Spring Cloud 5大组件
服务发现——Netflix Eureka
客服端负载均衡——Netflix Ribbon
断路器——Netflix Hystrix
服务网关——Netflix Zuul
分布式配置——Spring Cloud Config
一、业务场景介绍
先来给大家说一个业务场景,假设咱们现在开发一个电商网站,要实现支付订单的功能,流程如下:
创建一个订单之后,如果用户立刻支付了这个订单,我们需要将订单状态更新为“已支付”
扣减相应的商品库存
通知仓储中心,进行发货
给用户的这次购物增加相应的积分
针对上述流程,我们需要有订单服务、库存服务、仓储服务、积分服务。整个流程的大体思路如下:
用户针对一个订单完成支付之后,就会去找订单服务,更新订单状态
订单服务调用库存服务,完成相应功能
订单服务调用仓储服务,完成相应功能
订单服务调用积分服务,完成相应功能
至此,整个支付订单的业务流程结束
下图这张图,清晰表明了各服务间的调用过程
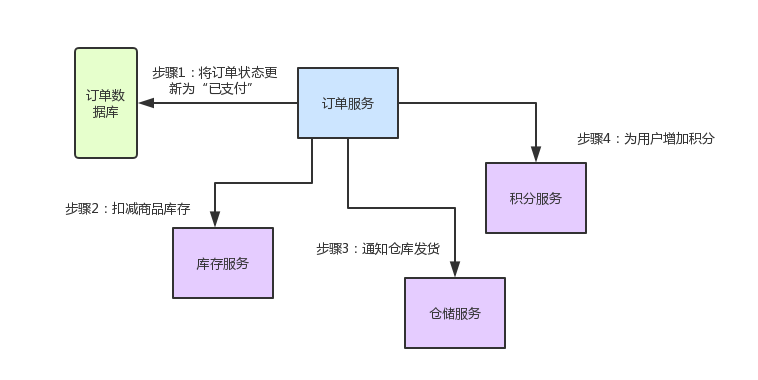
好!有了业务场景之后,咱们就一起来看看Spring Cloud微服务架构中,这几个组件如何相互协作,各自发挥的作用以及其背后的原理。
二、Spring Cloud核心组件:Eureka
咱们来考虑第一个问题:订单服务想要调用库存服务、仓储服务,或者是积分服务,怎么调用?
订单服务压根儿就不知道人家库存服务在哪台机器上啊!他就算想要发起一个请求,都不知道发送给谁,有心无力!
这时候,就轮到Spring Cloud Eureka出场了。Eureka是微服务架构中的注册中心,专门负责服务的注册与发现。
咱们来看看下面的这张图,结合图来仔细剖析一下整个流程:
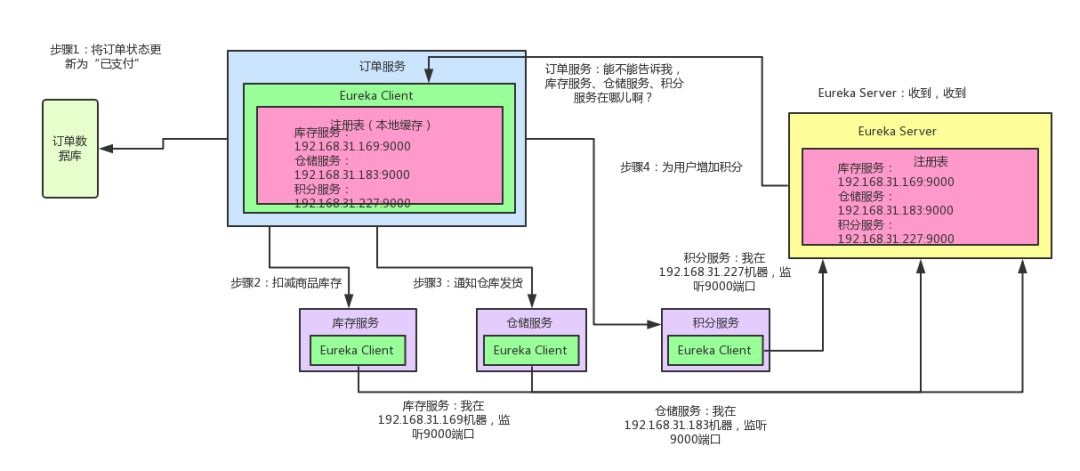
