微软真是活菩萨,面向初学者的机器学习、数据科学、AI、LLM课程统统免费
微软真是活菩萨,面向初学者的机器学习、数据科学、AI、LLM课程统统免费
大家好,我是老章
推荐几个质量上乘且完全免费的微软开源课程
面向初学者的机器学习课程

地址:https://microsoft.github.io/ML-For-Beginners/#/
学习经典机器学习,主要使用 Scikit-learn 作为库,本课程不涉及深度学习,这部分会在后面介绍的“初学者人工智能”课程中涉及,本课程与第二部分的面向初学者的数据科学课程是姐妹篇。
课程大纲:
| 课号 | 话题 | 课程分组 | 学习目标 |
|---|---|---|---|
| 01 | 机器学习简介 | 介绍 | 了解机器学习背后的基本概念 |
| 02 | 机器学习的历史 | 介绍 | 了解该领域的历史 |
| 03 | 公平与机器学习 | 介绍 | 学生在构建和应用机器学习模型时应该考虑哪些关于公平的重要哲学问题? |
| 04 | 机器学习技术 | 介绍 | 机器学习研究人员使用哪些技术来构建机器学习模型? |
| 05 | 回归简介 | 回归 | 开始使用 Python 和 Scikit-learn 构建回归模型 |
| 06 | 北美南瓜价格 | 回归 | 可视化和清理数据,为机器学习做好准备 |
| 07 | 北美南瓜价格 | 回归 | 建立线性和多项式回归模型 |
| 08 | 北美南瓜价格 | 回归 | 构建逻辑回归模型 |
| 09 | 网络应用程序 | 网页应用程序 | 构建一个网络应用程序来使用您训练过的模型 |
面向初学者的数据科学课程

地址:https://microsoft.github.io/Data-Science-For-Beginners/#/
为期 10 周、20 课时的数据科学课程,每节课都包括课前和课后测验,学习数据科学的基本原理,包括道德概念、数据准备、处理数据的不同方式、数据可视化、数据分析、数据科学的实际用例等等。
课程大纲:
| 课号 | 话题 | 课程分组 | 学习目标 |
|---|---|---|---|
| 01 | 定义数据科学 | 介绍 | 了解数据科学背后的基本概念以及它与人工智能、机器学习和大数据的关系 |
| 02 | 数据科学伦理 | 介绍 | 数据伦理概念、挑战和框架 |
| 03 | 定义数据 | 介绍 | 数据如何分类及其常见来源 |
| 04 | 统计与概率概论 | 介绍 | 用于理解数据的概率和统计数学 |
| 05 | 使用关系数据 | 处理数据 | 关系数据简介以及使用结构化查询语言( SQL)探索和分析关系数据的基础知识 |
| 06 | 使用 NoSQL 数据 | 处理数据 | 介绍非关系数据、其各种类型以及探索和分析文档数据库的基础知识 |
