王树森Attention与Self-Attention学习笔记
Seq2Seq + Attention
Seq2Seq模型,有一个Encoder和一个Decoder,默认认为Encoder的输出状态h_m包含整个句子的信息,作为Decoder的输入状态s_0完成整个文本生成过程。这有一个严重的问题就是,最后的状态不能记住长序列,也就是会遗忘信息,那么Decoder也就无法获得此信息。
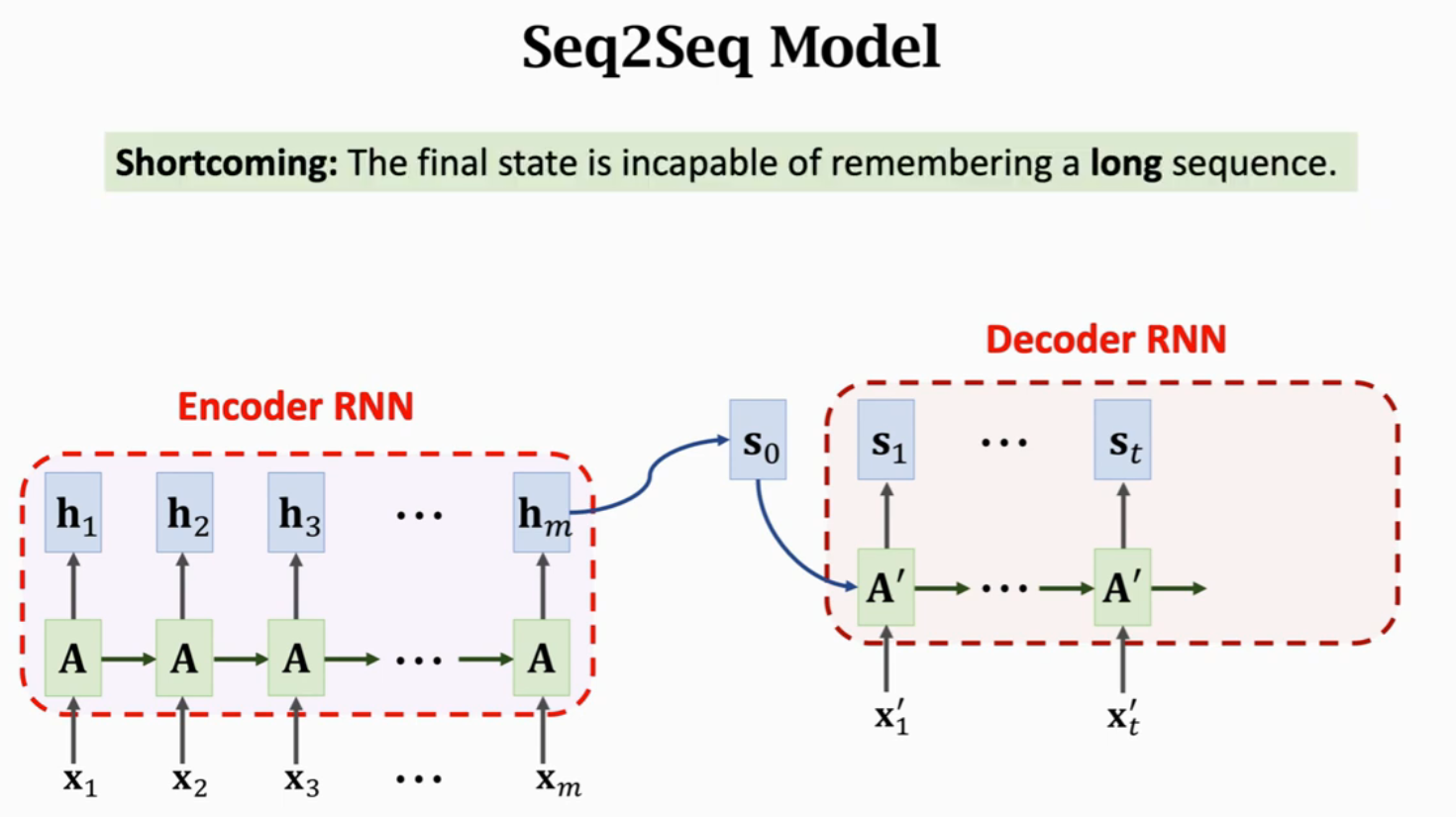
