flink同步MySQL数据的时候出现内存溢出
flink同步MySQL数据的时候出现内存溢出
背景:需要将1000w的某类型数据同步到别的数据源里面,使用公司的大数据平台可以很快处理完毕,而且使用的内存只有很少很少量(公司的大数据平台的底层是flink,但是连接器使用的是chunjun开源产品),由于我个人想使用flink原生的连接器来尝试一下,所以就模拟了1000w的数据,然后启动了flink单节点,通过flinksql的方式提交了同步任务,最终结果内存溢出!!!
下面的问题是在使用MySQL数据源的时候出现的,别的数据源可能不会有这个问题
下面是在main方法里面写的flink代码
import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.Logger;
import ch.qos.logback.classic.LoggerContext;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.slf4j.LoggerFactory;
import java.util.List;
public class Main2 {
static {
LoggerContext loggerContext = (LoggerContext) LoggerFactory.getILoggerFactory();
List<Logger> loggerList = loggerContext.getLoggerList();
loggerList.forEach(logger -> {
logger.setLevel(Level.INFO);
});
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
streamExecutionEnvironment.setParallelism(1);
StreamTableEnvironment streamTableEnvironment = StreamTableEnvironment.create(streamExecutionEnvironment);
// 定义目标表
streamTableEnvironment.executeSql("CREATE TABLE `gsq_hsjcxx_pre_copy1` (\n" +
" `reportid` BIGINT COMMENT 'reportid',\n" +
" `sfzh` VARCHAR COMMENT 'sfzh',\n" +
" `cjddh` VARCHAR COMMENT 'cjddh',\n" +
" `cjsj` VARCHAR COMMENT 'cjsj',\n" +
" PRIMARY KEY (`reportid`) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://127.0.0.1:3306/xxx?useSSL=false&useInformationSchema=true&nullCatalogMeansCurrent=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&',\n" +
" 'table-name' = 'xxx',\n" +
" 'username' = 'xxx',\n" +
" 'password' = 'xxx',\n" +
" 'sink.buffer-flush.max-rows' = '1024'\n" +
")");
// 定义源表
streamTableEnvironment.executeSql("CREATE TABLE `gsq_hsjcxx_pre` (\n" +
" `reportid` BIGINT COMMENT 'reportid',\n" +
" `sfzh` VARCHAR COMMENT 'sfzh',\n" +
" `cjddh` VARCHAR COMMENT 'cjddh',\n" +
" `cjsj` VARCHAR COMMENT 'cjsj'\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://127.0.0.1:3306/xxx?useSSL=false&useInformationSchema=true&nullCatalogMeansCurrent=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai',\n" +
" 'table-name' = 'xxx',\n" +
" 'username' = 'xxx',\n" +
" 'password' = 'xxx',\n" +
" 'scan.fetch-size' = '1024'\n" +
")");
// 将源表数据插入到目标表里面
streamTableEnvironment.executeSql("INSERT INTO `gsq_hsjcxx_pre_copy1` (`reportid`,\n" +
" `sfzh`,\n" +
" `cjddh`,\n" +
" `cjsj`)\n" +
"(SELECT `reportid`,\n" +
" `sfzh`,\n" +
" `cjddh`,\n" +
" `cjsj`\n" +
" FROM `gsq_hsjcxx_pre`)");
streamExecutionEnvironment.execute();
}
}
以上是一个简单的示例,定义了三个sql语句,首先是定义两个数据源,然后再进行查询插入操作,运行之后就会开始执行flinksql。
如果在启动的时候指定jvm的内存大小为 -Xms512m -Xmx1g,会发现压根启动不起来,直接就oom了。
如果不指定jvm内存的话,则程序能启动,内存的使用量会慢慢的升高,甚至要使用将近4G内存,如果在flink集群上运行的话,直接会oom的。
