Spark学习笔记(一)——基础概述
本篇笔记主要说一下Spark到底是个什么东西,了解一下它的基本组成部分,了解一下基本的概念,为之后的学习做铺垫。过于细节的东西并不深究。在实际的操作过程中,才能够更加深刻的理解其内涵。
1、什么是Spark?
Spark是由美国加州伯克利大学的AMP实验室开发的,一款基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。 说白了就是搞数据计算分析的框架,过于细节的东西在学习过程中再去体会,一口吃不成胖子,反而会噎死人。
2、Spark的内置模块
来看一下Spark内置哪些模块:
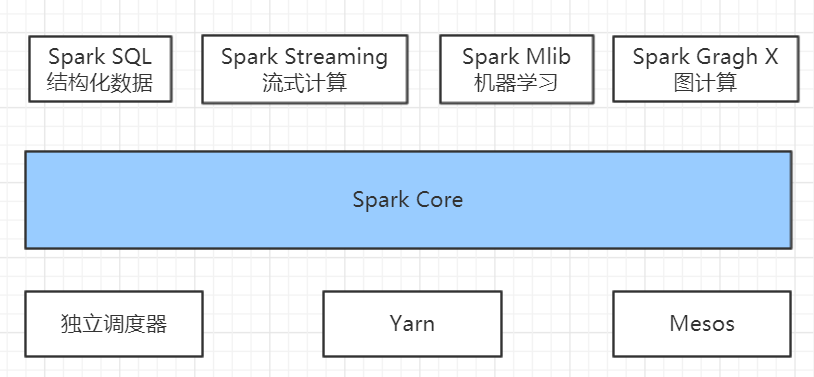
一个个来解释一下,语言过于官方,挑一些能看懂的看,其他的,用着用着就懂了:
Spark Core:Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景;通常所说的Apache Spark,就是指Spark Core;
Spark SQL: Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析;
Spark Streaming: Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等;
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计 算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。 如果是Spark节点单独使用一台机器的话,那么就用它的独立调度器负责资源的调度;如果是混搭的集群,那么还是统一用Yarn比较合适,以防出现争夺资源的情况。
3、Spark的特点
Hadoop虽然已成为大数据技术的事实标准,但其本身还存在诸多缺陷,最主要的缺陷是其MapReduce计算模型延迟过高,无法胜任实时、快速计算的需求,因而只适用于离线批处理的应用场景。
回顾Hadoop的工作流程,可以发现Hadoop存在如下一些缺点:
- 表达能力有限。计算都必须要转化成Map和Reduce两个操作,但这并不适合所有的情况,难以描述复杂的数据处理过程;
- 磁盘I/O开销大。MapReduce的计算是基于磁盘的,每次执行时都需要从磁盘读取数据,并且在计算完成后需要将中间结果写入到磁盘中,I/O开销较大;
- 延迟高。一次计算可能需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接由于涉及到I/O开销,会产生较高延迟。而且,在前一个任务执行完成之前,其他任务无法开始,难以胜任复杂、多阶段的计算任务。
Spark主要具有如下优点:
Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活;
Spark提供了内存计算,中间结果直接放到内存中,带来了更高的迭代运算效率;
Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
Spark提供了多种高层次、简洁的API,通常情况下,对于实现相同功能的应用程序,Spark的代码量要比Hadoop很多。Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了I/O开销。
注意咯,Spark并不能完全替代Hadoop,主要用于替代Hadoop中的MapReduce计算模型。实际上,Spark已经很好地融入了Hadoop生态圈,并成为其中的重要一员,它可以借助于YARN实现资源调度管理,借助于HDFS实现分布式存储。
4、Spark的重要角色
4.1 Master 和 Worker
1)Master
它是Spark特有资源调度系统的Leader,掌管着整个集群的资源信息,类似于Yarn中的ResourceManager,它的主要功能是:
- 监听Worker是否正常工作;
- Master对Worker、Application等的管理,具体包括接收Worker的注册,并且管理所有 的Worker;接收client提交的Application,调度等待的Application并向Worker提交。
2)Worker
它是Spark特有资源调度系统的slave,有多个。每个salve掌管着各自所在节点的资源信息,类似于Yarn框架中的NodeManager,它的主要功能是:
- 通过RegisterWorker注册到Master;
- 定时发送心跳信息给Master,告诉它 “我还活着”;
- 根据Master发送的Application配置进程环境,并启动ExcutorBackend(这是一个执行Task的临时进程)
4.2 Driver 和 Executor
上面所说的master和worker,不论有没有任务要被执行,这两个角色始终都是存在的,下边要说的driver和executor跟它俩不一样了。没必要一直起着,它们是伴随着提交的任务来的。当我们写好代码,打成jar包,提交到集群上运行,才会出现这两个东西。
1)Driver(驱动器)
Spark的驱动器是执行开发程序中的main方法的进程。它负责开发人员编写的用来创建SparkContext、创建RDD,以及进行RDD的转化操作和行动操作代码的执行。如果驱动器程序终止,那么Spark应用也就结束了。相当于ApplicationMaster,当前任务的老大。它主要负责:
把用户程序转为作业(JOB)
跟踪Executor的运行状况
为执行器节点调度任务
UI展示应用运行状况
2)Executor(执行器)
Spark Executor是一个工作节点,负责在 Spark 作业中运行任务,任务间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。主要负责:
负责运行组成 Spark 应用的任务,并将状态信息返回给驱动器进程;
通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。这个先暂时不看,后边学习了再说。
总结:Master和Worker是Spark的守护进程,也就是说Spark正常运行所必须的进程。Driver和Executor是临时程序,当有具体任务提交到Spark集群的时候才会开启的程序。
参考资料:
[1] 李海波. 大数据技术之Spark
Spark学习笔记(一)——基础概述的更多相关文章
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- OGG学习笔记01-基础概述
OGG学习笔记01-基础概述 OGG(Oracle Golden Gate),最近几年在数据同步.容灾领域特别火,甚至比Oracle自己的原生产品DataGuard还要风光,主要是因为其跨平台.跨数据 ...
