论文解读()《Cluster Alignment with a Teacher for Unsupervised Domain Adaptation》
Note:[ wechat:Y466551 | 付费咨询,非诚勿扰 ]
论文信息
论文标题:Cluster Alignment with a Teacher for Unsupervised Domain Adaptation
论文作者:Zhijie Deng, Yucen Luo, Jun Zhu
论文来源:2020 ICCV
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
2 方法
2.1 模型框架
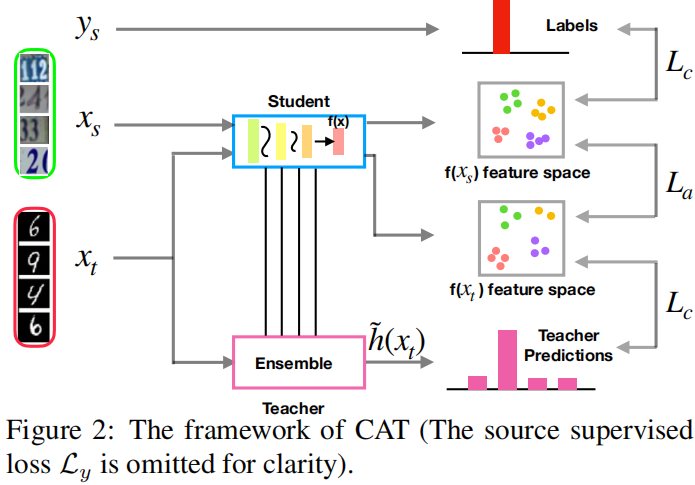
2.2 Cluster Alignment with a Teacher
目标:discriminative learning 和 class-conditional alignment between domains?
$\min _{\theta} \mathcal{L}_{y}+\alpha\left(\mathcal{L}_{c}+\mathcal{L}_{a}\right) \quad(1)$
2.2.1 Discriminative clustering with a teacher
目标函数:
$\mathcal{L}_{c}\left(\mathcal{X}_{s}, \mathcal{X}_{t}\right)=\mathcal{L}_{c}\left(\mathcal{X}_{s}\right)+\mathcal{L}_{c}\left(\mathcal{X}_{t}\right)$
$\begin{aligned}\mathcal{L}_{c}(\mathcal{X})= \frac{1}{|\mathcal{X}|^{2}} \sum_{i=1}^{|\mathcal{X}|} \sum_{j=1}^{|\mathcal{X}|}\left[\delta_{i j} d\left(f\left(x^{i}\right), f\left(x^{j}\right)\right)+\right.\left.\left(1-\delta_{i j}\right) \max \left(0, m-d\left(f\left(x^{i}\right), f\left(x^{j}\right)\right)\right)\right]\end{aligned}$
其中 ,$\delta_{i j}$ 代表样本 $x_i$ 和 样本 $x_j$ 是不是同一类;
Note:目标域样本的标签(伪)由 教师分类器给出;
Note:可能会怀疑,教师分类器的错误预测是否会破坏训练的动态。然而,先前关于半监督学习[17,43]的研究已经验证了这种训练总是能导致良好的收敛性,并证明了对不正确标签的鲁棒性。
2.2.2 Cluster alignment via conditional feature matching
类条件特征对齐:
$\min _{\theta} \mathcal{D}\left(\mathcal{F}_{s, k} \| \mathcal{F}_{t, k}\right)$
其中,$\mathcal{F}_{s, k}\left(\mathcal{F}_{t, k}\right) $ 表示由属于源域(目标域)的类 $k$ 的所有特征组成的集合。
$\mathcal{L}_{a}\left(\mathcal{X}_{s}, \mathcal{Y}_{s}, \mathcal{X}_{t}\right)=\frac{1}{K} \sum_{k=1}^{K}\left\|\lambda_{s, k}-\lambda_{t, k}\right\|_{2}^{2}$
$\lambda_{t, k}=\frac{1}{\left|\mathcal{X}_{t, k}\right|} \sum_{x_{t}^{i} \in \mathcal{X}_{t, k}} f\left(x_{t}^{i}\right)$
2.3 Improved marginal distribution alignment
最后作者还做了一些提高,这是因为实验观察到:一开始训练的时候,teacher 对于目标域的判断并不果断,即分类结果更多聚集在分类边界附近,而不是类别中心。
目标函数:
$\begin{array}{c}\min _{\theta} \max _{\phi} \mathcal{L}_{d}\left(\mathcal{X}_{s}, \mathcal{X}_{t}\right)=\frac{1}{N} \sum_{i=1}^{N}\left[\log c\left(f\left(x_{s}^{i} ; \theta\right) ; \phi\right)\right]+ \frac{1}{\tilde{M}} \sum_{i=1}^{\tilde{M}}\left[\log \left(1-c\left(f\left(x_{t}^{i} ; \theta\right) ; \phi\right)\right) \gamma_{i}\right]\end{array}$
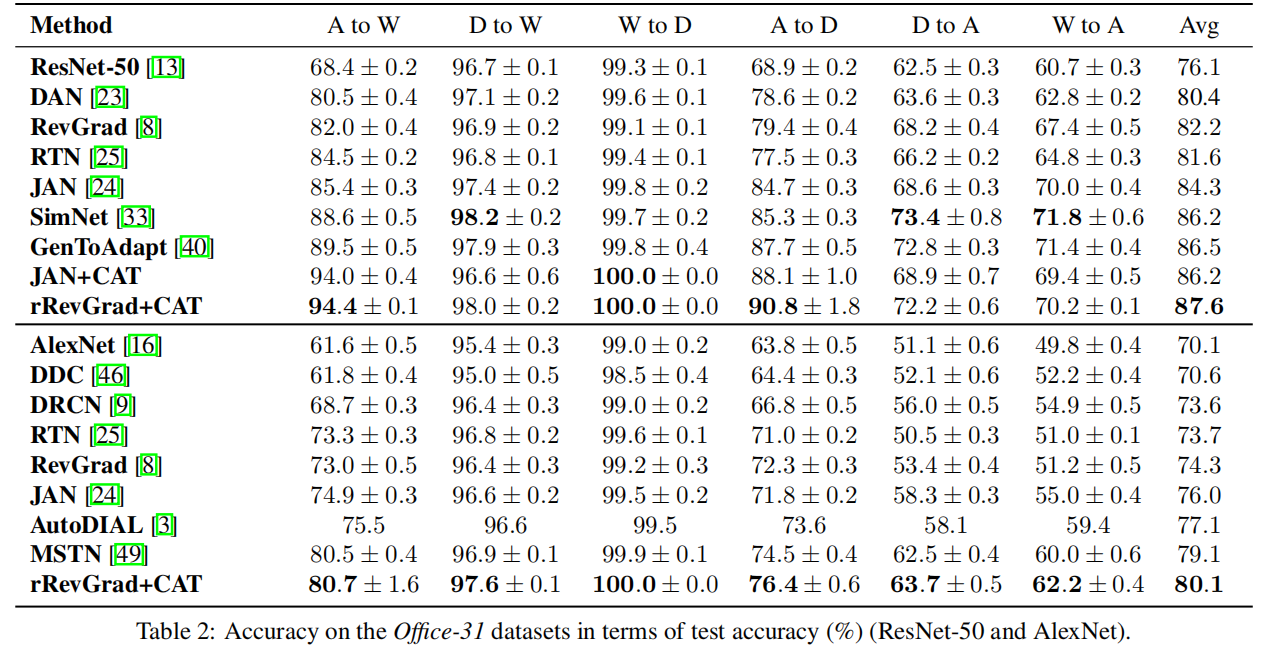
3 实验
论文解读()《Cluster Alignment with a Teacher for Unsupervised Domain Adaptation》的更多相关文章
- 《Population Based Training of Neural Networks》论文解读
很早之前看到这篇文章的时候,觉得这篇文章的思想很朴素,没有让人眼前一亮的东西就没有太在意.之后读到很多Multi-Agent或者并行训练的文章,都会提到这个算法,比如第一视角多人游戏(Quake ...
- ImageNet Classification with Deep Convolutional Neural Networks 论文解读
这个论文应该算是把深度学习应用到图片识别(ILSVRC,ImageNet large-scale Visual Recognition Challenge)上的具有重大意义的一篇文章.因为在之前,人们 ...