先说flink读取数据的流程,flink读取数据的时候是分批读取的,不可能一次性把数据全部读出来的,但是通过现象来看是flink读取数据的时候,所有数据都在内存里面的,这个现象是不合理的。
分析源码
通过调试模式分析代码是怎么走的,经过一番调试之后发现了一下代码
public void openInputFormat() {
try {
Connection dbConn = this.connectionProvider.getOrEstablishConnection();
if (this.autoCommit != null) {
dbConn.setAutoCommit(this.autoCommit);
}
this.statement = dbConn.prepareStatement(this.queryTemplate, this.resultSetType, this.resultSetConcurrency);
if (this.fetchSize == -2147483648 || this.fetchSize > 0) {
this.statement.setFetchSize(this.fetchSize);
}
} catch (SQLException var2) {
throw new IllegalArgumentException("open() failed." + var2.getMessage(), var2);
} catch (ClassNotFoundException var3) {
throw new IllegalArgumentException("JDBC-Class not found. - " + var3.getMessage(), var3);
}
}
先说下flink是怎么是如果分批拉取数据的,flink是使用的游标来分批拉取数据,那么这个时候就要确定是否真正使用了游标。
于是乎,我写了一个原生的JDBC程序读取数据的程序(没有限制jvm内存)
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class Main3 {
public static void main(String[] args) {
Connection connection = null;
Runtime runtime = Runtime.getRuntime();
System.out.printf("启动前总内存>%s 使用前的空闲内存>%s 使用前最大内存%s%n", runtime.totalMemory() / 1024 / 1024, runtime.freeMemory() / 1024 / 1024, runtime.maxMemory() / 1024 / 1024);
try {
int i = 0;
connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/xxx?useSSL=false&useInformationSchema=true&nullCatalogMeansCurrent=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useCursorFetch=true", "xxx", "xxx");
connection.setAutoCommit(false);
PreparedStatement preparedStatement = connection.prepareStatement("SELECT `reportid`,\n" +
" `sfzh`,\n" +
" `cjddh`,\n" +
" `cjsj`\n" +
" FROM `gsq_hsjcxx_pre`", ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
// 每批拉取的数据量
preparedStatement.setFetchSize(1024);
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
i++;
}
System.out.printf("启动前总内存>%s 使用前的空闲内存>%s 使用前最大内存%s%n", runtime.totalMemory() / 1024 / 1024, runtime.freeMemory() / 1024 / 1024, runtime.maxMemory() / 1024 / 1024);
System.out.println("数据量> " + i);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (connection != null) {
try {
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
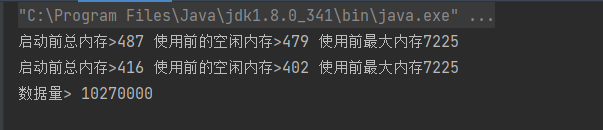
最终打印的结果是

很显然,数据是全部读取出来的,这个时候需要确认的程序是不是真正使用了游标,经过一番查看后发现,需要在jdbc的参数里面加上&useCursorFetch=true,才能使游标生效
修改完jdbc参数之后,问题就得到了完全的结局
除此之外我用过apahce的seatunnel,这个同步数据的时候是真的快,快的离谱。不过使用的时候可能会漏掉一些jdbc相关的参数(MySQL为例)
"rewriteBatchedStatements" : "true" 这个批量的参数 apache seatunnel也不会自动添加的,需要手动加,不然数据就是一条一条插入的,这个坑我也踩了
flink同步MySQL数据的时候出现内存溢出的更多相关文章
- 推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭. 例如:某记录内容为"aaa|bbb|ccc",将其按 ...
