sklearn中模型抽取
特征抽取sklearn.feature_extraction 模块提供了从原始数据如文本,图像等众抽取能够被机器学习算法直接处理的特征向量。

1.特征抽取方法之 Loading Features from Dicts



measurements=[
{'city':'Dubai','temperature':33.},
{'city':'London','temperature':12.},
{'city':'San Fransisco','temperature':18.},
] from sklearn.feature_extraction import DictVectorizer
vec=DictVectorizer()
print(vec.fit_transform(measurements).toarray())
print(vec.get_feature_names()) #[[ 1. 0. 0. 33.]
#[ 0. 1. 0. 12.]
#[ 0. 0. 1. 18.]] #['city=Dubai', 'city=London', 'city=San Fransisco', 'temperature']
2.特征抽取方法之 Features hashing



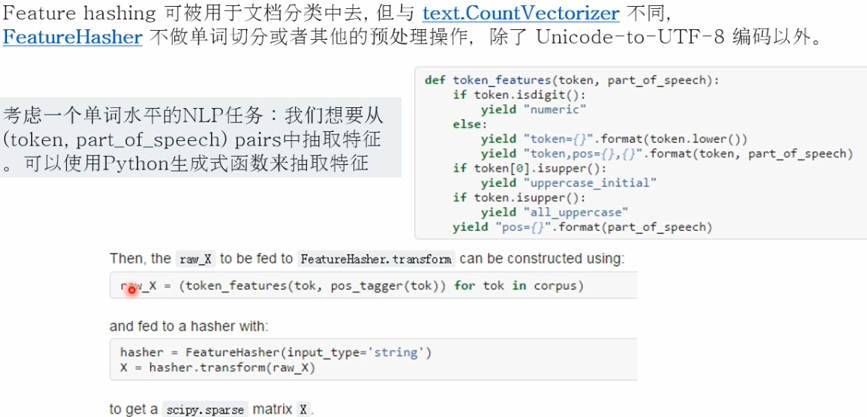
3.特征抽取方法之 Text Feature Extraction
词袋模型 the bag of words represenatation



