SpringCloud之Fegin学习笔记
以下部分内容来源于网络摘抄~
1.作用
Feign 是一种声明式、模板化的 HTTP 客户端。在 Spring Cloud 中使用 Feign,可以做到使用 HTTP 请求访问远程服务,就像调用本地方法一样的,开发者完全感知不到这是在调用远程方法,更感知不到在访问 HTTP 请求。接下来介绍一下 Feign 的特性,具体如下:
可插拔的注解支持,包括 Feign 注解和AX-RS注解。
支持可插拔的 HTTP 编码器和解码器。
支持 Hystrix 和它的 Fallback。
支持 Ribbon 的负载均衡。
支持 HTTP 请求和响应的压缩。Feign 是一个声明式的 WebService 客户端,它的目的就是让 Web Service 调用更加简单。它整合了 Ribbon 和 Hystrix,从而不需要开发者针对 Feign 对其进行整合。Feign 还提供了 HTTP 请求的模板,通过编写简单的接口和注解,就可以定义好 HTTP 请求的参数、格式、地址等信息。Feign 会完全代理 HTTP 的请求,在使用过程中我们只需要依赖注入 Bean,然后调用对应的方法传递参数即可。
2. Feign和Dubbo区别
通过Feign封装了HTTP调用服务方法, 类似Dubbo中暴露远程服务的方式,区别在于Dubbo是基于私有二进制协议,而Feign本质上还是个HTTP客户端。
3.工作原理
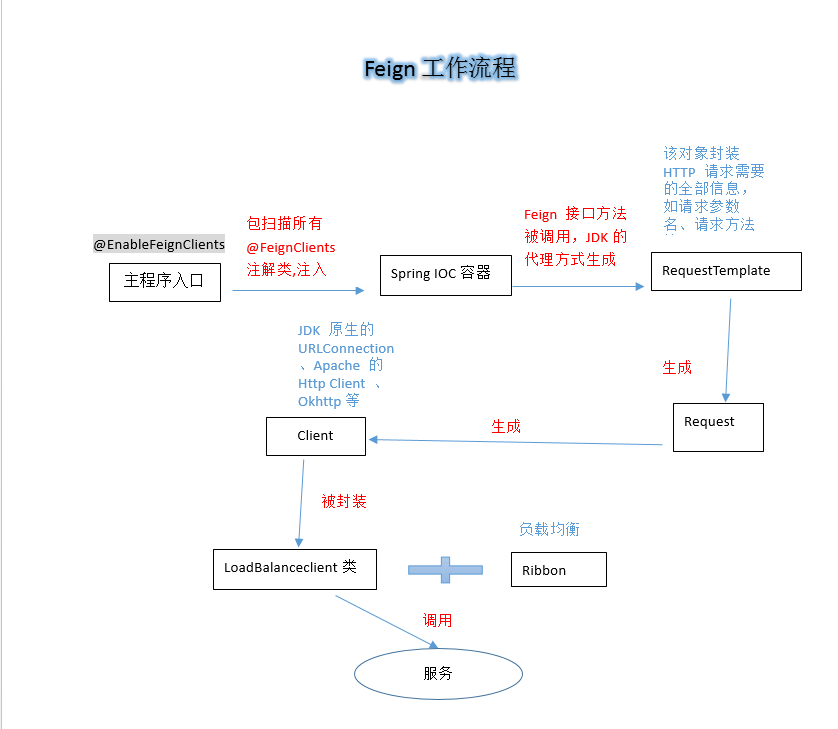
在开发微服务应用时,我们会在主程序入口添加 @EnableFeignClients 注解开启对 Feign Client 扫描加载处理。根据 Feign Client 的开发规范,定义接口并加 @FeignClients 注解。
当程序启动时,会进行包扫描,扫描所有 @FeignClients 的注解的类,并将这些信息注入 Spring IOC 容器中。当定义的 Feign 接口中的方法被调用时,通过JDK的代理的方式,来生成具体的 RequestTemplate。当生成代理时,Feign 会为每个接口方法创建一个 RequetTemplate 对象,该对象封装了 HTTP 请求需要的全部信息,如请求参数名、请求方法等信息都是在这个过程中确定的。
然后由 RequestTemplate 生成 Request,然后把 Request 交给 Client 去处理,这里指的 Client 可以是 JDK 原生的 URLConnection、Apache 的 Http Client 也可以是 Okhttp。最后 Client 被封装到 LoadBalanceclient 类,这个类结合 Ribbon 负载均衡发起服务之间的调用。
4.@FeignClient 注解
name:指定 Feign Client 的名称,如果项目使用了 Ribbon,name 属性会作为微服务的名称,用于服务发现。
url:url 一般用于调试,可以手动指定 @FeignClient 调用的地址。
decode404:当发生404错误时,如果该字段为 true,会调用 decoder 进行解码,否则抛出 FeignException。
configuration:Feign 配置类,可以自定义 Feign 的 Encoder、Decoder、LogLevel、Contract。
fallback:定义容错的处理类,当调用远程接口失败或超时时,会调用对应接口的容错逻辑,fallback 指定的类必须实现 @FeignClient 标记的接口。
fallbackFactory:工厂类,用于生成 fallback 类示例,通过这个属性我们可以实现每个接口通用的容错逻辑,减少重复的代码。
path:定义当前 FeignClient 的统一前缀。
SpringCloud之Fegin学习笔记的更多相关文章
- SpringCloud微服务学习笔记
SpringCloud微服务学习笔记 项目地址: https://github.com/taoweidong/Micro-service-learning 单体架构(Monolithic架构) Mon ...