- 使用Logstash来实时同步MySQL数据到ES
上篇讲到了ES和Head插件的环境搭建和配置,也简单模拟了数据作测试 本篇我们来实战从MYSQL里直接同步数据 一.首先下载和你的ES对应的logstash版本,本篇我们使用的都是6.1.1 下载后使 ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- Logstash使用jdbc_input同步Mysql数据时遇到的空时间SQLException问题
今天在使用Logstash的jdbc_input插件同步Mysql数据时,本来应该能搜索出10条数据,结果在Elasticsearch中只看到了4条,终端中只给出了如下信息 [2017-08-25T1 ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- logstash增量同步mysql数据到es
本篇本章地址:https://www.cnblogs.com/Thehorse/p/11601013.html 今天我们来讲一下logstash同步mysql数据到es 我认为呢,logstash是众 ...
- logstash使用template提前设置好maping同步mysql数据到Elasticsearch5.5.2
上篇blog说到采用logstash-input-jdbc将mysql数据同步到ES(http://www.cnblogs.com/jstarseven/p/7704893.html),但是这里有一个 ...
- canal同步MySQL数据到ES6.X
背景: 最近一段时间公司做一个技术架构的更改,由于之前使用的solr和目前的业务不太匹配,具体原因不多说啦.所以要把数据放到Elasticsearch中进行快速的搜索,这是便产生了一个数据迁移的需求, ...
- Centos8 部署 ElasticSearch 集群并搭建 ELK,基于Logstash同步MySQL数据到ElasticSearch
Centos8安装Docker 1.更新一下yum [root@VM-24-9-centos ~]# yum -y update 2.安装containerd.io # centos8默认使用podm ...
- flink-cdc同步mysql数据到hive
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的 ...
随机推荐
- 【Layui】09 动画 Anim
文档地址: https://www.layui.com/demo/anim.html 8种动画 <fieldset class="layui-elem-field layui-fiel ...
- 分享某Python下的mpi教程 —— A Python Introduction to Parallel Programming with MPI 1.0.2 documentation ( 续 #2 )
接前文: 分享某Python下的mpi教程 -- A Python Introduction to Parallel Programming with MPI 1.0.2 documentation ...
- PEP 703作者给出的一种no-GIL的实现——python3.9的nogil版本
PEP 703的内容是什么,意义又是什么呢? 可以说python的官方接受的no-GIL提议的PEP就是PEP 703给出的,如果GIL帧的从python中移除那么可以说对整个python生态圈将有着 ...
- 【转载】 关于Numpy数据类型对象(dtype)使用详解
原文地址: https://www.cnblogs.com/dreamboy2000/p/15350478.html ========================================= ...
- 如何在vscode中同时运行多个文件——server/client模式——在launch.json文件中设置多个configurations再compounds
在vscode中我们一般都是同一时间只运行一个代码,但是这种设置并不适合server/client模式,甚至有很多分布式和并行的项目需要同一时间运行多个client,针对这种情况我们可以通过设置vsc ...
- [学习笔记] 单调队列优化DP - DP
单调队列优化DP 简单好想的DP优化 真正的教育是把学过的知识忘掉后剩下的东西 -- *** 对于一个转移方程类似于 \(dp[i]=max(min)\{dp[j]+b[j]+a[i]\}\ \ x_ ...
- MFC制作带界面的DLL库
## MFC如何创建一个带界面的DLL(动态链接库) 1.创建项目 打开VS,文件->新建->项目: 点击确定之后弹出来的界面,点击下一步->选择"使用共享MFC DLL的 ...
- 面试必问之redis
这里是我作为10年面试经验总结的面试中必问问题 问题一 简单介绍下redis redis是当前比较热门的NOSQL系统之一,它是一个开源的使用ANSI c语言编写的key-value存储系统(区别于M ...
- LLM应用实战: 产业治理多标签分类
1. 背景 许久未见,甚是想念~ 近期本qiang~换了工作,处于新业务适应期,因此文章有一段时间未更新,理解万岁! 现在正在着手的工作是产业治理方面,主要负责其中一个功能模块,即按照产业治理标准体系 ...
- zabbix 4.0汉化
一.主机名支持中文 1.在/usr/share/zabbix/include/defines.inc.php文件中修改,大概在1092行(zabbix-4.0),加入中文字符支持, 原始正则: def ...