TensorFlow 深度学习笔记 从线性分类器到深度神经网络
转载请注明作者:梦里风林
Github工程地址:https://github.com/ahangchen/GDLnotes
欢迎star,有问题可以到Issue区讨论
官方教程地址
视频/字幕下载
Limit of Linear Model
- 实际要调整的参数很多
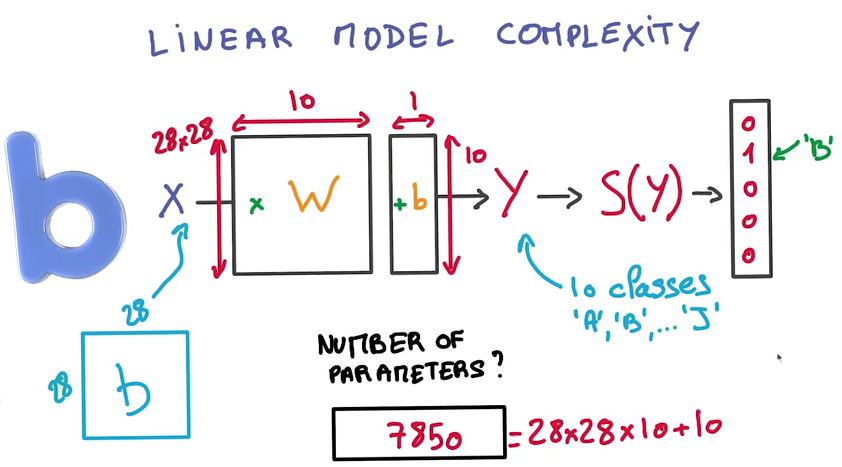
如果有N个Class,K个Label,需要调整的参数就有(N+1)K个
Linear Model不能应对非线性的问题

- Linear Model的好处
- GPU就是设计用于大矩阵相乘的,因此它们用来计算Linear Model非常efficient
Stable:input的微小改变不会很大地影响output
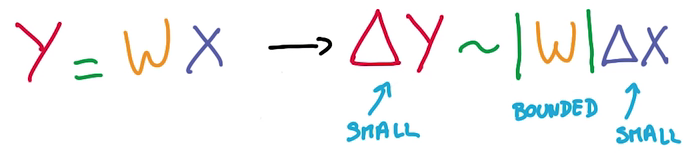
- 求导方便:线性求导是常数
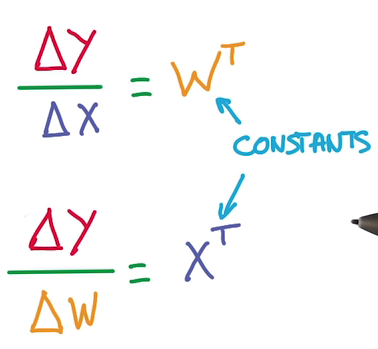
- 我们希望参数函数是线性的,但整个model是非线性的
- 所以需要对各个线性模型做非线性组合
- 最简单的非线性组合:分段线性函数(RELU)

Neural network
- 用一个RELU作为中介,一个Linear Model的输出作为其输入,其输出作为另一个Linear Model的输入,使其能够解决非线性问题

