[oeasy]python0123_中文字符_文字编码_gb2312_激光照排技术_王选
- 上次回顾了 日韩各有 编码格式
- 日本
- 有假名
- 五十音
- 一字节 可以勉强放下
- 有日本汉字
- 字符数量超过20000+
- 韩国
- 有谚文
- 数量超过500
- 一个字节 放不下
- 有朝鲜汉字
- 字符数量超过20000+

- 作为 汉字源头的中国
- 究竟应该 如何对汉字 进行编码 呢?
- 汉字起源于甲骨文
- 是世界上唯一还在使用的象形文字
- 真的很不容易

- 写的本意 就是 画
- 写意
- 写生
- 这就是最初的
- 象形字
- 以象形为基础
- 指事
- 会意
- 形声
- 转注
- 假借

- 字的结构是什么呢?
- 上下
- 左右
- 内外

- 字型相当复杂
- 笔画也千姿百态
- 笔画也比较复杂

- 运笔藏锋都很有讲究
- 中国大陆地区最早使用 GB/T 2312-1980
- 当时参考了比我们先进的日本JIS 字符集
- 1980 年 指定的国标 (GuoBiao)
- 1981 年 5 月 1 日开始使用

- GB2312 编码共收录汉字 6763 个
- 其中一级汉字 3755 个
- 二级汉字 3008 个
- 这么多字怎么排呢?
- 01-09 区为特殊符号
- 先把ascii的128个字符让出去
- 然后在留有一些制表的字符
- 还留了相当多的空余
- 16-55 区为一级汉字
- 按拼音排序
- 56-87 区为二级汉字
- 按部首/笔画排序

- 出了汉字之外,还收录了
- 拉丁字母
- 希腊字母
- 日文平假名及片假名字母
- 俄语西里尔字母
- 真的很全了
- 可是这gb2312
- 具体是如何编解码的呢?
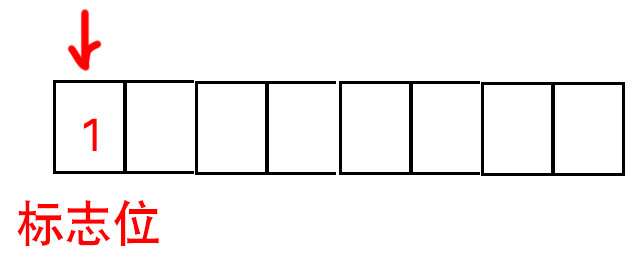
- 如果是0-127以内的ascii字符
- 标志位为0
- 1个字节存储
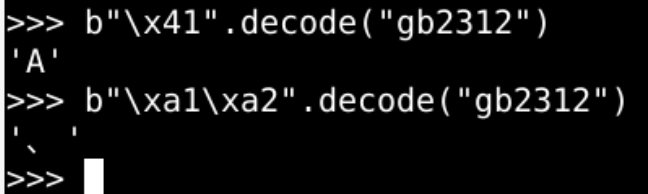
- 如果是ascii以外的字符
- 标志位为1
- 2个字节存储
- 编解码方法一致就可以
- 解铃还须系铃人
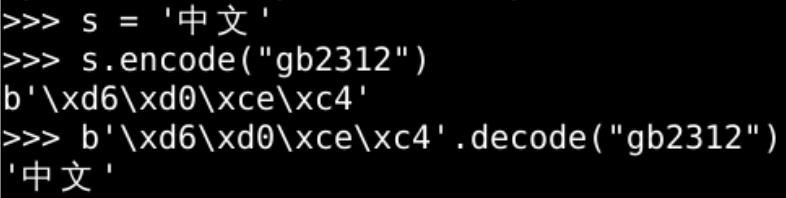
- 同时用 gb2312 编解码是没有问题的
- 这篇 制定标准的文档
- 当时怎么打印出来的呢?
- 制定内码标准的 时候 就有 字形 了吗?
- 虽然 计算机 在当时 还 没有普及
- 但是 出版行业 已经 工业化 了