| 07 | 使用Python | 处理数据 | 使用 Python 通过 Pandas 等库进行数据探索的基础知识,建议对 Python 编程有基本的了解 |
| 08 | 数据准备 | 处理数据 | 有关清理和转换数据以应对数据丢失、不准确或不完整的挑战的数据技术的主题 |
| 09 | 可视化数量 | 数据可视化 | 了解如何使用 Matplotlib 可视化鸟类数据 |
值得一提的是,本课程还配套了很多高清手绘风格的章节总结:

面向初学者的AI课程
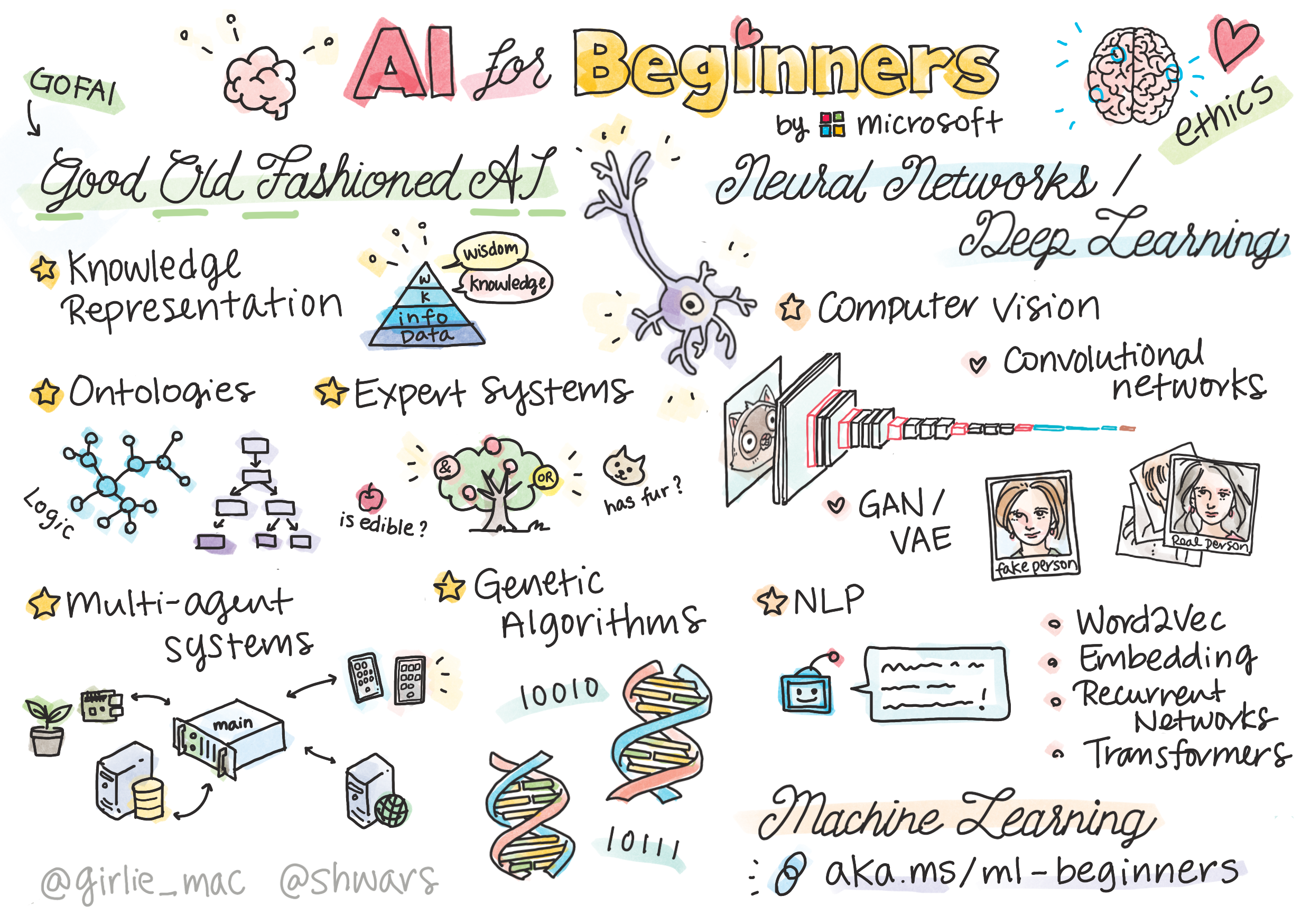
地址:https://microsoft.github.io/AI-For-Beginners/
在本课程中,将学习:
- 人工智能的不同方法,包括带有知识表示和推理的“古老”符号方法(GOFAI)。
- 神经网络和深度学习是现代人工智能的核心,使用两个最流行的框架(TensorFlow和PyTorch)中的代码来说明这些重要主题背后的概念。
- 用于处理图像和文本的**神经架构,介绍最新的模型
- 不太流行的人工智能方法,例如遗传算法和多代理系统。
每节课都包含一些预读材料和一些可执行的 Jupyter Notebook,它们通常特定于框架(PyTorch或TensorFlow)。
面向初学者的生成式人工智能

地址:https://microsoft.github.io/generative-ai-for-beginners
通过 12 课时综合课程,了解构建生成式 AI 应用程序的基础知识。
课程大纲
| 概念 | 学习目标 | ||
|---|---|---|---|
| 00 | 课程简介 - 如何学习本课程 | 技术设置和课程结构 | 在学习本课程的同时帮助您取得成功 |
| 01 | 生成式人工智能和法学硕士简介 | 概念:生成式人工智能和当前的技术前景 | 了解什么是生成式 AI 以及大型语言模型 (LLM) 的工作原理。 |
| 02 | 探索和比较不同的法学硕士 | 概念:测试、迭代和比较不同的大型语言模型 | 为您的使用案例选择正确的型号 |
| 03 | 负责任地使用生成式人工智能 | 概念:了解基础模型的局限性和人工智能背后的风险 | 了解如何负责任地构建生成式人工智能应用程序 |
| 04 | 了解快速工程基础知识 | 代码/概念:即时工程最佳实践的实际应用 | 了解提示结构和用法 |
| 05 | 创建高级提示 | 代码/概念:通过在提示中应用不同的技术来扩展您的提示工程知识 | 应用提示工程技术来改善提示结果。 |
| 06 | 构建文本生成应用程序 | 代码:使用 Azure OpenAI 构建文本生成应用程序 | 了解如何有效地使用令牌和温度来改变模型的输出 |
