flink同步MySQL数据的时候出现内存溢出
flink同步MySQL数据的时候出现内存溢出
背景:需要将1000w的某类型数据同步到别的数据源里面,使用公司的大数据平台可以很快处理完毕,而且使用的内存只有很少很少量(公司的大数据平台的底层是flink,但是连接器使用的是chunjun开源产品),由于我个人想使用flink原生的连接器来尝试一下,所以就模拟了1000w的数据,然后启动了flink单节点,通过flinksql的方式提交了同步任务,最终结果内存溢出!!!
下面的问题是在使用MySQL数据源的时候出现的,别的数据源可能不会有这个问题
下面是在main方法里面写的flink代码
import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.Logger;
import ch.qos.logback.classic.LoggerContext;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.slf4j.LoggerFactory;
import java.util.List;
public class Main2 {
static {
LoggerContext loggerContext = (LoggerContext) LoggerFactory.getILoggerFactory();
List<Logger> loggerList = loggerContext.getLoggerList();
loggerList.forEach(logger -> {
logger.setLevel(Level.INFO);
});
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
streamExecutionEnvironment.setParallelism(1);
StreamTableEnvironment streamTableEnvironment = StreamTableEnvironment.create(streamExecutionEnvironment);
// 定义目标表
streamTableEnvironment.executeSql("CREATE TABLE `gsq_hsjcxx_pre_copy1` (\n" +
" `reportid` BIGINT COMMENT 'reportid',\n" +
" `sfzh` VARCHAR COMMENT 'sfzh',\n" +
" `cjddh` VARCHAR COMMENT 'cjddh',\n" +
" `cjsj` VARCHAR COMMENT 'cjsj',\n" +
" PRIMARY KEY (`reportid`) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://127.0.0.1:3306/xxx?useSSL=false&useInformationSchema=true&nullCatalogMeansCurrent=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&',\n" +
" 'table-name' = 'xxx',\n" +
" 'username' = 'xxx',\n" +
" 'password' = 'xxx',\n" +
" 'sink.buffer-flush.max-rows' = '1024'\n" +
")");
// 定义源表
streamTableEnvironment.executeSql("CREATE TABLE `gsq_hsjcxx_pre` (\n" +
" `reportid` BIGINT COMMENT 'reportid',\n" +
" `sfzh` VARCHAR COMMENT 'sfzh',\n" +
" `cjddh` VARCHAR COMMENT 'cjddh',\n" +
" `cjsj` VARCHAR COMMENT 'cjsj'\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://127.0.0.1:3306/xxx?useSSL=false&useInformationSchema=true&nullCatalogMeansCurrent=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai',\n" +
" 'table-name' = 'xxx',\n" +
" 'username' = 'xxx',\n" +
" 'password' = 'xxx',\n" +
" 'scan.fetch-size' = '1024'\n" +
")");
// 将源表数据插入到目标表里面
streamTableEnvironment.executeSql("INSERT INTO `gsq_hsjcxx_pre_copy1` (`reportid`,\n" +
" `sfzh`,\n" +
" `cjddh`,\n" +
" `cjsj`)\n" +
"(SELECT `reportid`,\n" +
" `sfzh`,\n" +
" `cjddh`,\n" +
" `cjsj`\n" +
" FROM `gsq_hsjcxx_pre`)");
streamExecutionEnvironment.execute();
}
}
以上是一个简单的示例,定义了三个sql语句,首先是定义两个数据源,然后再进行查询插入操作,运行之后就会开始执行flinksql。
如果在启动的时候指定jvm的内存大小为 -Xms512m -Xmx1g,会发现压根启动不起来,直接就oom了。
如果不指定jvm内存的话,则程序能启动,内存的使用量会慢慢的升高,甚至要使用将近4G内存,如果在flink集群上运行的话,直接会oom的。
先说flink读取数据的流程,flink读取数据的时候是分批读取的,不可能一次性把数据全部读出来的,但是通过现象来看是flink读取数据的时候,所有数据都在内存里面的,这个现象是不合理的。
分析源码
通过调试模式分析代码是怎么走的,经过一番调试之后发现了一下代码
public void openInputFormat() {
try {
Connection dbConn = this.connectionProvider.getOrEstablishConnection();
if (this.autoCommit != null) {