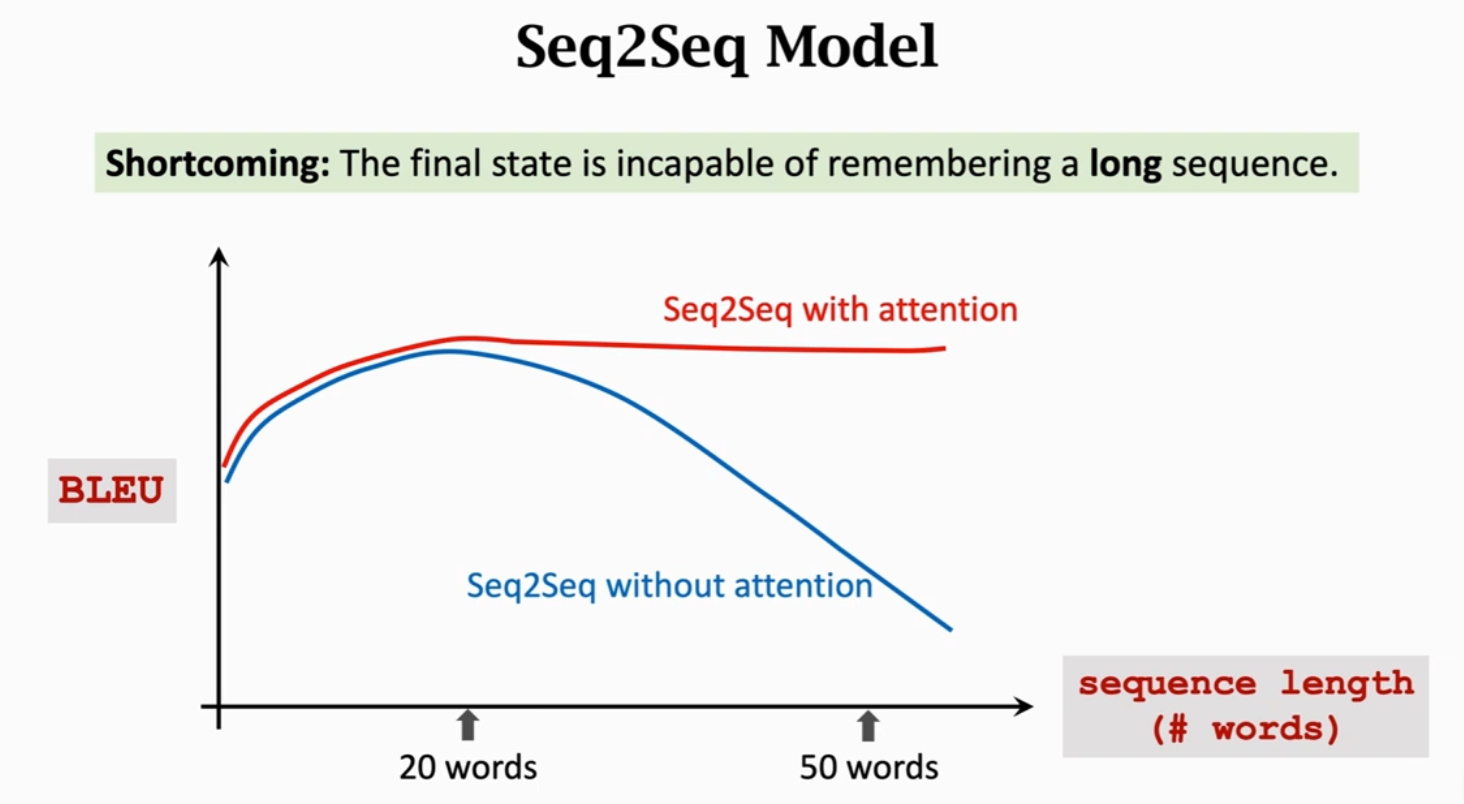
用传统的Seq2Seq模型,当句子长度超过20个单词是,BLEU Score(机器翻译评价指标)就会下降;但是如果用上Attention,就会如下图红色曲线一样,即使输入序列很长也能保持较高的准确率。
使用Attention解决机器翻译的原文为:Bahdanau, Cho, & Bengio, Neural machine translation by jointly learning to align and translate. In ICLR, 2015.