- 【原创】SpringBoot & SpringCloud 快速入门学习笔记(完整示例)
[原创]SpringBoot & SpringCloud 快速入门学习笔记(完整示例) 1月前在系统的学习SpringBoot和SpringCloud,同时整理了快速入门示例,方便能针对每个知 ...
- 肝了很久,冰河整理出这份4万字的SpringCloud与SpringCloudAlibaba学习笔记!!
写在前面 不少小伙伴让我整理下有关SpringCloud和SpringCloudAlibaba的知识点,经过3天的收集和整理,冰河整理出这份4万字的SpringCloud与SpringCloudAli ...
- springcloud Eureka学习笔记
最近在学习springcloud,抽空记录下学习笔记;主要记录Eureka的实现过程和高可用性的实现 Eureka是一个服务治理框架,它提供了Eureka Server和Eureka Client两个 ...
- SpringCloud学习笔记(2):使用Ribbon负载均衡
简介 Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡工具,在注册中心对Ribbon客户端进行注册后,Ribbon可以基于某种负载均衡算法,如轮询(默认 ...
- SpringCloud学习笔记(3):使用Feign实现声明式服务调用
简介 Feign是一个声明式的Web Service客户端,它简化了Web服务客户端的编写操作,相对于Ribbon+RestTemplate的方式,开发者只需通过简单的接口和注解来调用HTTP API ...
- SpringCloud学习笔记(4):Hystrix容错机制
简介 在微服务架构中,微服务之间的依赖关系错综复杂,难免的某些服务会出现故障,导致服务调用方出现远程调度的线程阻塞.在高负载的场景下,如果不做任何处理,可能会引起级联故障,导致服务调用方的资源耗尽甚至 ...
- SpringCloud学习笔记(5):Hystrix Dashboard可视化监控数据
简介 上篇文章中讲了使用Hystrix实现容错,除此之外,Hystrix还提供了近乎实时的监控.本文将介绍如何进行服务监控以及使用Hystrix Dashboard来让监控数据图形化. 项目介绍 sc ...
- SpringCloud学习笔记(6):使用Zuul构建服务网关
简介 Zuul是Netflix提供的一个开源的API网关服务器,SpringCloud对Zuul进行了整合和增强.服务网关Zuul聚合了所有微服务接口,并统一对外暴露,外部客户端只需与服务网关交互即可 ...
随机推荐
- 安装mysql时,服务无法启动的问题
1.下载mysql镜像文件:mysql-installer-community-8.0.17.0.msi 2.点击镜像进行安装,一直next即可 3.cmd以管理员身份,进入到安装的mysql安装目录 ...
- 记录一次MySQL数据库CPU负载异常高的问题
1.起因 某日下午18:40开始,接收到滕讯云短信报警,显示数据库CPU使用率已超过100%,同时慢查询日志的条数有1500条左右. 正常情况下:CPU使用率为30%-40%之间,慢查询日志条数为0. ...
- 为kubectl配置别名和命令行补齐
配置别名 # vim ~/.bashrc 添加 alias k='kubectl' # source ~/.bashrc 配置命令行补齐 # yum install -y bash-completio ...
- java 冒泡排序法、选择排序
1.冒泡排序 /* * 冒泡排序 * 外层控制循环多少趟,内层控制每一趟的循环次数 */ public class Test08 { public static void main(String[] ...
- 2018-12-1-WPF-修改-ItemContainerStyle-鼠标移动到未选中项效果和选中项背景
title author date CreateTime categories WPF 修改 ItemContainerStyle 鼠标移动到未选中项效果和选中项背景 lindexi 2018-12- ...
- Theorem、Proposition、Lemma和Corollary等的解释与区别
Theorem:定理.是文章中重要的数学化的论述,一般有严格的数学证明. Proposition:可以翻译为命题,经过证明且interesting,但没有Theorem重要,比较常用. Lemma:一 ...
- elast数据存放
这几天一直在索引数据,突然发现服务器状态变红色了,去官网看了下 集群状态如果是红色的话表示有数据已经丢失了!这下头大了才索引了7G数据,后面还有10多个G, 我在liunx下看了下磁盘空间 发现运行e ...
- ubuntu下安装git提示无root权限
apt-get install git 获取git指令 sudo passwd root 重置unix密码 su root 键入密码 参考链接 https://www.cnblogs.com/2she ...
- 校园商铺-2项目设计和框架搭建-10验证controller
1.新建package:com.csj2018.o2o.web.superadmin 2.建立AreaController.java package com.csj2018.o2o.web.super ...
- 阿里云宣布进入 Serverless 容器时代,推出弹性容器实例服务 ECI
摘要: 阿里云宣布弹性容器实例 ECI(Elastic Container Instance)正式商业化. 为了应对业务高峰,打算提前多久执行ECS扩展?买了ECS虚拟机,容器规格不能完美装箱怎么办? ...