- 印刷厂 使用 铅活字 进行排版
- 铸字工
- 拼版工
- 还有拣字工
- 印刷家谱 从 一个大盒子 就够了

- 字 再多些
- 要用 转轮排字盘

- 字 再多些呢?
- 大 印刷厂
- 字模 特别多

- 甚至 要放
- 好 几面墙
- 好 几张桌子
- 这 也 曾被
- 使用26个字母的 西方文明 嘲讽
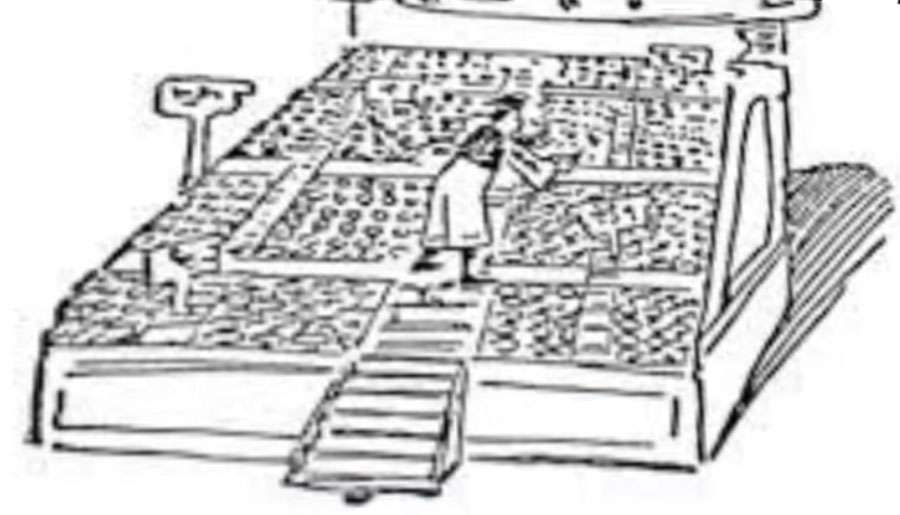
- 出书确实不易
- 捡好了 字
- 排好了 版
- 先 打个样
- 再来 校对
- 再 浇铅板
- 最后 印刷
- 最初的
- 书籍
- 杂志
- 报纸
- 试卷
- 都是这样 印刷出来 的
- 到了 印刷 gb2312-80标准的 1980年
- 已经启用了新的技术
- 从 轮转排字盘
- 到 谢卫楼 发明的 中文打字机