#词袋模型
from sklearn.feature_extraction.text import CountVectorizer
#查看默认的参数
vectorizer=CountVectorizer(min_df=1)
print(vectorizer) """
CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None) """ corpus=["this is the first document.",
"this is the second second document.",
"and the third one.",
"Is this the first document?"]
x=vectorizer.fit_transform(corpus)
print(x) """
(0, 1) 1
(0, 2) 1
(0, 6) 1
(0, 3) 1
(0, 8) 1
(1, 5) 2
(1, 1) 1
(1, 6) 1
(1, 3) 1
(1, 8) 1
(2, 4) 1
(2, 7) 1
(2, 0) 1
(2, 6) 1
(3, 1) 1
(3, 2) 1
(3, 6) 1
(3, 3) 1
(3, 8) 1
"""
默认是可以识别的字符串至少为2个字符
analyze=vectorizer.build_analyzer()
print(analyze("this is a document to anzlyze.")==
(["this","is","document","to","anzlyze"])) #True
在fit阶段被analyser发现的每一个词语都会被分配一个独特的整形索引,该索引对应于特征向量矩阵中的一列
print(vectorizer.get_feature_names()==(
["and","document","first","is","one","second","the","third","this"]
))
#True
print(x.toarray())
"""
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 2 1 0 1]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]
"""
获取属性
print(vectorizer.vocabulary_.get('document'))
#1
对于一些没有出现过的字或者字符,则会显示为0
vectorizer.transform(["somthing completely new."]).toarray()
"""
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 2 1 0 1]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]
"""
在上边的语料库中,第一个和最后一个单词是一模一样的,只是顺序不一样,他们会被编码成相同的特征向量,所以词袋表示法会丢失了单词顺序的前后相关性信息,为了保持某些局部的顺序性,可以抽取2个词和一个词
bigram_vectorizer=CountVectorizer(ngram_range=(1,2),token_pattern=r"\b\w+\b",min_df=1)
analyze=bigram_vectorizer.build_analyzer()
print(analyze("Bi-grams are cool!")==(['Bi','grams','are','cool','Bi grams',
'grams are','are cool'])) #True
x_2=bigram_vectorizer.fit_transform(corpus).toarray()
print(x_2) """
[[0 0 1 1 1 1 1 0 0 0 0 0 1 1 0 0 0 0 1 1 0]
[0 0 1 0 0 1 1 0 0 2 1 1 1 0 1 0 0 0 1 1 0]
[1 1 0 0 0 0 0 0 1 0 0 0 1 0 0 1 1 1 0 0 0]
[0 0 1 1 1 1 0 1 0 0 0 0 1 1 0 0 0 0 1 0 1]]
"""
sklearn中模型抽取的更多相关文章
- sklearn 中模型保存的两种方法
一. sklearn中提供了高效的模型持久化模块joblib,将模型保存至硬盘. from sklearn.externals import joblib #lr是一个LogisticRegressi ...
- sklearn中模型评估和预测
一.模型验证方法如下: 通过交叉验证得分:model_sleection.cross_val_score(estimator,X) 对每个输入数据点产生交叉验证估计:model_selection.c ...
- sklearn保存模型的两种方式
sklearn 中模型保存的两种方法 一. sklearn中提供了高效的模型持久化模块joblib,将模型保存至硬盘. from sklearn.externals import joblib # ...
- 第十三次作业——回归模型与房价预测&第十一次作业——sklearn中朴素贝叶斯模型及其应用&第七次作业——numpy统计分布显示
第十三次作业——回归模型与房价预测 1. 导入boston房价数据集 2. 一元线性回归模型,建立一个变量与房价之间的预测模型,并图形化显示. 3. 多元线性回归模型,建立13个变量与房价之间的预测模 ...
- sklearn中的模型评估-构建评估函数
1.介绍 有三种不同的方法来评估一个模型的预测质量: estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题. Scor ...
- sklearn中的KMeans算法
1.聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇).这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布. 2.KMeans算法将一 ...
- 机器学习实战基础(二十四):sklearn中的降维算法PCA和SVD(五) PCA与SVD 之 重要接口inverse_transform
重要接口inverse_transform 在上周的特征工程课中,我们学到了神奇的接口inverse_transform,可以将我们归一化,标准化,甚至做过哑变量的特征矩阵还原回原始数据中的特征矩阵 ...
- Python 3 利用 Dlib 19.7 和 sklearn机器学习模型 实现人脸微笑检测
0.引言 利用机器学习的方法训练微笑检测模型,给一张人脸照片,判断是否微笑: 使用的数据集中69张没笑脸,65张有笑脸,训练结果识别精度在95%附近: 效果: 图1 示例效果 工程利用pytho ...
- sklearn中的Pipeline
在将sklearn中的模型持久化时,使用sklearn.pipeline.Pipeline(steps, memory=None)将各个步骤串联起来可以很方便地保存模型. 例如,首先对数据进行了PCA ...
随机推荐
- C++中调用OC代码
前言 最近项目中为了方便维护,底层统一使用C++编写.由于是项目是做屏幕共享sdk,所以只能底层的压缩.编解码使用C++,屏幕捕获部分Mac和win就自己实现了.那么问题就来了,因为是面向接口编程,所 ...
- requests_html爬虫小练习
爬取豆瓣TOP250 from requests_html import HTMLSession #新建一个html文件,将相应的代码放入,运行查看结果,如果页面全部渲染则直接根据页面信息获得数据: ...
- jdk8处理时间
对当前时间格式化: public static long getCurrentTimeMillis(String pattern) { return Long.valueOf(toString(Loc ...
- npm和cnpm的安装(window)
一:安装node.js 1.进入https://nodejs.org/en/中下载自己电脑相对应的node.js. 2.将下载下来的node.js进行安装. 3.利用管理员身份打开cmd,在里面输入n ...
- socket API CSocket CAsyncSocket 用法及区别
要进行网络编程就要和Socket打交道,Socket有同步阻塞方式和异步非阻塞方式两种使用,事实上同步和异步在我们编程的生涯中可能遇到了很多,而Socket也没什么特别.虽然同步好用,不费劲,但不能满 ...
- python:异常处理及程序调试
1.异常概述 在程序运行过程中,经常会遇到各种各样的错误.这些错误统称为“异常”,在这些一场中有的是由于开发者将关键词写错导致,这类错误产生的是SyntaxError.invalid syntax(无 ...
- 《深入理解Java虚拟机》-(实战)boolean类型在虚拟机中是如何处理的
这里先引出Java的8大基本类型.直接上图吧. 可以看到,除了boolean和char类型之外,越往下的类型的值域是包含以上的值域的.因此,从上面的基本类型转换成下面的基本类型,无需强制转换.关于它们 ...
- Flatty Shadow图标自动产生器——在线生成各种扁平化 ICON
在扁平化风格越来越流行的今天,网页.软件界面和图标的设计大都采用了扁平化风格.特别是扁平化图标的设计,摒弃了一切3D元素的设计,阴影.纹理.透视神马的统统不要,让图标简洁高效,富有现代感. 今天给大家 ...
- 笔记49 在Spittr应用中整合Hibernate
在前边构建的Spittr应用中整合Hibernate 由于最近所学的hibernate都是使用xml方式进行配置的,所以在与以Java方式配置的Spittr应用结合时就会出现一些小问题,在此进行总结. ...
- table 表头不动,tbody滚动对齐
http://www.imaputz.com/cssStuff/bigFourVersion.html# https://blog.csdn.net/yiifaa/article/details/52 ...