[转帖]使用 Grafana 监控 TiDB 的最佳实践
https://docs.pingcap.com/zh/tidb/stable/grafana-monitor-best-practices
使用 TiUP 部署 TiDB 集群时,如果在拓扑配置中添加了 Grafana 和 Prometheus,会部署一套 Grafana + Prometheus 的监控平台,用于收集和展示 TiDB 集群各个组件和机器的 metric 信息。本文主要介绍使用 TiDB 监控的最佳实践,旨在帮助 TiDB 用户高效利用丰富的 metric 信息来分析 TiDB 的集群状态或进行故障诊断。
监控架构
Prometheus 是一个拥有多维度数据模型和灵活查询语句的时序数据库。Grafana 是一个开源的 metric 分析及可视化系统。
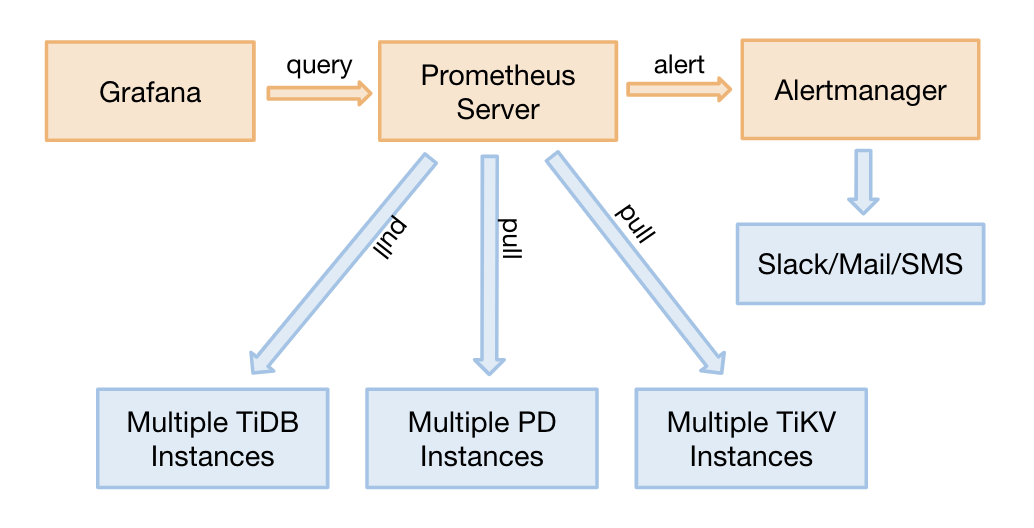
从 TiDB 2.1.3 版本开始,监控可以支持 pull,这是一个非常好的调整,它有以下几个优点:
- 如果 Prometheus 需要迁移,无需重启整个 TiDB 集群。调整前,因为组件要调整 push 的目标地址,迁移 Prometheus 需要重启整个集群。