如上图所示,库存服务、仓储服务、积分服务中都有一个Eureka Client组件,这个组件专门负责将这个服务的信息注册到Eureka Server中。说白了,就是告诉Eureka Server,自己在哪台机器上,监听着哪个端口。而Eureka Server是一个注册中心,里面有一个注册表,保存了各服务所在的机器和端口号
订单服务里也有一个Eureka Client组件,这个Eureka Client组件会找Eureka Server问一下:库存服务在哪台机器啊?监听着哪个端口啊?仓储服务呢?积分服务呢?然后就可以把这些相关信息从Eureka Server的注册表中拉取到自己本地缓存起来。
这时如果订单服务想要调用库存服务,不就可以找自己本地的Eureka Client问一下库存服务在哪台机器?监听哪个端口吗?收到响应后,紧接着就可以发送一个请求过去,调用库存服务扣减库存的那个接口!同理,如果订单服务要调用仓储服务、积分服务,也是如法炮制。
总结一下:
Eureka Client:负责将这个服务的信息注册到Eureka Server中
Eureka Server:注册中心,里面有一个注册表,保存了各个服务所在的机器和端口号
三、Spring Cloud核心组件:Feign
现在订单服务确实知道库存服务、积分服务、仓库服务在哪里了,同时也监听着哪些端口号了。但是新问题又来了:难道订单服务要自己写一大堆代码,跟其他服务建立网络连接,然后构造一个复杂的请求,接着发送请求过去,最后对返回的响应结果再写一大堆代码来处理吗?
这是上述流程翻译的代码片段,咱们一起来看看,体会一下这种绝望而无助的感受!!!
友情提示,前方高能:
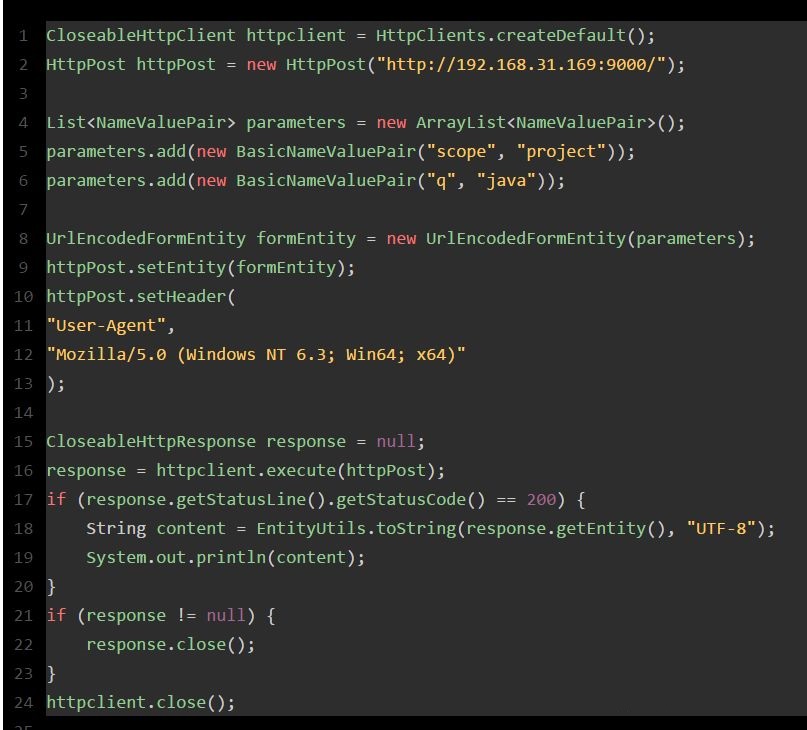
看完上面那一大段代码,有没有感到后背发凉、一身冷汗?实际上你进行服务间调用时,如果每次都手写代码,代码量比上面那段要多至少几倍,所以这个事儿压根儿就不是地球人能干的。
既然如此,那怎么办呢?别急,Feign早已为我们提供好了优雅的解决方案。来看看如果用Feign的话,你的订单服务调用库存服务的代码会变成啥样?