| 07 | 构建聊天应用程序 | 代码:有效构建和集成聊天应用程序的技术。 | 确定关键指标和注意事项,以有效监控和维护人工智能聊天应用程序的质量 |
| 08 | 构建搜索应用程序矢量数据库 | 代码:语义搜索与关键字搜索。了解文本嵌入及其如何应用于搜索 | 创建一个使用嵌入来搜索数据的应用程序。 |
| 09 | 构建图像生成应用程序 | 代码:图像生成以及为什么它在构建应用程序中很有用 | 构建图像生成应用程序 |
| 10 | 构建低代码人工智能应用程序 | 低代码: Power Platform 中的生成式 AI 简介 | 使用低代码为我们的教育初创公司构建学生作业跟踪应用程序 |
| 11 | 将外部应用程序与函数调用集成 | 代码:什么是函数调用及其应用程序用例 | 设置函数调用以从外部 API 检索数据 |
| 12 | 为人工智能应用程序设计用户体验 | 概念:设计人工智能应用以实现信任和透明 | 开发生成式人工智能应用程序时应用用户体验设计原则 |
微软真是活菩萨,面向初学者的机器学习、数据科学、AI、LLM课程统统免费的更多相关文章
- 程序员用于机器学习数据科学的3个顶级 Python 库
NumPy NumPy(数值 Python 的简称)是其中一个顶级数据科学库,它拥有许多有用的资源,从而帮助数据科学家把 Python 变成一个强大的科学分析和建模工具.NumPy 是在 BSD 许可 ...
- 学习《精通数据科学从线性回归到深度学习》PDF+代码分析
数据科学内容广泛,涉及到统计分析.机器学习以及计算机科学三方面的知识和技能.学习数据科学,推荐学习<精通数据科学从线性回归到深度学习>. 针对技术书籍,最好的阅读方法是对照每一章的示例代码 ...
- ApacheCN 编程/大数据/数据科学/人工智能学习资源 2019.12
公告 我们的所有非技术内容和活动,从现在开始会使用 iBooker 这个名字. "开源互助联盟"已终止,我们对此表示抱歉和遗憾.除非特地邀请,我们不再推广他人的任何项目. 公众号自 ...
- 布客·ApacheCN 编程/大数据/数据科学/人工智能学习资源 2020.2
特约赞助商 公告 我们愿意普及区块链技术,但前提是互利互惠.我们有大量技术类学习资源,也有大量的人需要这些资源.如果能借助区块链技术存储和分发,我们就能将它们普及给我们的受众. 我们正在招募项目负责人 ...
- 布客·ApacheCN 编程/大数据/数据科学/人工智能学习资源 2020.1
公告 我们正在招募项目负责人,完成三次贡献可以申请,请联系片刻(529815144).几十个项目等你来申请和参与,不装逼的朋友,我们都不想认识. 薅资本主义羊毛的 CDNDrive 计划正式启动! 我 ...