Attention能够极大提升Seq2Seq模型的准确率;用了Attention,Decoder每次更新状态的时候都会看一下Encoder的所有状态,这样子就不会遗忘了;Attention还可以告诉Decoder应该关注Encoder的哪个状态,这就是Attention名字的由来。Attention有一个极大的缺点是,计算量很大。
- Attention tremendously improves Seq2Seq model
- With attention, Seq2Seq model does not forget source input
- With attention, the decoder knows where to focus
- Downside: much more computation
Attention的原理
Attention使用\(c_i\)整合\(h_1, h_2, ..., h_m\)的信息,因此Attention机制可以解决LSTM遗忘的问题。
\(c_0 = \alpha_1h_1 + \alpha_2h_2 + ... + \alpha_mh_m\),其中,\(\alpha_i\)表示\(h_i\)和\(s_0\)的相关性,称为权重。

相关性的计算方法有两种:
方法一(Used in the original paper)
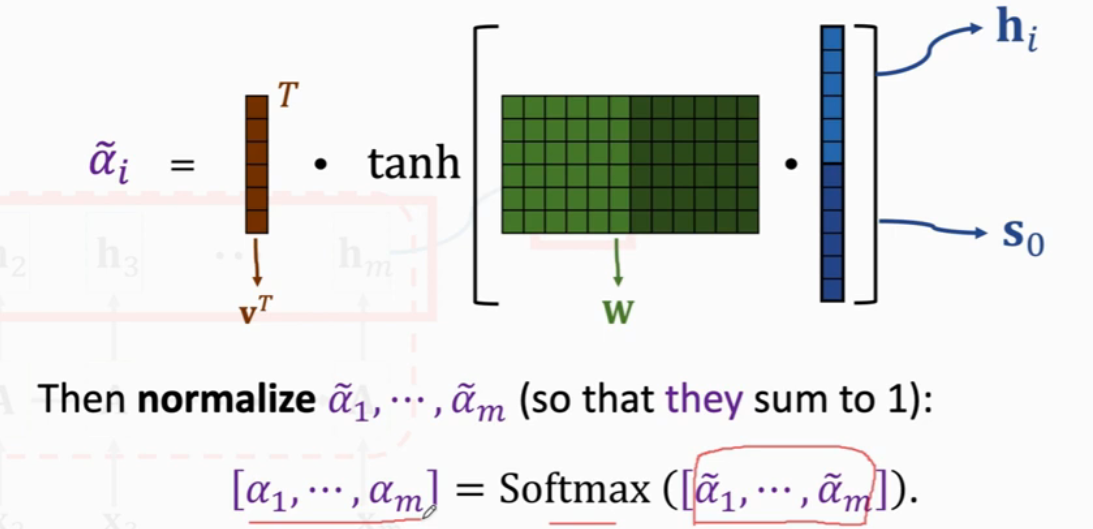
求\(h_i\)和\(s_0\)的相关性,将\(h_i\)和\(s_0\)进行Concatenate,然后乘一个参数矩阵\(W\),结果进行\(tanh\)约束到(-1, 1)之间,然后再乘以一个\(v^T\),并对得到的结果进行Softmax处理。
方法二(more popular,the same to Transformer)
求\(h_i\)和\(s_0\)的相关性,分为三步进行计算:
- Linear maps
- \(k_i = W_K · h_i\)
- \(q_0 = W_Q · s_0\)
- Inner product
- \(\widetilde{\alpha_i} = k^T_{i}q_0\)
- Normalization
- \([\alpha_1, ..., \alpha_m] = Softmax([\widetilde{\alpha_1}, ... \widetilde{\alpha_m}])\)
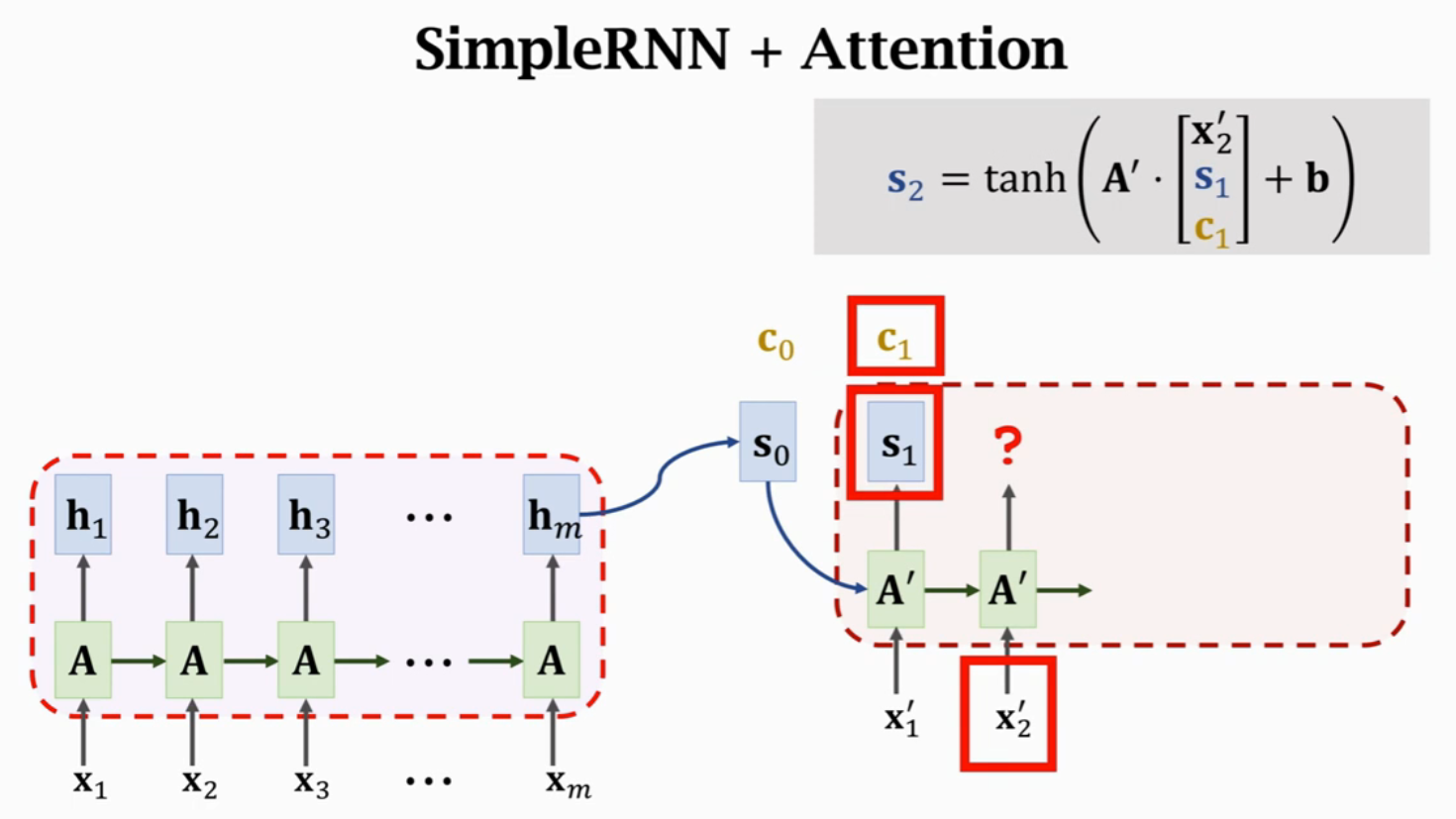