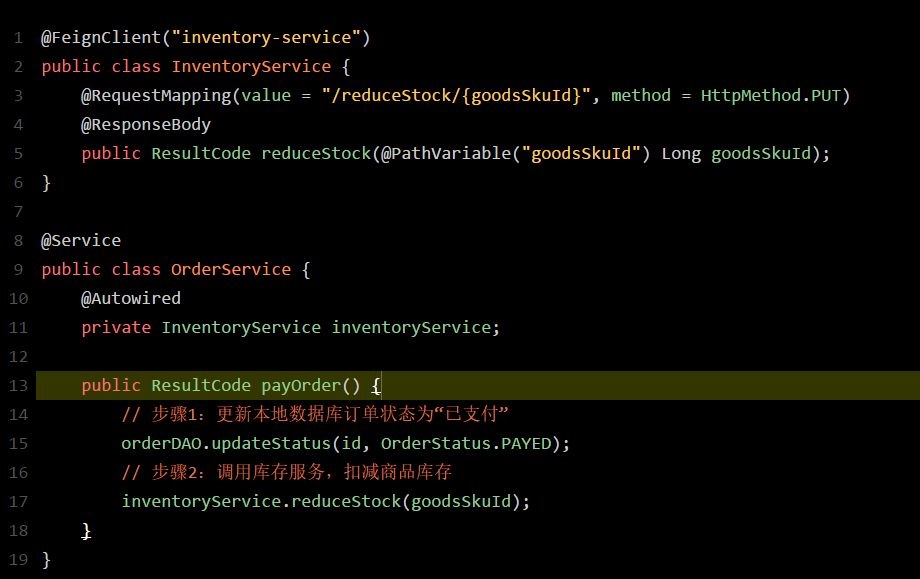
看完上面的代码什么感觉?是不是感觉整个世界都干净了,又找到了活下去的勇气!没有底层的建立连接、构造请求、解析响应的代码,直接就是用注解定义一个 FeignClient接口,然后调用那个接口就可以了。人家Feign Client会在底层根据你的注解,跟你指定的服务建立连接、构造请求、发起靕求、获取响应、解析响应,等等。这一系列脏活累活,人家Feign全给你干了。
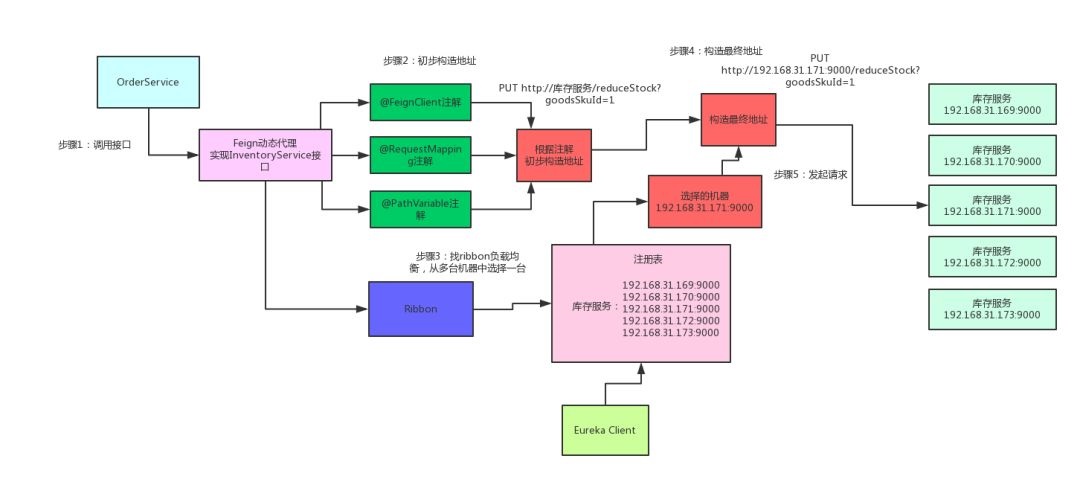
那么问题来了,Feign是如何做到这么神奇的呢?很简单,Feign的一个关键机制就是使用了动态代理。咱们一起来看看下面的图,结合图来分析:
首先,如果你对某个接口定义了@FeignClient注解,Feign就会针对这个接口创建一个动态代理
接着你要是调用那个接口,本质就是会调用 Feign创建的动态代理,这是核心中的核心
Feign的动态代理会根据你在接口上的@RequestMapping等注解,来动态构造出你要请求的服务的地址
最后针对这个地址,发起请求、解析响应

四、Spring Cloud核心组件:Ribbon
说完了Feign,还没完。现在新的问题又来了,如果人家库存服务部署在了5台机器上,如下所示:
192.168.169:9000
192.168.170:9000
192.168.171:9000
192.168.172:9000
192.168.173:9000
这下麻烦了!人家Feign怎么知道该请求哪台机器呢?