dbConn.setAutoCommit(this.autoCommit);
}
this.statement = dbConn.prepareStatement(this.queryTemplate, this.resultSetType, this.resultSetConcurrency);
if (this.fetchSize == -2147483648 || this.fetchSize > 0) {
this.statement.setFetchSize(this.fetchSize);
}
} catch (SQLException var2) {
throw new IllegalArgumentException("open() failed." + var2.getMessage(), var2);
} catch (ClassNotFoundException var3) {
throw new IllegalArgumentException("JDBC-Class not found. - " + var3.getMessage(), var3);
}
}
先说下flink是怎么是如果分批拉取数据的,flink是使用的游标来分批拉取数据,那么这个时候就要确定是否真正使用了游标。
于是乎,我写了一个原生的JDBC程序读取数据的程序(没有限制jvm内存)
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class Main3 {
public static void main(String[] args) {
Connection connection = null;
Runtime runtime = Runtime.getRuntime();
System.out.printf("启动前总内存>%s 使用前的空闲内存>%s 使用前最大内存%s%n", runtime.totalMemory() / 1024 / 1024, runtime.freeMemory() / 1024 / 1024, runtime.maxMemory() / 1024 / 1024);
try {
int i = 0;
connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/xxx?useSSL=false&useInformationSchema=true&nullCatalogMeansCurrent=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useCursorFetch=true", "xxx", "xxx");
connection.setAutoCommit(false);
PreparedStatement preparedStatement = connection.prepareStatement("SELECT `reportid`,\n" +
" `sfzh`,\n" +
" `cjddh`,\n" +
" `cjsj`\n" +
" FROM `gsq_hsjcxx_pre`", ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
// 每批拉取的数据量
preparedStatement.setFetchSize(1024);
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
i++;
}
System.out.printf("启动前总内存>%s 使用前的空闲内存>%s 使用前最大内存%s%n", runtime.totalMemory() / 1024 / 1024, runtime.freeMemory() / 1024 / 1024, runtime.maxMemory() / 1024 / 1024);
System.out.println("数据量> " + i);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (connection != null) {
try {
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
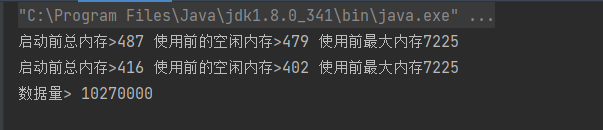
最终打印的结果是

很显然,数据是全部读取出来的,这个时候需要确认的程序是不是真正使用了游标,经过一番查看后发现,需要在jdbc的参数里面加上&useCursorFetch=true,才能使游标生效
修改完jdbc参数之后,问题就得到了完全的结局
除此之外我用过apahce的seatunnel,这个同步数据的时候是真的快,快的离谱。不过使用的时候可能会漏掉一些jdbc相关的参数(MySQL为例)
"rewriteBatchedStatements" : "true" 这个批量的参数 apache seatunnel也不会自动添加的,需要手动加,不然数据就是一条一条插入的,这个坑我也踩了
flink同步MySQL数据的时候出现内存溢出的更多相关文章
- 推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭. 例如:某记录内容为"aaa|bbb|ccc",将其按 ...
- 使用Logstash来实时同步MySQL数据到ES
上篇讲到了ES和Head插件的环境搭建和配置,也简单模拟了数据作测试 本篇我们来实战从MYSQL里直接同步数据 一.首先下载和你的ES对应的logstash版本,本篇我们使用的都是6.1.1 下载后使 ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- Logstash使用jdbc_input同步Mysql数据时遇到的空时间SQLException问题
今天在使用Logstash的jdbc_input插件同步Mysql数据时,本来应该能搜索出10条数据,结果在Elasticsearch中只看到了4条,终端中只给出了如下信息 [2017-08-25T1 ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- logstash增量同步mysql数据到es
本篇本章地址:https://www.cnblogs.com/Thehorse/p/11601013.html 今天我们来讲一下logstash同步mysql数据到es 我认为呢,logstash是众 ...