计算得到\(c_0\)后,将\(A'\)的三个输入进行concatenate,作为输入得到状态\(s_1\)。每一个状态\(s_i\)对应一个Context向量\(c_i\)来表示\(s_i\)与\(H\)的相关性。
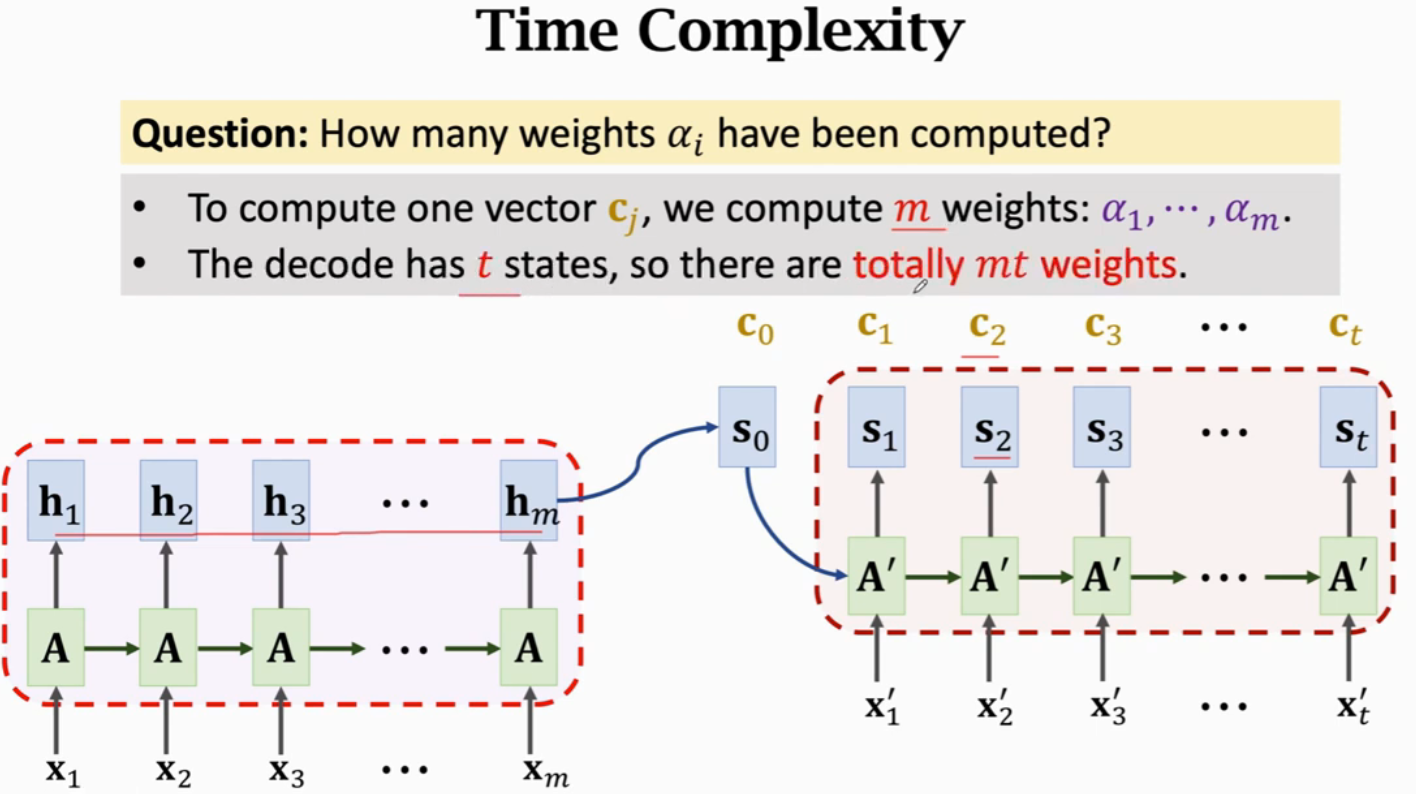
假设Encoder有m步,Decoder有t步,就需要计算mt次权重,每次权重计算都要计算m个\(\alpha\)的值。所以,Attention的时间复杂度是mt,也就是Encoder和Decoder状态数量的乘积。
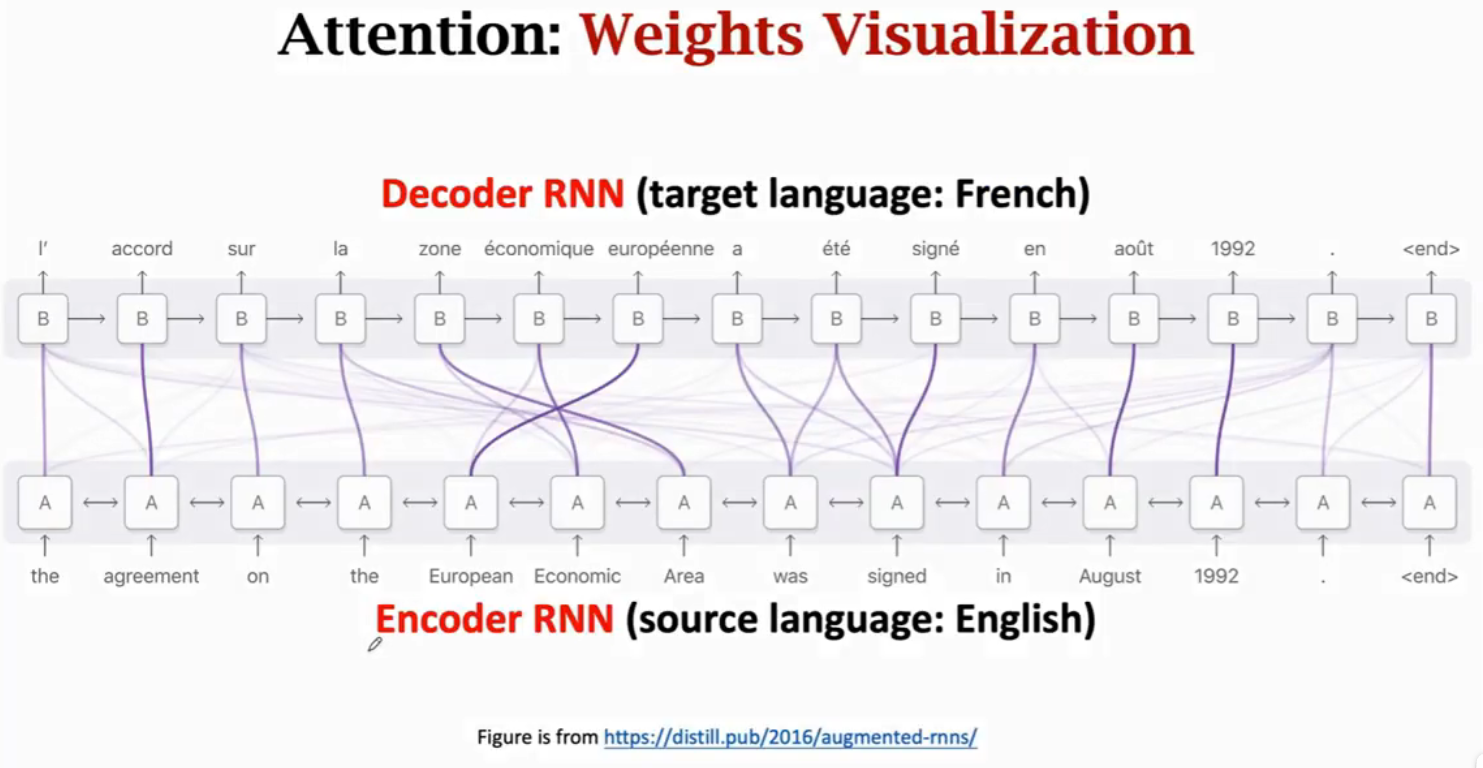
Attention在机器翻译任务的可视化,可以看到Decoder与Encoder的每个状态都相关,但是会重点关注某个或某些状态。
Summary
优点:
- Standard Seq2Seq model:decoder只关注其当前状态
- Attention:decoder还会关注encoders的所有状态解决遗忘问题并且告诉decoder哪里需要重点关注
缺点:高时间复杂度(假设源序列的长度为m,目标序列的长度是t)
- Standard Seq2Seq:\(O(m + t)\)
- Seq2Seq + attention:\(O(mt)\)
Self Attention