- 支持部署 2 套独立的 Grafana + Prometheus 的监控平台(非 HA),防止监控的单点。
- 去掉了 Pushgateway 这个单点组件。
监控数据的来源与展示
TiDB 的 3 个核心组件(TiDB server、TiKV server 和 PD server)可以通过 HTTP 接口来获取 metric 数据。这些 metric 均是从程序代码中上传的,默认端口如下:
| 组件 | 端口 |
|---|---|
| TiDB server | 10080 |
| TiKV server | 20181 |
| PD server | 2379 |
下面以 TiDB server 为例,展示如何通过 HTTP 接口查看一个语句的 QPS 数据:
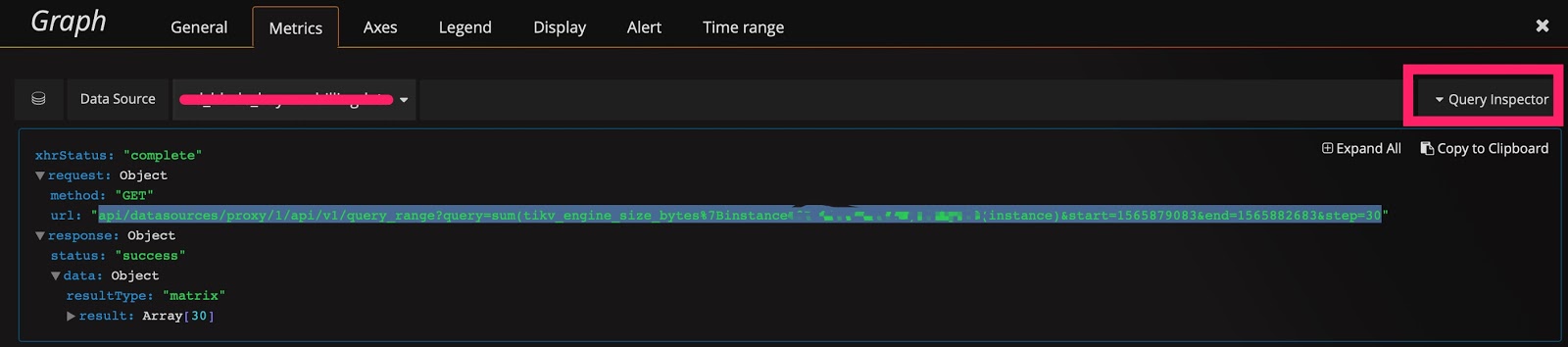
这些数据会存储在 Prometheus 中,然后在 Grafana 上进行展示。在面板上点击鼠标右键会出现 Edit 按钮(或直接按 E 键),如下图所示:
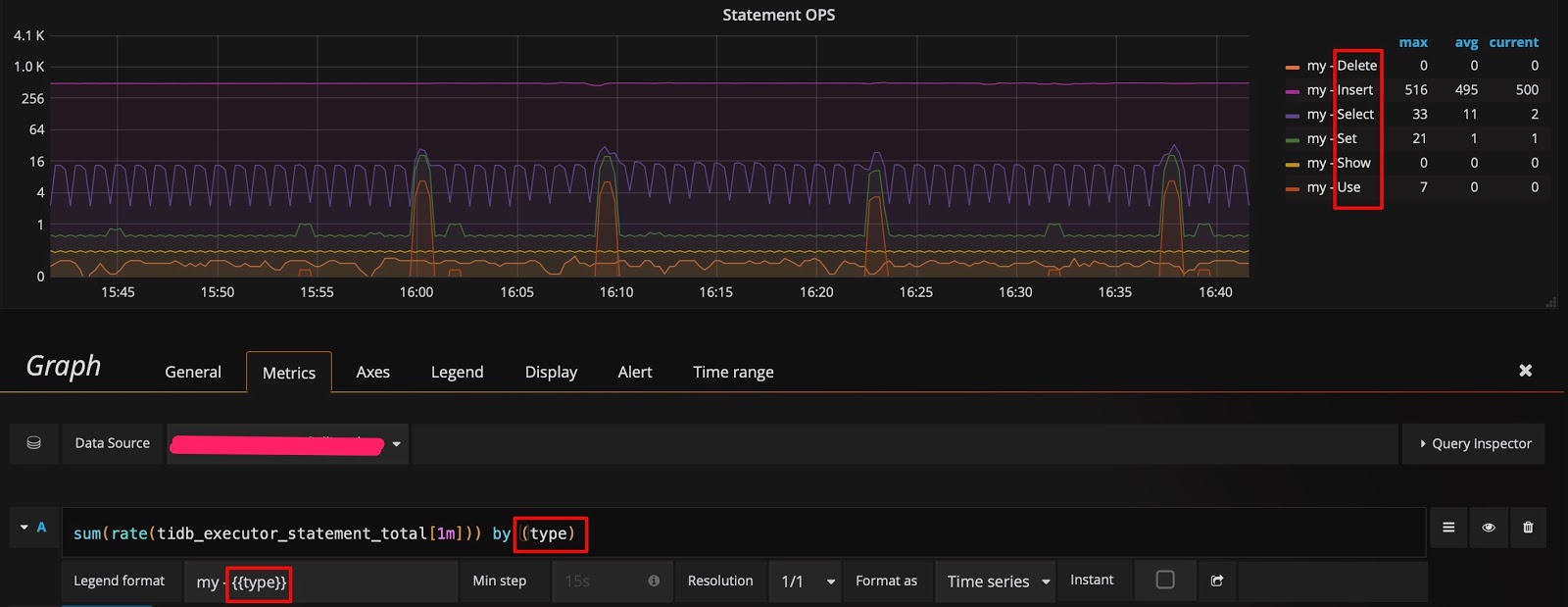
点击 Edit 按钮之后,在 Metrics 面板上可以看到利用该 metric 的 query 表达式。面板上一些细节的含义如下:
rate[1m]:表示 1 分钟的增长速率,只能用于 counter 类型的数据。sum:表示 value 求和。by type:表示将求和后的数据按 metric 原始值中的 type 进行分组。Legend format:表示指标名称的格式。Resolution:默认打点步长是 15s,Resolution 表示是否将多个样本数据合并成一个点。
Metrics 面板中的表达式如下:
Prometheus 支持很多表达式与函数,更多表达式请参考 Prometheus 官网页面。
Grafana 使用技巧
本小节介绍高效利用 Grafana 监控分析 TiDB 指标的七个技巧。
技巧 1:查看所有维度并编辑表达式
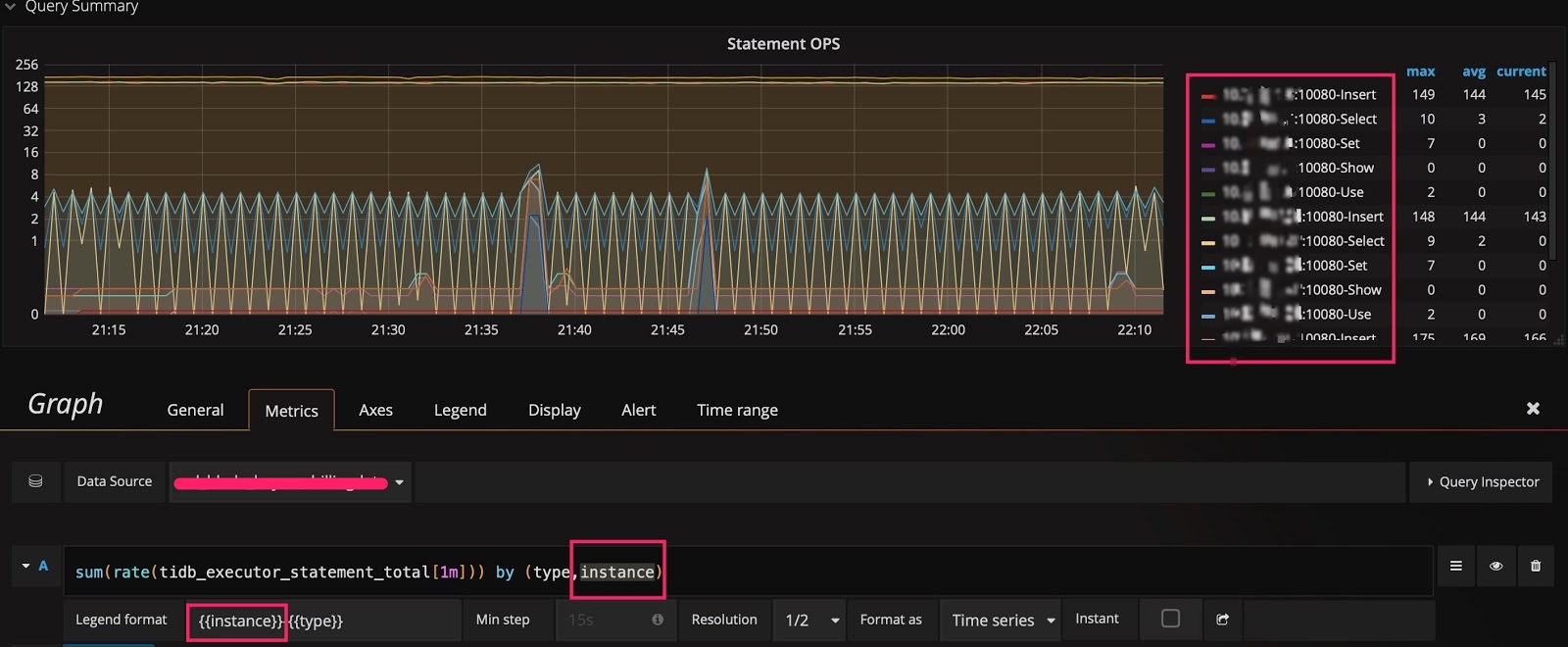