- 再到 舒震东
- 在前人的研究基础上经过创新
- 得到的 舒式打字机

- 中文字符 的数量
- 是 一个难关
- 直到
- 照相技术 的 发展
- 使用 照片底片 进行排版

- 也面临检字的工作

- 照片排版技术本身也在迭代
- 这次使用 激光 扫描照片
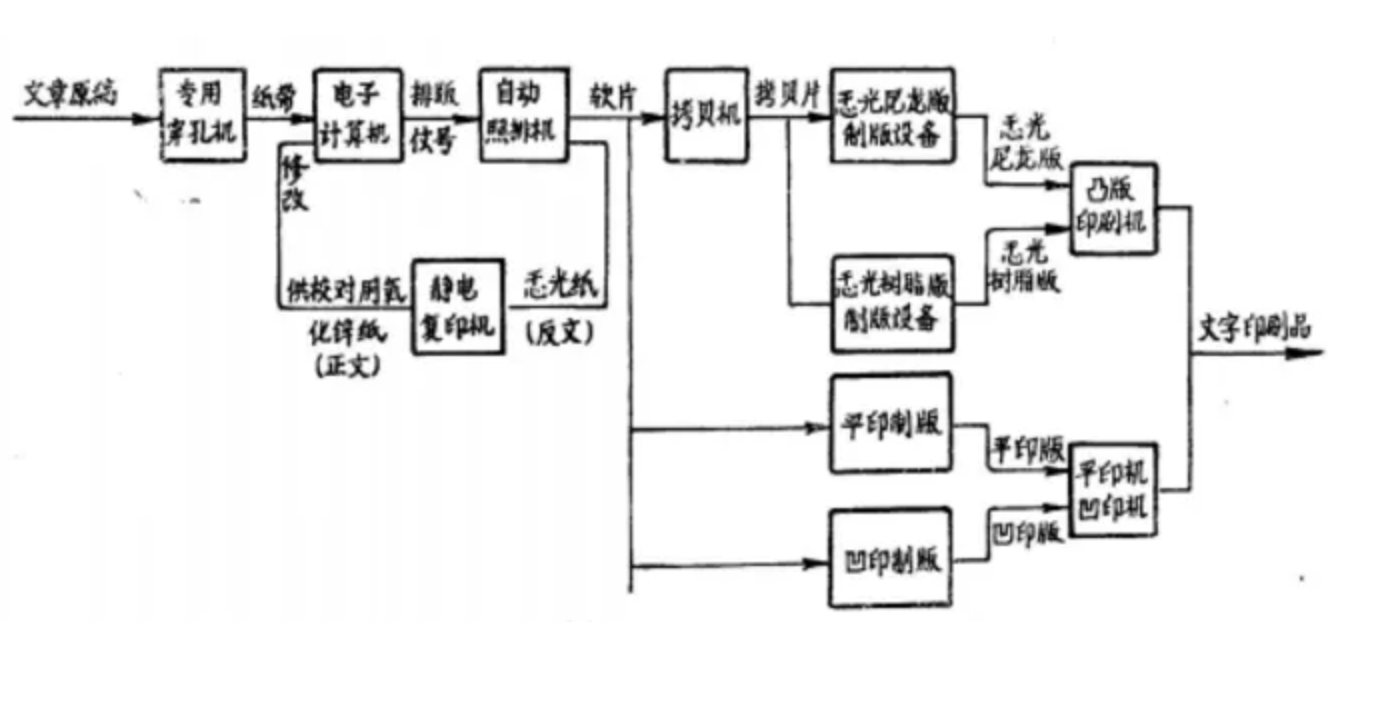
- 每一个小字型都是一个照片
- 根据汉字内码找到汉字对应的激光照片
- 然后再把激光照片像活字一样排版
- 这就是激光照排技术

- 用照片排版的方式
- 制作了这样一个汉字编码的文档
- 标准定了立刻就能用起来么?
- 凡事都有个过程
- 95年定的gbk
- 98年才逐渐推行开来
- 但还是有些生僻字没有相应的字型

- 内码从无到有
- 字形码也从无到有

- 感谢王选与陈堃銶前辈的技艺

- 激光照排技术 可以
- 印刷中文书籍 和 报纸 了
- 简体和繁体的汉字
- 字符数量都超级大
- 感谢王选和陈堃銶等前辈发明了激光照排技术
- 中文排版从此使用上了gb2312编码