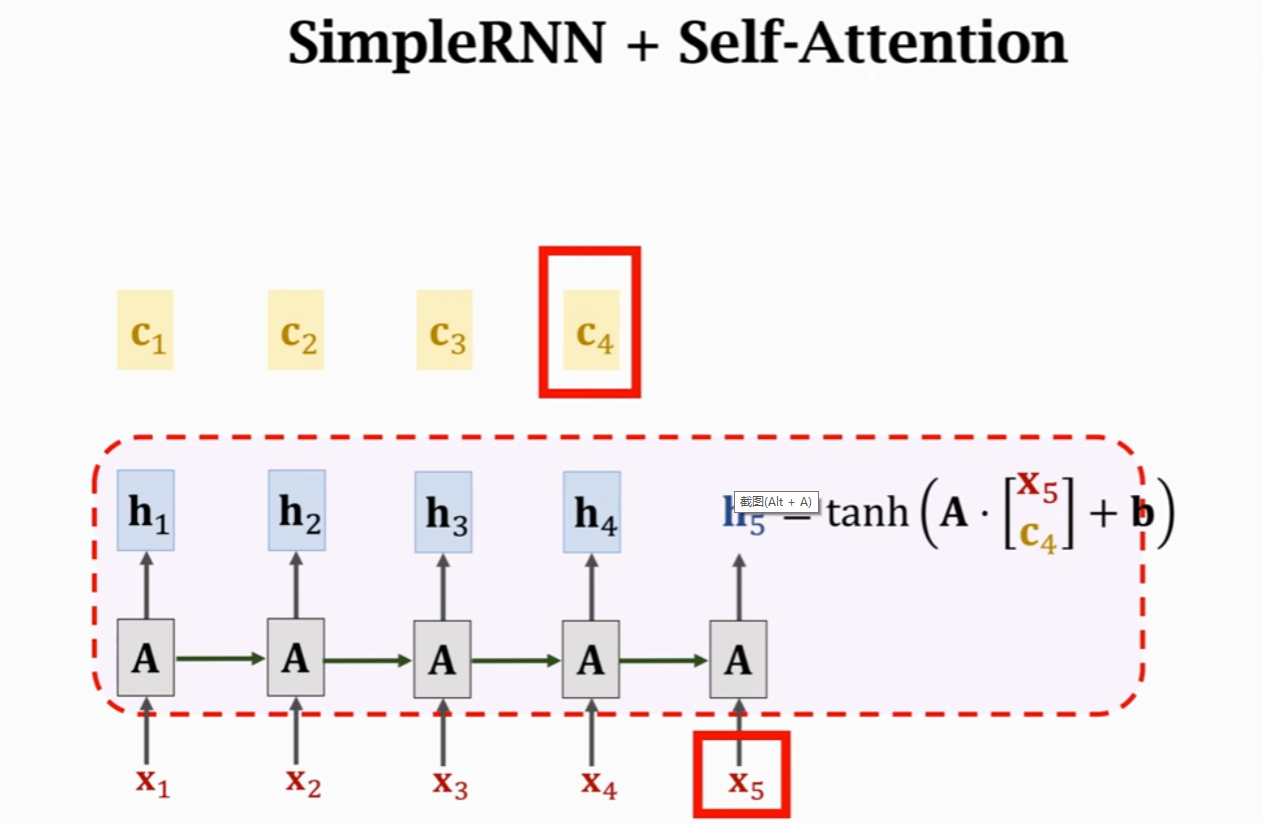
之前RNN里面,使用\(h_4\)和\(x_5\)计算得到\(h_5\),使用self-attention机制,当前状态\(h_5\)的计算依赖由\(h_4\)变为\(c_4\)。\(c_4 = \alpha_1h_1 + \alpha_2h_2 + \alpha_3h_3 + \alpha_4h_4\),其中,\(\alpha_i\)计算的是\(h_4\)与\(h_i\)之间的相关性,计算方式前面已经讲过。因为这里会计算自己与自己的相关性,因此称为self-attention。
SimpleRNN与Attention当前状态计算对比
SimpleRNN状态\(h_5\)的计算:
\(h_5 = tanh(A·{x_5\brack h_4} + b)\)
Self-Attention状态\(h_5\)的计算:
\(h_5 = tanh(A·{x_5\brack c_4} + b)\)
Reference
王树森Attention与Self-Attention学习笔记的更多相关文章
- 王树森Transformer学习笔记