- MyBatis:学习笔记(1)——基础知识
MyBatis:学习笔记(1)--基础知识 引入MyBatis JDBC编程的问题及解决设想 ☐ 数据库连接使用时创建,不使用时就释放,频繁开启和关闭,造成数据库资源浪费,影响数据库性能. ☐ 使用数 ...
- bootstrap学习笔记之基础导航条 http://www.imooc.com/code/3111
基础导航条 在Bootstrap框中,导航条和导航从外观上差别不是太多,但在实际使用中导航条要比导航复杂得多.我们先来看导航条中最基础的一个--基础导航条. 使用方法: 在制作一个基础导航条时,主要分 ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Django学习笔记(基础篇)
Django学习笔记(基础篇):http://www.cnblogs.com/wupeiqi/articles/5237704.html
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- C#学习笔记(基础知识回顾)之值类型与引用类型转换(装箱和拆箱)
一:值类型和引用类型的含义参考前一篇文章 C#学习笔记(基础知识回顾)之值类型和引用类型 1.1,C#数据类型分为在栈上分配内存的值类型和在托管堆上分配内存的引用类型.如果int只不过是栈上的一个4字 ...
随机推荐
- 请求(RequestInfo)
请求类型 StringRequestInfo 用在 SuperSocket 命令行协议中. 你也可以根据你的应用程序的需要来定义你自己的请求类型. 例如, 如果所有请求都包含 DeviceID 信息, ...
- U盘还原系统
相信现在不少的人已经开始使用U盘作为启动盘来安装系统,说起来这可比用光盘装系统可是方便多了.毕竟U盘可以随身携带,至于光盘嘛,就不多说了. 可是还有许多人对U盘安装系统还是有些陌生的感觉. ...
- 原生js设置audio在谷歌浏览器自动播放
https://www.cnblogs.com/sandraryan/ 谷歌浏览器更新后禁止了autoplay功能,但是有时候可能会需要自动播放. 研究了一段代码. <!DOCTYPE html ...
- CRF(条件随机场)与Viterbi(维特比)算法原理详解
摘自:https://mp.weixin.qq.com/s/GXbFxlExDtjtQe-OPwfokA https://www.cnblogs.com/zhibei/p/9391014.html C ...
- ThinkPHP URL 路由简介
简单的说,URL 路由就是允许你在一定规则下定制你需要的 URL 样子,以达到美化 URL ,提高用户体验,也有益于搜索引擎收录的目的. 例子 原本的 URL 为: http://www.5idev. ...
- [转]爬虫 selenium + phantomjs / chrome
目录 selenium 模块 安装 phantomjs 浏览器 安装 chromedriver 接口 安装 对比两个接口 整合使用 基本实例 常用属性方法 定位节点 节点操作 其他操作 实例解析 - ...
- 第二章FISCO BCOS sdk下载和配置是使用
想了解相关区块链开发,技术提问,请加QQ群:538327407 前提: 1.已经搭建好了一个底层,并且可以正常运行 2.确定外部是否可以连接,如果是云上的服务器,要保证外网可以访问 正式流程 1.下载 ...
- P1104 最大公约数和最小公倍数问题
题目描述 输入2个正整数 \(x0, y0 (2 \le x0 \lt 100000, 2 \le y0 \le 1000000)\) ,求出满足下列条件的 P,Q 的个数. 条件: P,Q是正整数 ...
- document.getElementById()
使用两个for循环取json数据的时候出错: 代码简化如下: for(var a=0;a<3;a++){ for(var b=0;b<3;b++){ document.getElement ...
- C# 从零开始写 SharpDx 应用 绘制基础图形
本文告诉大家通过 SharpDx 画出简单的 2D 界面 本文属于 SharpDx 系列 博客,建议从头开始读 本文分为两步,第一步是初始化,第二步才是画界面 初始化 先创建 RenderForm 用 ...