这时Spring Cloud Ribbon就派上用场了。Ribbon就是专门解决这个问题的。它的作用是负载均衡,会帮你在每次请求时选择一台机器,均匀的把请求分发到各个机器上
Ribbon的负载均衡默认使用的最经典的Round Robin轮询算法。这是啥?简单来说,就是如果订单服务对库存服务发起10次请求,那就先让你请求第1台机器、然后是第2台机器、第3台机器、第4台机器、第5台机器,接着再来—个循环,第1台机器、第2台机器。。。以此类推。
此外,Ribbon是和Feign以及Eureka紧密协作,完成工作的,具体如下:
首先Ribbon会从 Eureka Client里获取到对应的服务注册表,也就知道了所有的服务都部署在了哪些机器上,在监听哪些端口号。
然后Ribbon就可以使用默认的Round Robin算法,从中选择一台机器
Feign就会针对这台机器,构造并发起请求。
对上述整个过程,再来一张图,帮助大家更深刻的理解:
五、Spring Cloud核心组件:Hystrix
在微服务架构里,一个系统会有很多的服务。以本文的业务场景为例:订单服务在一个业务流程里需要调用三个服务。现在假设订单服务自己最多只有100个线程可以处理请求,然后呢,积分服务不幸的挂了,每次订单服务调用积分服务的时候,都会卡住几秒钟,然后抛出—个超时异常。
咱们一起来分析一下,这样会导致什么问题?
如果系统处于高并发的场景下,大量请求涌过来的时候,订单服务的100个线程都会卡在请求积分服务这块。导致订单服务没有一个线程可以处理请求
然后就会导致别人请求订单服务的时候,发现订单服务也挂了,不响应任何请求了
上面这个,就是微服务架构中恐怖的服务雪崩问题,如下图所示:
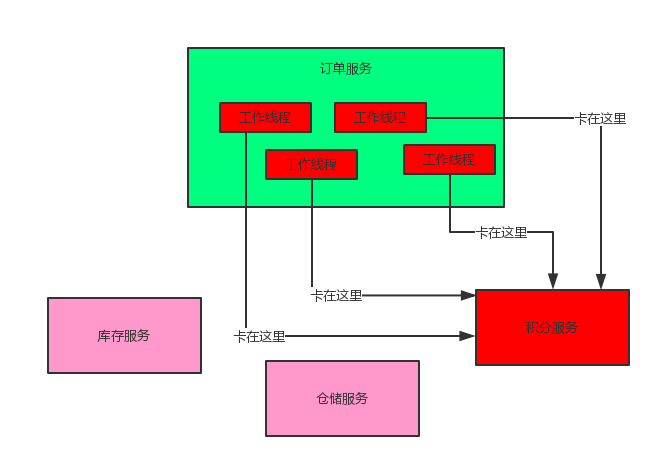
如上图,这么多服务互相调用,要是不做任何保护的话,某一个服务挂了,就会引起连锁反应,导致别的服务也挂。比如积分服务挂了,会导致订单服务的线程全部卡在请求积分服务这里,没有一个线程可以工作,瞬间导致订单服务也挂了,别人请求订单服务全部会卡住,无法响应。
但是我们思考一下,就算积分服务挂了,订单服务也可以不用挂啊!为什么?