在监控数据的来源与展示一节的示例中,数据是按照 type 进行分组的。如果你想知道是否还能按其它维度分组,并快速查看还有哪些维度,可采用以下技巧:在 query 的表达式上只保留指标名称,不做任何计算,Legend format 也留空。这样就能显示出原始的 metric 数据。比如,下图能看到有 3 个维度(instance、job 和 type):
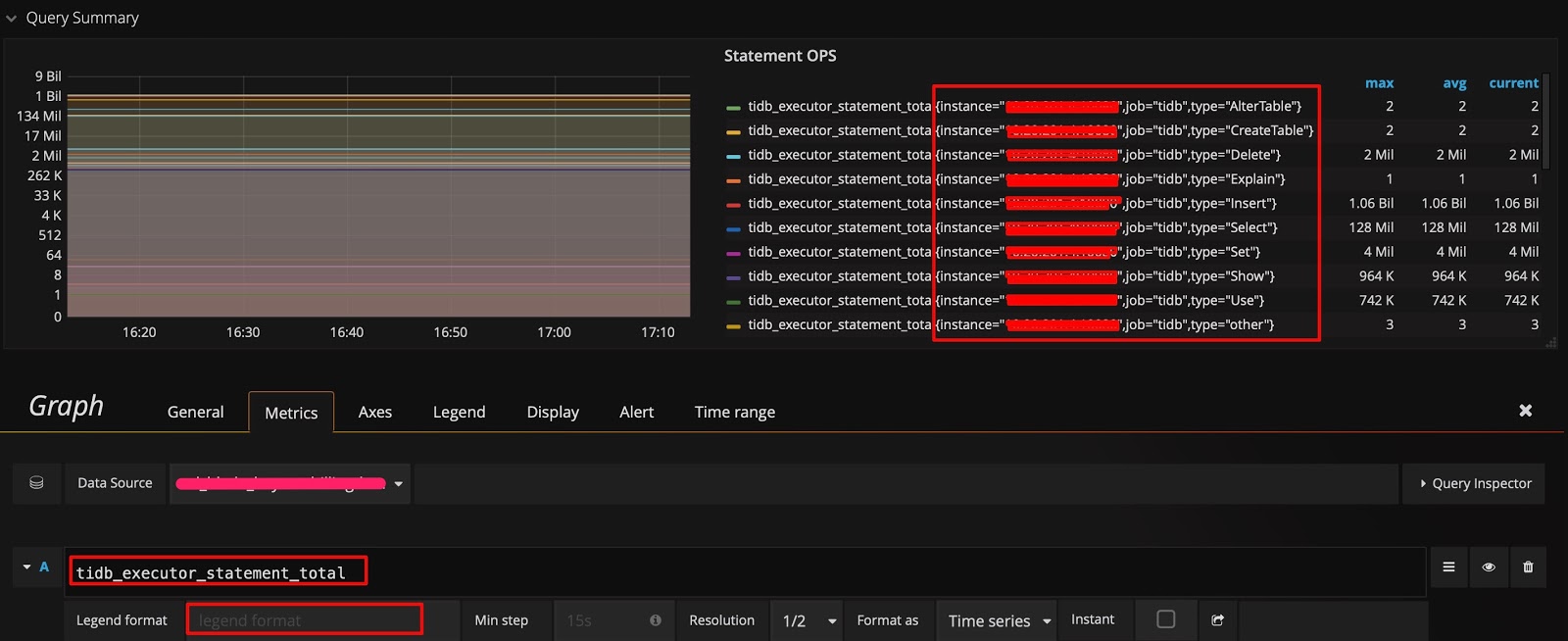
然后调整表达式,在原有的 type 后面加上 instance 这个维度,在 Legend format 处增加 {{instance}},就可以看到每个 TiDB server 上执行的不同类型 SQL 语句的 QPS 了。如下图所示:
技巧 2:调整 Y 轴标尺的计算方式
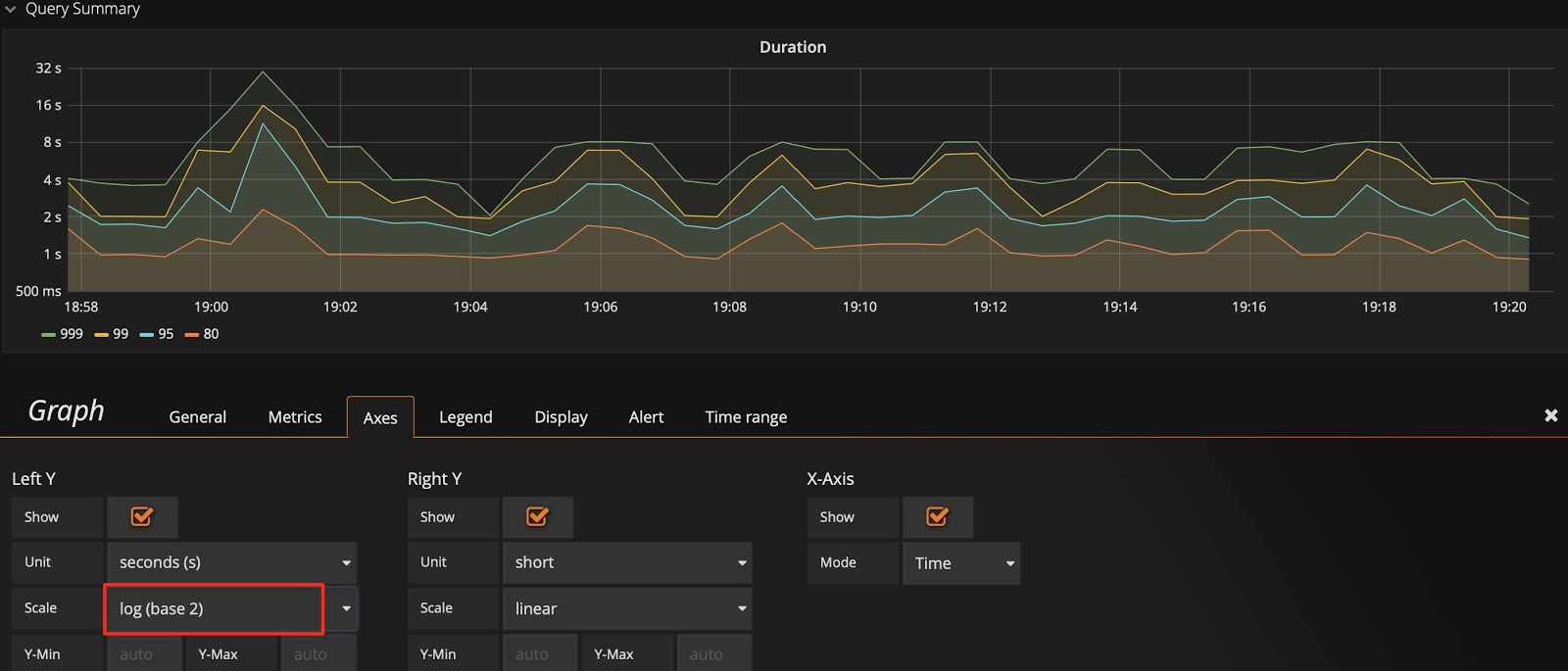
以 Query Duration 指标为例,默认的比例尺采用 2 的对数计算,显示上会将差距缩小。为了观察到明显的变化,可以将比例尺改为线性,从下面两张图中可以看到显示上的区别,明显发现那个时刻有个 SQL 语句运行较慢。
当然也不是所有场景都适合用线性,比如观察 1 个月的性能趋势,用线性可能就会有很多噪点,不好观察。