目录 Transformer Attention结构 Self-Attention结构 Multi-head Self-Attention BERT:Bidirectional Encoder Rep ...
- SQL反模式学习笔记3 单纯的树
2014-10-11 在树形结构中,实例被称为节点.每个节点都有多个子节点与一个父节点. 最上层的节点叫做根(root)节点,它没有父节点. 最底层的没有子节点的节点叫做叶(leaf). 中间的节点简 ...
- SQL反模式学习笔记9 元数据分裂
目标:支持可扩展性.优化数据库的结构来提升查询的性能以及支持表的平滑扩展. 反模式:克隆表与克隆列 1.将一张很长的表拆分成多张较小的表,使用表中某一个特定的数据字段来给这些拆分出来的表命名. 2.将 ...
- SQL反模式学习笔记1 开篇
什么是“反模式” 反模式是一种试图解决问题的方法,但通常会同时引发别的问题. 反模式分类 (1)逻辑数据库设计反模式 在开始编码之前,需要决定数据库中存储什么信息以及最佳的数据组织方式和内在关联方式. ...
- SQL反模式学习笔记5 外键约束【不用钥匙的入口】
目标:简化数据库架构 一些开发人员不推荐使用引用完整性约束,可能不使用外键的原因有一下几点: 1.数据更新有可能和约束冲突: 2.当前的数据库设计如此灵活,以至于不支持引用完整性约束: 3.数据库为外 ...