我们结合业务来看:支付订单的时候,只要把库存扣减了,然后通知仓库发货就OK了
如果积分服务挂了,大不了等他恢复之后,慢慢人肉手工恢复数据!为啥一定要因为一个积分服务挂了,就直接导致订单服务也挂了呢?不可以接受!
现在问题分析完了,如何解决?
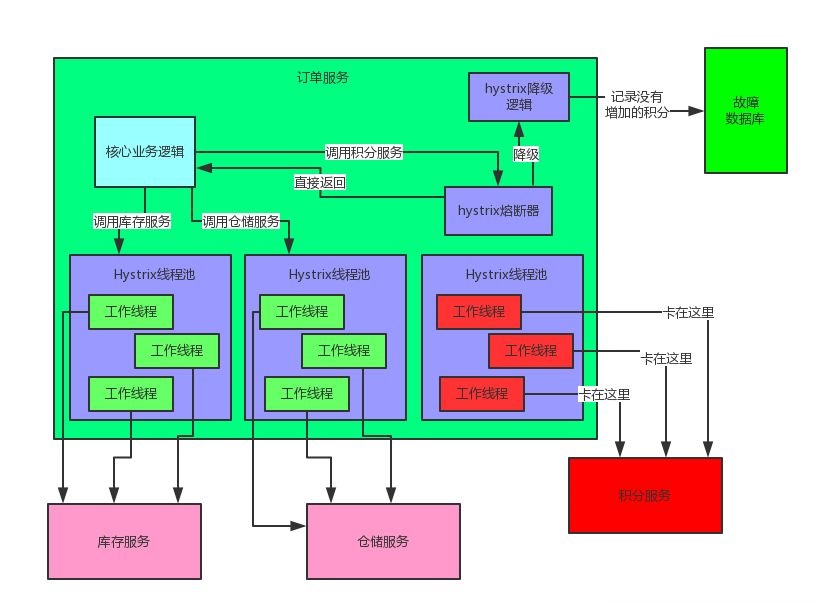
这时就轮到Hystrix闪亮登场了。Hystrix是隔离、熔断以及降级的一个框架。啥意思呢?说白了,Hystrix会搞很多个小小的线程池,比如订单服务请求库存服务是一个线程池,请求仓储服务是一个线程池,请求积分服务是一个线程池。每个线程池里的线程就仅仅用于请求那个服务。
打个比方:现在很不幸,积分服务挂了,会咋样?
当然会导致订单服务里的那个用来调用积分服务的线程都卡死不能工作了啊!但是由于订单服务调用库存服务、仓储服务的这两个线程池都是正常工作的,所以这两个服务不会受到任何影响。
这个时候如果别人请求订单服务,订单服务还是可以正常调用库存服务扣减库存,调用仓储服务通知发货。只不过调用积分服务的时候,每次都会报错。但是如果积分服务都挂了,每次调用都要去卡住几秒钟干啥呢?有意义吗?当然没有!所以我们直接对积分服务熔断不就得了,比如在5分钟内请求积分服务直接就返回了,不要去走网络请求卡住几秒钟,这个过程,就是所谓的熔断!
那人家又说,兄弟,积分服务挂了你就熔断,好歹你干点儿什么啊!别啥都不干就直接返回啊?没问题,咱们就来个降级:每次调用积分服务,你就在数据库里记录一条消息,说给某某用户增加了多少积分,因为积分服务挂了,导致没增加成功!这样等积分服务恢复了,你可以根据这些记录手工加一下积分。这个过程,就是所谓的降级。
为帮助大家更直观的理解,接下来用一张图,梳理一下Hystrix隔离、熔断和降级的全流程:
六、Spring Cloud核心组件:Zuul
说完了Hystrix,接着给大家说说最后一个组件:Zuul,也就是微服务网关。这个组件是负责网络路由的。不懂网络路由?行,那我给你说说,如果没有Zuul的日常工作会怎样?