标尺默认的比例尺为 2 的对数:
将标尺的比例尺调整为线性:
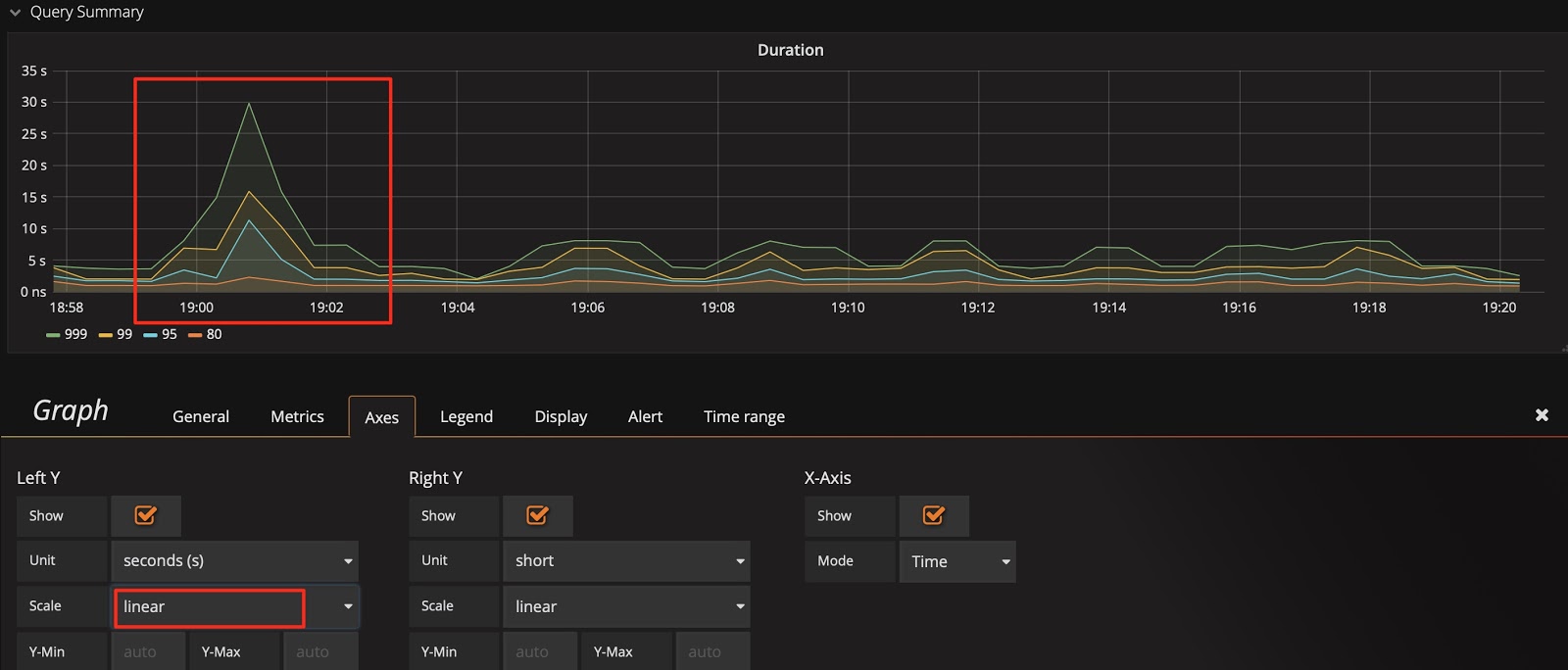
结合技巧 1,会发现这里还有一个 sql_type 的维度,可以立刻分析出是 SELECT 慢还是 UPDATE 慢;并且可以分析出是哪个 instance 上的语句慢。
技巧 3:调整 Y 轴基线,放大变化
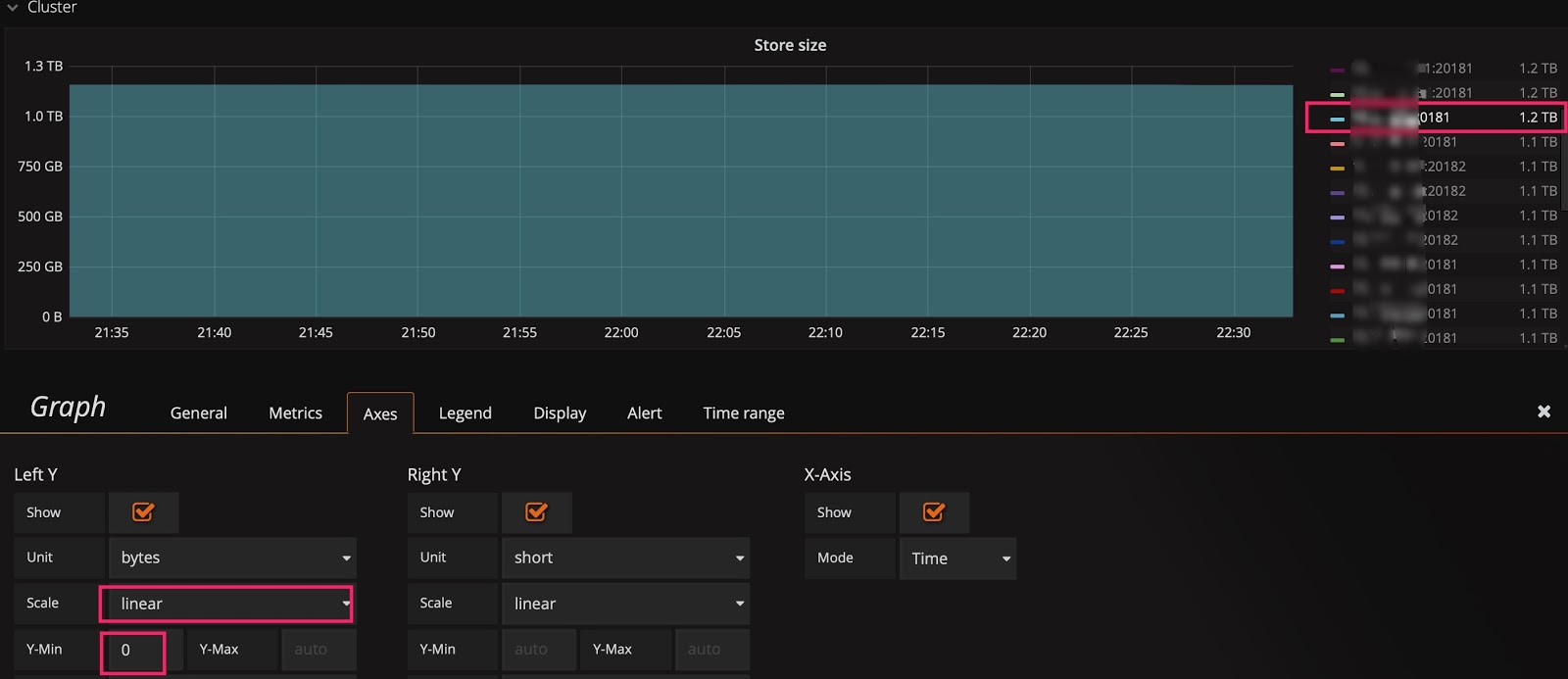
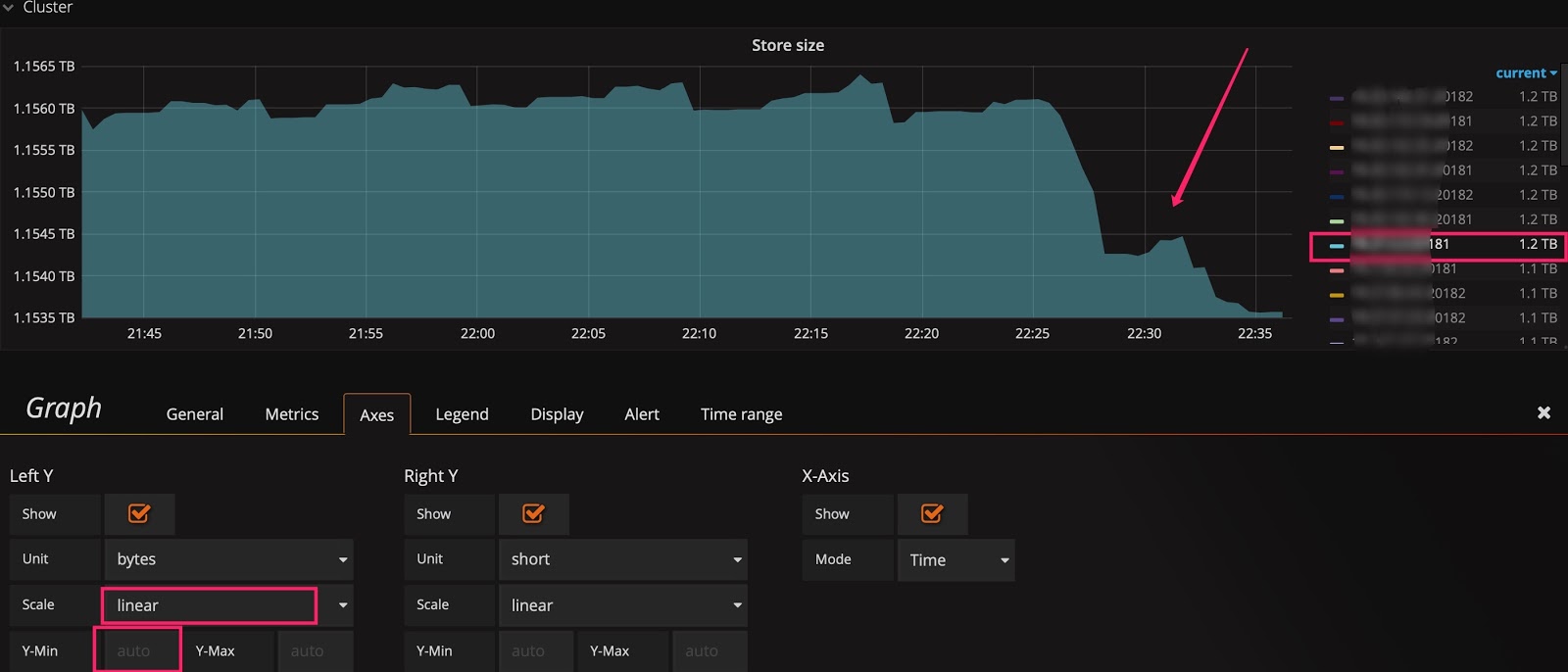
有时已经用了线性比例尺,却还是看不出变化趋势。比如下图中,在扩容后想观察 Store size 的实时变化效果,但由于基数较大,观察不到微弱的变化。这时可以将 Y 轴最小值从 0 改为 auto,将上部放大。观察下面两张图的区别,可以看出数据已开始迁移了。
基线默认为 0:
将基线调整为 auto:
技巧 4:标尺联动
在 Settings 面板中,有一个 Graph Tooltip 设置项,默认使用 Default。