- SQL反模式学习笔记2 乱穿马路
程序员通常使用逗号分隔的列表来避免在多对多的关系中创建交叉表, 将这种设计方式定义为一种反模式,称为“乱穿马路”. 目标: 存储多属性值,即多对一 反模式:将多个值以格式化的逗号分隔存储在一个字段中 ...
- SQL反模式学习笔记4 建立主键规范【需要ID】
目标:建立主键规范 反模式:每个数据库中的表都需要一个伪主键Id 在表中,需要引入一个对于表的域模型无意义的新列来存储一个伪值,这一列被用作这张表的主键, 从而通过它来确定表中的一条记录,即便其他的列 ...
- SQL反模式学习笔记6 支持可变属性【实体-属性-值】
目标:支持可变属性 反模式:使用泛型属性表.这种设计成为实体-属性-值(EAV),也可叫做开放架构.名-值对. 优点:通过增加一张额外的表,可以有以下好处 (1)表中的列很少: (2)新增属性时,不需 ...
- SQL反模式学习笔记7 多态关联
目标:引用多个父表 反模式:使用多用途外键.这种设计也叫做多态关联,或者杂乱关联. 多态关联和EAV有着相似的特征:元数据对象的名字是存储在字符串中的. 在多态关联中,父表的名字是存储在Issue_T ...
- SQL反模式学习笔记8 多列属性
目标:存储多值属性 反模式:创建多个列.比如一个人具有多个电话号码.座机号码.手机号码等. 1.查询:多个列的话,查询时可能不得不用IN,或者多个OR: 2.添加.删除时确保唯一性.判断是否有值:这些 ...
随机推荐
- 代码随想录Day5
242.有效的字母异位词 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词. 注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词. 示例 ...
- 微服务全链路跟踪:jaeger集成hystrix
微服务全链路跟踪:grpc集成zipkin 微服务全链路跟踪:grpc集成jaeger 微服务全链路跟踪:springcloud集成jaeger 微服务全链路跟踪:jaeger集成istio,并兼容u ...
- Maven经验分享(八)maven去除jar报依赖
又是项目总结的时候了,说一下maven使用中遇到的问题以及解决方案. 在新项目的开发中,使用maven进行持续构建,在搭建框架的过程中经常遇到jar冲突的问题,现在来介绍下如何去除jar传递依赖. 1 ...
- [CSP-S 2023] 消消乐 & CF1223F 题解
LG9753 CF1223F 我们称一个字符串是可消除的,当且仅当可以对这个字符串进行若干次操作,使之成为一个空字符串.其中每次操作可以从字符串中删除两个相邻的相同字符,操作后剩余字符串会拼接在一起. ...
- echarts x轴下绘制表
效果图: 把下面代码复制到官网实例的js代码编辑中即可预览( 附连接:Examples - Apache ECharts) let map = { 销售单价: [2200.0,4000.9,700.0 ...
- 全网最适合入门的面向对象编程教程:41 Python 常用复合数据类型-队列(FIFO、LIFO、优先级队列、双端队列和环形队列)
全网最适合入门的面向对象编程教程:41 Python 常用复合数据类型-队列(FIFO.LIFO.优先级队列.双端队列和环形队列) 摘要: 在 Python 中,队列(Queue)是一种常用的数据结构 ...
- 一文剖析TCP三次握手、四次挥手
TCP三次握手四次挥手 问题 TCP建立连接为什么是三次握手,而不是两次或四次? TCP,名为传输控制协议,是一种可靠的传输层协议,IP协议号为6. 顺便说一句,原则上任何数据传输都无法确保绝对可靠, ...
- Android Studio 项目已经sync完成,但是在布局中显示:Design editor is unavaliable until after a sunncessful project sync
原因:在drawable文件夹中新增了一个png图标 解决:同步在drawable-v24文件中复制一份即可
- compileSdkVersion, minSdkVersion 和 targetSdkVersion,傻傻分不清楚【转】
原文 https://blog.csdn.net/gaolh89/article/details/79809034 在Android Studio项目的app/build.gradle中,我们可以看到 ...
- 6.2 XXE和XML利用
pikaqu靶场xml数据传输测试-有回显,玩法,协议,引入 1.构造payload 写文件 <?xml version="1.0" encoding="UTF-8 ...