假设你后台部署了几百个服务,现在有个前端兄弟,人家请求是直接从浏览器那儿发过来的。打个比方:人家要请求一下库存服务,你难道还让人家记着这服务的名字叫做inventory-service?部署在5台机器上?就算人家肯记住这一个,你后台可有几百个服务的名称和地址呢?难不成人家请求一个,就得记住一个?你要这样玩儿,那真是友谊的小船,说翻就翻!
上面这种情况,压根儿是不现实的。所以一般微服务架构中都必然会设计一个网关在里面,像android、ios、pc前端、微信小程序、H5等等,不用去关心后端有几百个服务,就知道有一个网关,所有请求都往网关走,网关会根据请求中的一些特征,将请求转发给后端的各个服务。
而且有一个网关之后,还有很多好处,比如可以做统一的降级、限流、认证授权、安全,等等。
总结:
最后再来总结一下,上述几个Spring Cloud核心组件,在微服务架构中,分别扮演的角色:
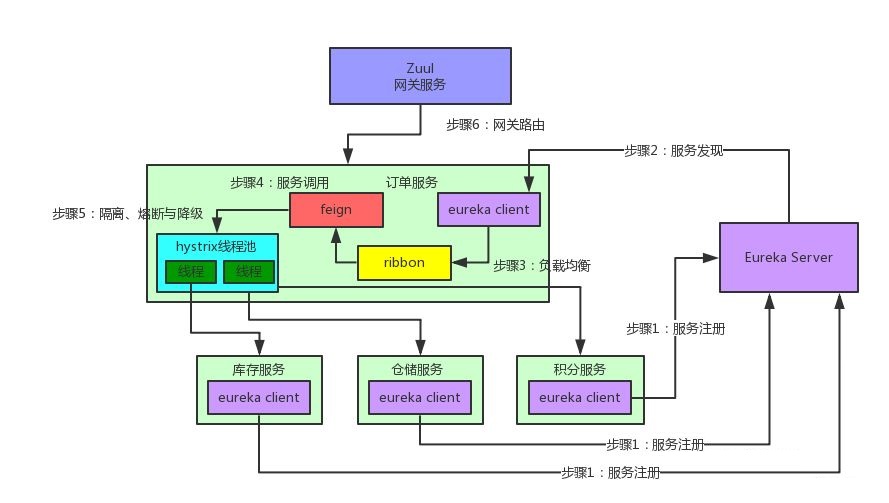
Eureka:各个服务启动时,Eureka Client都会将服务注册到Eureka Server,并且Eureka Client还可以反过来从Eureka Server拉取注册表,从而知道其他服务在哪里
Ribbon:服务间发起请求的时候,基于Ribbon做负载均衡,从一个服务的多台机器中选择一台
Feign:基于Feign的动态代理机制,根据注解和选择的机器,拼接请求URL地址,发起请求
Hystrix:发起请求是通过Hystrix的线程池来走的,不同的服务走不同的线程池,实现了不同服务调用的隔离,避免了服务雪崩的问题
Zuul:如果前端、移动端要调用后端系统,统一从Zuul网关进入,由Zuul网关转发请求给对应的服务
以上就是我们通过一个电商业务场景,阐述了Spring Cloud微服务架构几个核心组件的底层原理。
文字总结还不够直观?没问题!我们将Spring Cloud的5个核心组件通过一张图串联起来,再来直观的感受一下其底层的架构原理:
Spring Cloud 5大组件的更多相关文章
- Spring cloud的各类组件
Spring cloud 的各类组件 1.注册中心 eureka 2.ribbon 3.feign 4.hystirx 断路器 5.高速缓存器 redis 6.断路器Dashboard监控仪表盘
- spring cloud链路追踪组件sleuth和zipkin
spring cloud链路追踪组件sleuth 主要作用就是日志埋点 操作方法 1.增加依赖 <dependency> <groupId& ...