- 纸张之外
- 显示器是更先进的输出设备
- 计算机是如何在显示器上显示的呢?
- 我们下次再说!
[oeasy]python0123_中文字符_文字编码_gb2312_激光照排技术_王选的更多相关文章
- perl处理含有中文字符的json编码
例子:1. 有php的 json函数生成的中文串 [root@tts177:/tmp]$/opt/php/bin/php -r 'echo json_encode(Array("a" ...
- 编码占用的字节数 1 byte 8 bit 1 sh 1 bit 中文字符编码 2. 字符与编码在程序中的实现 变长编码 Unicode UTF-8 转换 在网络上传输 保存到磁盘上 bytes
小结: 1.UNICODE 字符集编码的标准有很多种,比如:UTF-8, UTF-7, UTF-16, UnicodeLittle, UnicodeBig 等: 2 服务器->网页 utf-8 ...
- 中文字符 unicode转utf-8函数 python实现
unicode编码范围 00000000-0000007F的字符,用单个字节来表示: 00000080-000007FF的字符用两个字节表示 (中文的编码范围) 00000800-0000FFFF的字 ...
- Java实现 中文转换成Unicode编码 和 Unicode编码转换成中文
想要实现中文字符转换为Unicode编码的话主要用到的是一个这样的包,自己可以去API文档里面查看下的 java.util.Properties; 直接进入主题吧,主要是 package Test01 ...
- ajax 传递中文字符参数 问题
使用ajax 传递中文字符串时, 服务端会接收不到预期的 中文字符. 此时,需要对 js中的中文字符参数进行 编码, 到达服务端后, 再为其解码 即可. 前端: var url = '....'; ...
- 在使用NSArray打印的时候如果遇到中文字符那么会打印出来编码。
在使用NSArray打印的时候如果遇到中文字符那么会打印出来编码,如下代码: - (void)viewDidLoad { [super viewDidLoad]; // Do any addition ...
- python利用utf-8编码判断中文字符
下面这个小工具包含了 判断unicode是否是汉字,数字,英文,或者其他字符. 全角符号转半角符号. unicode字符串归一化等工作. 还有一个能处理多音字的汉字转拼音的程序,还在整理中. #!/u ...
- 使用 URLDecoder 和 URLEncoder 对中文字符进行编码和解码
原文: https://blog.csdn.net/justloveyou_/article/details/57156039 使用 URLDecoder 和 URLEncoder 对中文字符进行编码 ...
- url为什么要编码及php中的中文字符urlencode基本原理
首先了解以下中文字符在使用urlencode的时候运用的基本原理: urlencode()函数原理就是首先把中文字符转换为十六进制,然后在每个字符前面加一个标识符%. 此字符串中除了 -_. 之外的所 ...
- Python2.7 中文字符编码 & Pycharm utf-8设置、Unicode与utf-8的区别
Python2.7 中文字符编码 & Pycharm utf-8设置.Unicode与utf-8的区别 zoerywzhou@163.com http://www.cnblogs.com/sw ...
随机推荐
- 大数据之Hadoop中HDFS的故障排除
NameNode故障处理 1)需求 NameNode进程挂了并且存储的数据也丢失了 2)故障模拟 (1)kill -9 NameNode进程 kill -9 19886 (2)删除NameNode储存 ...
- C#应用的用户配置窗体方案 - 开源研究系列文章
这次继续整理以前的代码.本着软件模块化的原理,这次笔者对软件中的用户配置窗体进行剥离出来,单独的放在一个Dll类库里进行操作,这样在其它应用程序里也能够快速的复用该类库,达到了快速开发软件的效果. 笔 ...
- [Unity] 实现AssetBundle资源加载管理器
实现Unity AssetBundle资源加载管理器 AssetBundle是实现资源热更新的重要功能,但Unity为其提供的API却十分基(jian)础(lou).像是自动加载依赖包.重复加载缓存. ...
- NET9 AspnetCore将整合OpenAPI的文档生成功能而无需三方库
OpenAPI 规范是用于描述 HTTP API 的标准.该标准允许开发人员定义 API 的形状,这些 API 可以插入到客户端生成器.服务器生成器.测试工具.文档等中.尽管该标准具有普遍性和普遍性, ...
- 前端如何对cookie加密
在前端对 Cookie 进行加密时,你可以使用加密算法对 Cookie 的值进行加密,然后再将加密后的值存储到 Cookie 中.常用的加密算法包括对称加密算法(如 AES)和非对称加密算法(如 RS ...
- Validate插件的自定义验证方法入门(结合Ajax实现用户名的数据库查重)
概述 本文介绍Validate自定义表单校验方式.Validate插件虽然提供了丰富的验证规则,但在很多时候仍然很难满足我们的开发需求,在注册页面我们需要通过ajax验证用户输入的用户名是否已经被他人 ...
- Flutter学习网站和安装问题
一.Flutter网站 Flutter中文开发者网站(推荐) https://flutter.cn/ 二.Flutter第三方库 Pub.Dev https://pub.dev/ 三.Flutter源 ...
- 春松客服入驻Rainbond开源应用商店
"做好开源客服系统" 春松客服是拥有坐席管理.渠道管理.机器人客服.数据分析.CRM 等功能于一身的新一代客服系统.将智能机器人与人工客服完美融合,同时整合了多种渠道,结合 CRM ...
- nginx四层负载nginx七层负载,nginx基于nginx-sticky会话保持.
1. nginx负载均衡实战 nginx提供了 4 7层负载均衡. 可根据业务需求选择不同负载均衡策略. 1.1.1 nginx四层负载均衡[网络层TCP负载] 不支持动静分离,但支持 http my ...
- 安装配置intelli IDEA
效果 操作 去官网下载安装包 下载 Intelli IDEA 下载插件 插件下载 打开IDEA安装目录下的bin目录,找到idea64.exe.vmoptions配置文件 添加配置 打开indea,添 ...