- 《Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks》论文笔记
论文题目<Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Ne ...
- Quantization aware training 量化背后的技术——Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
1,概述 模型量化属于模型压缩的范畴,模型压缩的目的旨在降低模型的内存大小,加速模型的推断速度(除了压缩之外,一些模型推断框架也可以通过内存,io,计算等优化来加速推断). 常见的模型压缩算法有:量化 ...
- Training Deep Neural Networks
http://handong1587.github.io/deep_learning/2015/10/09/training-dnn.html //转载于 Training Deep Neural ...
- Training (deep) Neural Networks Part: 1
Training (deep) Neural Networks Part: 1 Nowadays training deep learning models have become extremely ...
- [CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- Training spiking neural networks for reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 原文链接:https://arxiv.org/pdf/2005.05941.pdf Contents: Abstract Introduc ...
- CVPR 2018paper: DeepDefense: Training Deep Neural Networks with Improved Robustness第一讲
前言:好久不见了,最近一直瞎忙活,博客好久都没有更新了,表示道歉.希望大家在新的一年中工作顺利,学业进步,共勉! 今天我们介绍深度神经网络的缺点:无论模型有多深,无论是卷积还是RNN,都有的问题:以图 ...
- 论文翻译:BinaryConnect: Training Deep Neural Networks with binary weights during propagations
目录 摘要 1.引言 2.BinaryConnect 2.1 +1 or -1 2.2确定性与随机性二值化 2.3 Propagations vs updates 2.4 Clipping 2.5 A ...
随机推荐
- 从七个方面聊聊linux到底强在哪
从事计算机相关行业的同学不难发现,身边总有一些朋友在学习linux,有的开发同学甚至自己的电脑就是它.经常听他们说linux如何好用等等.那么linux到底好在那里,能让大家如此喜欢.这也是我经常问自 ...
- Django transaction.atomic 事务的使用
函数 transaction.atomic 数据库的读写操作中,事务在保证数据的安全性和一致性方面起着关键的作用,而回滚正是这里面的核心操作. 遇到并发的时候常常会因为接口的访问顺序或者其他情况,导致 ...
- 2020-12-04:mysql 表中允许有多少个 TRIGGERS?
福哥答案2020-12-04: 在 Mysql 表中允许有六个触发器,如下:BEFORE INSERTAFTER INSERTBEFORE UPDATEAFTER UPDATEBEFORE DELET ...
- 火山引擎DataTester:A/B实验平台数据集成技术分享
DataTester的数据集成系统,可大幅降低企业接入A/B实验平台门槛. 当企业想要接入一套A/B实验平台的时候,常常会遇到这样的问题: 企业已经有一套埋点系统了,增加A/B实验平台的话需要重复 ...
- Sql Server维护计划事务日志找不到目标数据库
1.发现事务日志备份突然停止了 2.查看维护计划中的事务日志设置 3.发现备份任务中,事务日志需要指向的数据库不在 4.进入数据库属性 5.在选项中将恢复模式改为"完整"
- Python-3.10安装步骤
下载地址: https://www.python.org/ftp/python/3.10.4/python-3.10.4-amd64.exe 安装: C:\Users\liujun>pyth ...
- 小H分糖果
7-5 小H分糖果 (20 分) 小H来到一个小学分糖果,小学生们很听话,站成一排等着分糖果,小H将根据每个人的上次考试分数给一定的糖果,规则如下. 每个人都有自己分数ai,代表上次考试成绩. 每个 ...
- 03. 选择器补充及CSS动画
1.了解frameset 2.iframe html5新特性 iframe 元素会创建包含另外一个文档的内联框架(即行内框架). 提示:您可以把需要的文本放置在 <iframe> 和 &l ...
- Google Chrome 超详细使用教程
由于微信不允许外部链接,你需要点击文章尾部左下角的 "阅读原文",才能访问文中的链接. 调查统计机构 NetMarketShare 发布最新的 7 月份报告,在全球浏览器市场,谷歌 ...
- http_basic认证(401)爆破
Http Basic认证(401)爆破 hydra,burpsuit 在thm:https://tryhackme.com/room/toolsrus 遇到了这个问题,但这个用的工具是hydra,想起 ...