- 布客·ApacheCN 编程/大数据/数据科学/人工智能学习资源 2020.4
公告 我们的机器学习群(915394271)正式改名为财务提升群,望悉知. 请关注我们的公众号"ApacheCN",回复"教程/路线/比赛/报告/技术书/课程/轻小说/漫 ...
- 微软BI SSRS 2012 Metro UI Win 8 风格的报表课程案例全展示
开篇介绍 微软BI SSRS 2012 Metro UI 高端报表视频教程 (http://www.hellobi.com/course/15)课程从2014年6月开始准备,于2014年9月在 天善B ...
- 微软Connect(); 2017大会梳理:Azure、数据、AI开发工具
在今天召开的 Connect(); 2017 开发者大会上,微软宣布了 Azure.数据.AI 开发工具的内容.这是第一天的 Connect(); 2017 的主题演讲. 在开场视频中霍金又来了.你记 ...
- 用于数据科学的顶级 C/C++ 机器学习库整理
用于数据科学的顶级 C/C++ 机器学习库整理 介绍和动机--为什么选择 C++ C++ 非常适合 动态负载平衡. 自适应缓存以及开发大型大数据框架 和库.Google 的MapReduce.Mong ...
- 数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics)之间有什么关系?
本来我以为不需要解释这个问题的,到底数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)有什么区别,但是前几天因为有个学弟问我,我想了想发现我竟然也回答 ...
随机推荐
- warning in ./src/router/index.js (Emitted value instead of an instance of Error) Error compiling template: Uncaught (in promise) TypeError: Cannot set properties of undefined (setting 'jsoninfo'
目录 warning in ./src/router/index.js (Emitted value instead of an instance of Error) Error compiling ...
- SQL函数union,union all整理
SQL集合函数--并集union,union all 本次整理从4个方面展示union函数,union all函数的风采: 1.集合函数使用规则 2.集合函数作用 3.数据准备及函数效果展示 首先1. ...
- 爬虫系列——selenium
文章目录 一 介绍 二 安装 三 基本使用 四 选择器 五 等待元素被加载 六 元素交互操作 七 其他 八 项目练习 一 介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决r ...
- 如何提高redux开发效率?当然是redux-tookit啦!
前言 使用react-redux的朋友都经历过这种痛苦吧? 定义一个store仓库,首先创建各种文件,比如reducer.action.store...,然后 将redux和react连接使用.整个流 ...
- Travelling Salesman and Special Numbers
prologue 模拟赛的一道题,结果没做出来,丢大人,败大兴.所以过来糊一篇题解. analysis 我们看到数据范围这么大,那么肯定不可以一个一个遍历(废话),所以就要考虑这个题目的性质. 我们先 ...
- ExcelPatternTool 开箱即用的Excel工具包现已发布!
目录 ExcelPatternTool 功能 特点: 快速开始 使用说明 常规类型 高级类型 Importable注解 Exportable注解 IImportOption导入选项 IExportOp ...
- 自定义过滤器配置 Shiro 认证失败返回 json 数据
by emanjusaka from https://www.emanjusaka.top/archives/11 彼岸花开可奈何 本文欢迎分享与聚合,全文转载请留下原文地址. Shiro权限框架 ...
- jenkins实践篇(2)—— 自动打tag的可回滚发布模式
大家好,我是蓝胖子,在上一篇我简单介绍了如何基于特定分支做自动编译和发布,在生产环境中,为了更加安全和快速回滚,我采取的是通过对代码打tag的方式来进行部署,下面我将详细介绍整个发布过程的逻辑. 发布 ...
- Lazyload 延迟加载效果(转)
http://www.cnblogs.com/cloudgamer/archive/2010/02/01/LazyLoad.html Lazyload是通过延迟加载来实现按需加载,达到节省资源,加快浏 ...
- [Python急救站课程]正方形螺旋线的绘制
正方形螺旋线的绘制 import turtle turtle.speed('fastest') # 加快画笔速度 length = 3 # 正方形边长 angle = 90 # 转向角度 for i ...