- logstash使用template提前设置好maping同步mysql数据到Elasticsearch5.5.2
上篇blog说到采用logstash-input-jdbc将mysql数据同步到ES(http://www.cnblogs.com/jstarseven/p/7704893.html),但是这里有一个 ...
- canal同步MySQL数据到ES6.X
背景: 最近一段时间公司做一个技术架构的更改,由于之前使用的solr和目前的业务不太匹配,具体原因不多说啦.所以要把数据放到Elasticsearch中进行快速的搜索,这是便产生了一个数据迁移的需求, ...
- Centos8 部署 ElasticSearch 集群并搭建 ELK,基于Logstash同步MySQL数据到ElasticSearch
Centos8安装Docker 1.更新一下yum [root@VM-24-9-centos ~]# yum -y update 2.安装containerd.io # centos8默认使用podm ...
- flink-cdc同步mysql数据到hive
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的 ...
随机推荐
- 读论文《Distilling the Knowledge in a Neural Network》——蒸馏网络 —— 蒸馏算法 —— 知识蒸馏 中的温度系数到底怎么用, temperature怎么用?
论文地址: https://arxiv.org/pdf/1503.02531.pdf 蒸馏网络的重要公式: 其中,\(p^g\)为Teacher网络,\(q\)为Student网络. 个体神经网络(C ...
- 如何使用H100打游戏——这是史上最快GPU!我们测了四张H100!价值120万元!
资料: 这是史上最快GPU!我们测了四张H100!价值120万元! 对显卡H100的测评视频.
- 纪念IE浏览器退役,哈哈哈!!!
网址: https://haokan.baidu.com/v?pd=wisenatural&vid=16024148879625055169 ========================= ...
- [BJOI2016] IP地址 题解
前言 来个不一样的做法,用到了 Trie 树和主席树,并且是可爱的在线算法. 题目链接:洛谷. 题目分析 对于一个查询 \(\texttt{ip}\),只考虑所有前缀字符串规则.以时间建里横轴,匹配长 ...
- 7月新特性 | 软件开发生产线CodeArts发布多项新特性等你体验!
华为云软件开发生产线CodeArts是一站式.全流程.安全可信的云原生DevSecOps平台,覆盖需求.开发.测试.部署.运维等软件交付全生命周期环节,为开发者打造全云化研发体验.2024年7月,Co ...
- 让你的C程序,可以自动更新版本信息
一.软件管理 稍微上点规模的软件开发往往周期都非常长, 中间会产生很多临时版本, 这些临时版本往往会有各种各样的bug, 由于项目参与的人员众多.水平参差不齐, 软件分支众多.功能复杂, 经常会有各种 ...
- ARMv8-A 地址翻译技术之MMU的前世今生
MMU的重要性不言而喻,支撑操作系统之上的各种复杂应用.但在正式讲MMU之前,我们先说说MMU的发展史,因为ARMv8-A的MMU相当复杂,直接切入正题,会显得比较枯燥.废话不多说,咱们马上开始: 一 ...
- 微信小程序wx.getUserInfo授权获取用户信息(头像、昵称)
这个接口只能获得一些非敏感信息,例如用户昵称,用户头像,经过用户授权允许获取的情况下即可获得用户信息,至于openid这些,需要调取wx.login来获取. index.wxml <!-- 当已 ...
- DMS:直接可微的网络搜索方法,最快仅需单卡10分钟 | ICML 2024
Differentiable Model Scaling(DMS)以直接.完全可微的方式对宽度和深度进行建模,是一种高效且多功能的模型缩放方法.与先前的NAS方法相比具有三个优点:1)DMS在搜索方面 ...
- mfc的ClistCtrl控件列的排序
在网上看了许多排序的方法,都没看懂,初学者的悲剧,然后就自己弄了个,请大家指正. ClistCtrl控件的行带着一个结构体,不过那结构体不好懂,看得眼花缭乱.好多也弄不明白,就自己写了个结构体,把一行 ...