下面将图形展示工具分别调整为 Shared crosshair 和 Shared Tooltip 看看效果。可以看到标尺能联动展示了,方便排查问题时确认 2 个指标的关联性。
将图形展示工具调整为 Shared crosshair:

将图形展示工具调整为 Shared Tooltip:

技巧 5:手动输入 ip:端口号 查看历史信息
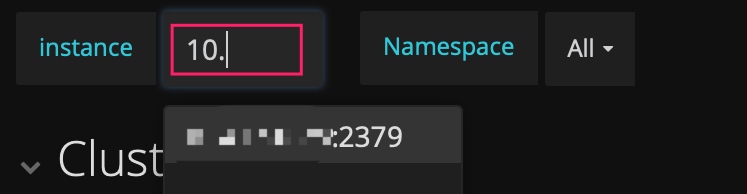
PD 的 dashboard 只展示当前 leader 的 metric 信息,而有时想看历史上 PD leader 当时的状况,但是 instance 下拉列表中已不存在这个成员了。此时,可以手动输入 ip:2379 来查看当时的数据。
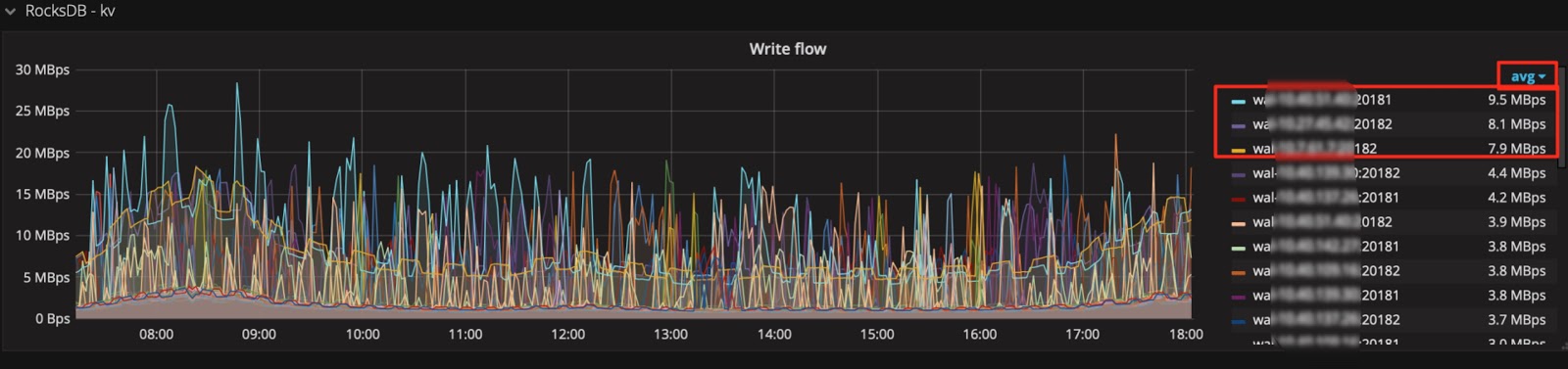
技巧 6:巧用 Avg 函数
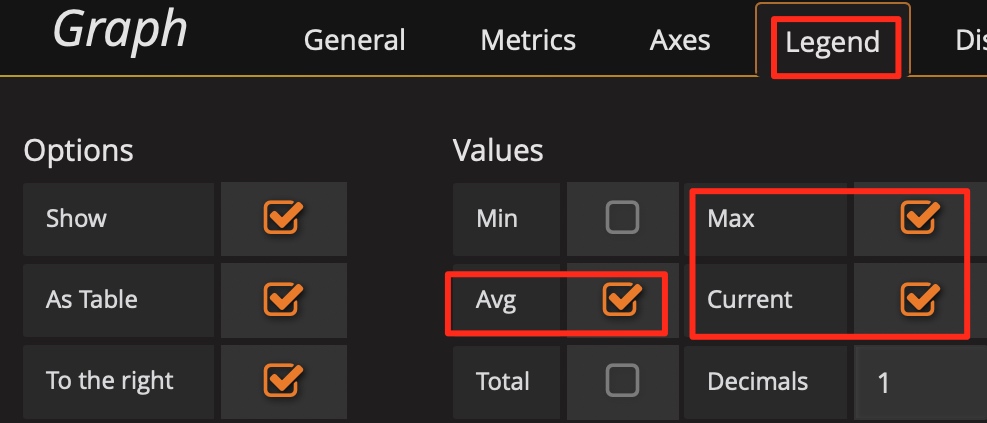
通常默认图例中只有 Max 和 Current 函数。当指标波动较大时,可以增加 Avg 等其它汇总函数的图例,来看一段时间的整体趋势。
增加 Avg 等汇总函数:
然后查看整体趋势:
技巧 7:使用 Prometheus 的 API 接口获得表达式的结果
Grafana 通过 Prometheus 的接口获取数据,你也可以用该接口来获取数据,这个用法还可以衍生出许多功能:
- 自动获取集群规模、状态等信息。
- 对表达式稍加改动给报表提供数据,如统计每天的 QPS 总量、每天的 QPS 峰值和每天的响应时间。
- 将重要的指标进行定期健康巡检。
Prometheus 的 API 接口如下:
总结
Grafana + Prometheus 监控平台是一套非常强大的组合工具,用好这套工具可以为分析节省很多时间,提高效率,更重要的是,我们可以更容易发现问题。在运维 TiDB 集群,尤其是数据量大的情况下,这套工具能派上大用场。
[转帖]使用 Grafana 监控 TiDB 的最佳实践的更多相关文章
- Kubernetes集群的监控报警策略最佳实践
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/M2l0ZgSsVc7r69eFdTj/article/details/79652064 本文为Kub ...