- Spring Boot版本,Spring Cloud版本与组件版本关系
我们在学习Spring Cloud时,可能总是碰到以下问题: 1.Spring Boot版本与Spring Cloud版本关系 2.启动时,报莫名其妙的错,稀里糊涂的换个版本就好了 3.这么多版本,用 ...
- 一句话概括下spring框架及spring cloud框架主要组件
作为java的屌丝,基本上跟上spring屌丝的步伐,也就跟上了主流技术.spring 顶级项目:Spring IO platform:用于系统部署,是可集成的,构建现代化应用的版本平台,具体来说当你 ...
- 孰优孰劣?Dubbo VS Spring Cloud性能测试大对决!
最近我们试图从Dubbo迁移到Spring Cloud.为此对二者分别进行了性能测试.为了得出数据量不同的情况下的二者的性能表现,我们分别准备了一个25个属性pojo对象和一个50个属性的pojo对象 ...
- Spring Cloud的常规组件和简单实战(一)
最近一段时间在学习Spring Cloud,从Eureka到Hystrix,常用的配置和方法都有涉及一些,以此笔记来记录一下学习到的东西,也分享一下.内容以实战为起点,主要以介绍常规用法为主,最后也会 ...
- Spring Cloud ----> 几个组件的总结
Spring Cloud Eureka 多个服务,对应多个Eureka Client 只有一个Eureka Server ,充当注册中心的角色每个Eureka Client 有ip 地址和端口号,它们 ...
- 【问题】:spring cloud sleuth日志组件冲突问题
在使用spring cloud sleuth的时候,启动工程报错如下: 根据错误信息明显就是jar包冲突,spring boot默认用的是logback,所以移除其中一个依赖就可以了,修改pom依赖为 ...
- spring cloud Alibaba --sentinel组件的使用
sentinel组件 对于sentinel的前置知识这里就不多说了: 直接上代码: Release v1.8.1 · alibaba/Sentinel · GitHub 下载地址 springclo ...
随机推荐
- shell脚本 定期删除日志
定期删除日志: 然后建立清除日志文件的shell脚本,文件名为clean_log只保留最近三天的日志 #! /bin/bashlogdir=/var/log/httpdcd ${logdir} ...
- [jQuery]jQuery链式编程(六)
链式编程 节约代码量 <button>快速</button> <button>快速</button> <button>快速</butt ...
- 【转载】wav文件格式分析与详解
WAV文件是在PC机平台上很常见的.最经典的多媒体音频文件,最早于1991年8月出现在Windows 3.1操作系统上,文件扩展名为WAV,是WaveFom的简写,也称为波形文件,可直接存储声音波形, ...
- 珠峰-vue
- 十天学会CS之操作系统——进程管理01
进程管理01 进程的概念 进程是计算机中一个非常重要的概念,在整个计算机发展历史中,操作系统中程序运行机制的演变按顺序大致可以分为: 单道程序:通常是指每一次将一个或者一批程序(一个作业)从磁盘加载进 ...
- 《自拍教程29》Sublime_小脚本编写首选
Sublime Sublime 是一个轻量.简洁.高效.跨平台的编辑器, 最新的是Sublime Text 3. Sublime对Python支持非常好,如果只是简单的编写批处理脚本编写, 或者小范围 ...
- 手动发布本地jar包到Nexus私服
1.Nexus配置 1. 在Nexus私服上建立仓库,用于盛放jar包,如名叫3rd_part. 2. 注册用户Nuxus用户,如名叫dev,密码dev_123. 3. 给dev用户分配能访问3rd_ ...
- Vue.js 从源码理解v-for和v-if的优先级的高低
在vue.js里面,v-for和v-if是可以一起使用作用在某个元素上,网上看到一篇文章说永远不要把v-for和v-if同时用在同一个元素上,感觉有点瞎扯,官网也注明了可以一起使用的,还把两个指令的优 ...
- MYSQL使用group by,如何查询出总记录数
比如有这样一条SQL,根据t.user_id,t.report_date两个字段统计 这样前端页面能展示数据,但往往需要一个总记录数,在有分页的情况下用到 一种解决方法是在外面套一层,然后对其coun ...
- jq--实现自定义下拉框
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...