,数字, ...
- [转] gc tips(3)
原文地址:http://kevincao.com/2011/08/actionscript-garbage-collection-2/ 谈谈ActionScript垃圾回收(下) 前文我们介绍了GC的 ...
- Android总结篇——Intent机制详解及示例总结
最近在进行android开发过程中,在将 Intent传递给调用的组件并完成组件的调用时遇到点困难,并且之前对Intent的学习也是一知半解,最近特意为此拿出一些时间,对Intent部分进行 ...