- [转帖]Prometheus+Grafana监控Kubernetes
原博客的位置: https://blog.csdn.net/shenhonglei1234/article/details/80503353 感谢原作者 这里记录一下自己试验过程中遇到的问题: . 自 ...
- 京东前端:PhantomJS 和NodeJS在网站前端监控平台的最佳实践
1. 为什么需要一个前端监控系统 通常在一个大型的 Web 项目中有很多监控系统,比如后端的服务 API 监控,接口存活.调用.延迟等监控,这些一般都用来监控后台接口数据层面的信息.而且对于大型网站系 ...
- Docker监控:最佳实践以及cAdvisor和Prometheus监控工具的对比
在DockerCon EU 2015上,Brian Christner阐述了“Docker监控”的概况,分享了这方面的最佳实践和Docker stats API的指南,并对比了三个流行的监控方案:cA ...
- [转帖]安装prometheus+grafana监控mysql redis kubernetes等
安装prometheus+grafana监控mysql redis kubernetes等 https://www.cnblogs.com/sfnz/p/6566951.html plug 的模式进行 ...
- Docker部署Zabbix+Grafana监控
Docker部署Zabbix+Grafana监控 环境 centos 7 ; Docker 17.12.0-ce ; docker-compose version 1.20.1 2018-4-1 当前 ...
- cAdvisor+Prometheus+Grafana监控docker
cAdvisor+Prometheus+Grafana监控docker 一.cAdvisor(需要监控的主机都要安装) 官方地址:https://github.com/google/cadvisor ...
- 使用Telegraf + Influxdb + Grafana 监控SQLserver服务器的运行状况
使用Telegraf + Influxdb + Grafana 监控SQLserver服务器的运行状况 前言 本文在Debian9下采用Docker的方式安装Telegraf + Influxdb + ...
- 快速接入业务监控体系,grafana监控的艺术
做一个系统,如果不做监控,是不完善的. 如果为做一个快速系统,花力气去做监控,是不值得的. 因为,我们有必要具备一个能够快速建立监控体系的能力.即使你只是一个普通开发人员! 个人觉得,做监控有三个核心 ...
- prometheus+grafana监控redis
prometheus+grafana监控redis redis安装配置 https://www.cnblogs.com/autohome7390/p/6433956.html redis_export ...
随机推荐
- wasm+pygbag让你在网页上也能运行Python代码:【贪吃蛇游戏】
引言 最近小伙伴告诉我一种新的方法,可以使用wasm来使浏览器网页能够运行Python代码.这一下子激起了我的兴趣,因为这意味着用户无需安装Python环境就能直接运行我的demo,这真是太方便了.所 ...
- zabbix 利用脚本发邮件(mail)
# 源码安装mailx tar jxvf mailx-12.3.tar.bz2 make && make install UCBINSTALL=/usr/bin/install #yu ...
- MyBatis 批量更新的处理
一般来讲,在使用 MyBatis 进行数据库的访问时,通常会遇到需要更新数据的相关业务,在某些业务场景下,如果需要进行一批次的数据更新,可能性能不是特别理想.本文将简要介绍几种能够高效地处理批量更新数 ...
- android 页面切换
案例演示: 首先有MainActivity与LoginActivity两个Activity MainActivity.java public class MainActivity extends Ap ...
- 2024年,在风云际会的编程世界里,窥探Java的前世今生,都说它穷途末路,我认为是柳暗花明!
2024年,在风云际会的编程世界里,窥探Java的前世今生,都说它穷途末路,我认为是柳暗花明! 文编|JavaBuild 哈喽,大家好呀!我是JavaBuild,以后可以喊我鸟哥,嘿嘿!俺滴座右铭是不 ...
- k8s主要概念大梳理!
k8s已经成为了绝对热门的技术,一个上点规模的公司,如果不搞k8s,都不好意思出去见人.安装k8s要突破种种网络阻碍,但更大的阻碍还在后面... 我发现,很多k8s的文章,根本不说人话,包括那要命的官 ...
- nacos-config配置中心
依赖 <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-clou ...
- .NET技术分享日活动-202107
2021年7月3日下午,个人组织举办了山东地区的第二次山东.NET技术分享日活动.围绕互联网技术.大数据.机器学习.业务实践等方向进行创新技术的实践分享. 本次技术分享日活动面向了山东地区广大的.NE ...
- 高性能利器!华为云MRS ClickHouse重磅推出!
摘要:华为智能数据湖MRS服务即将上线ClickHouse高性能引擎集群,用户只需要几分钟,就可以轻松方便地一键式完成集群部署搭建,快速拥有PB级数据的秒级交互查询分析能力,帮助用户带来极致的性能体验 ...
- 解放重复劳动丨华为云IoT API Explorer对接小程序实现系统化应用
摘要:<物联网平台接口调用实验>详细讲解了API Explorer的应用,根据提供的接口,结合真实案例,制作了一个小程序,真正的把它应用起来,解放重复劳动,小程序是一个很好的平台,作为应用 ...