- 神经网络并不一定要完全像神经元那样工作
- Chain Rule:复合函数求导规律

- Lots of data reuse and easy to implement(a simple data pipeline)
- Back propagation
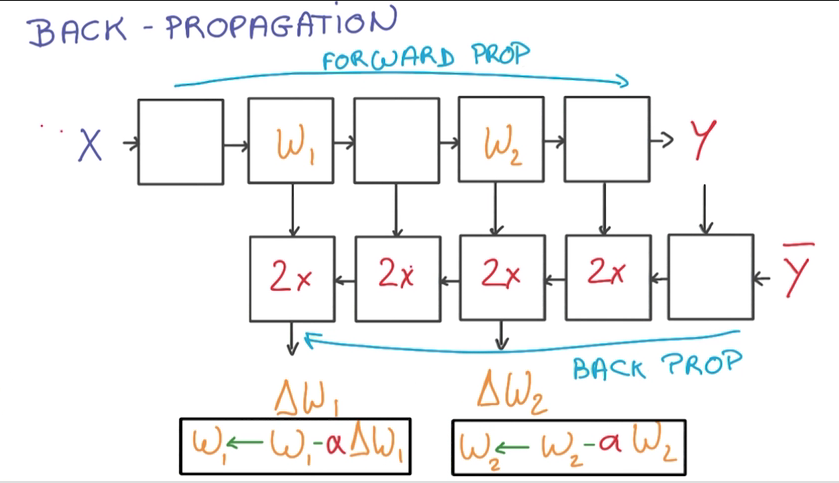
- 计算train_loss时,数据正向流入,计算梯度时,逆向计算
- 计算梯度需要的内存和计算时间是计算train_loss的两倍
Deep Neural Network
Current two layer neural network:
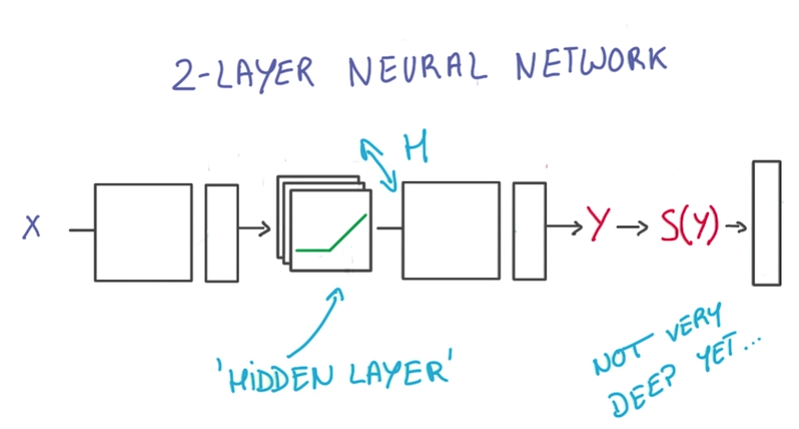
优化:
- 优化RELU(隐藏层), wider
增加linear层,layer deeper
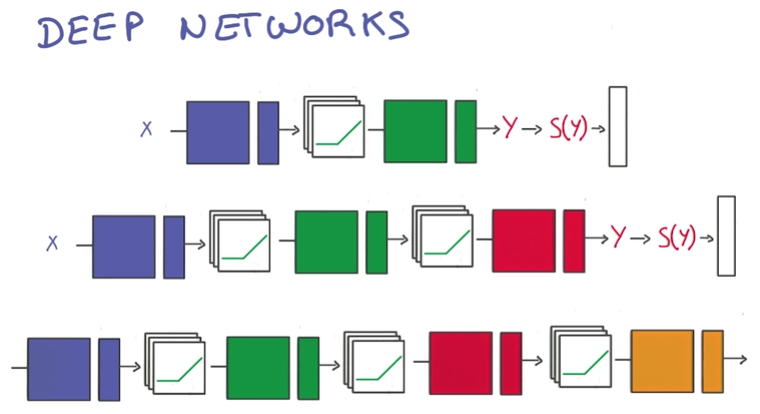
- Performance: few parameters by deeper
随层级变高,获得的信息越综合,越符合目标
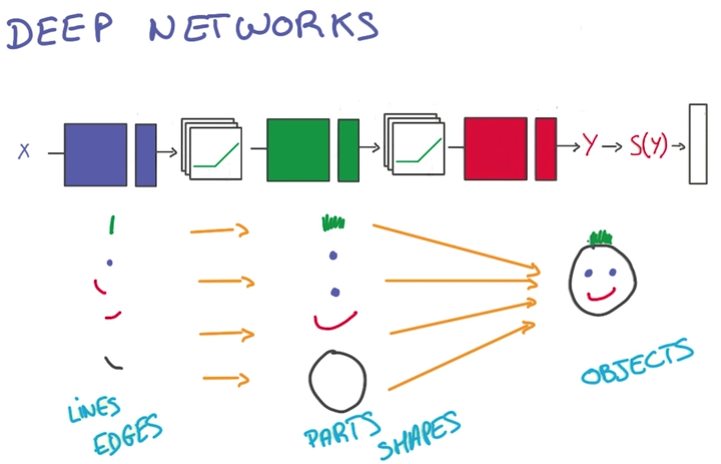
About t-model
- t-model只有在有大量数据时有效
- 今天我们才有高效的大数据训练方法:Better Regularization
- 难以决定适应问题的神经网络的规模,因此通常选择更大的规模,并防止过拟合
Avoid Overfit
Early Termination
- 当训练结果与验证集符合度下降时,就停止训练

Regulation
- 给神经网络里加一些常量,做一些限制,减少自由的参数
- L2 regularization
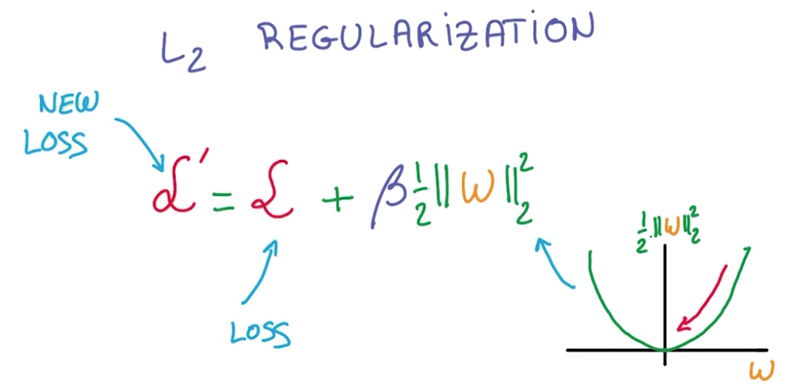
在计算train loss时,增加一个l2 norm作为新的损失,这里需要乘一个β(Hyper parameter),调整这个新的项的值
Hyper parameter:拍脑袋参数→_→
l2模的导数容易计算,即W本身
DropOut
最近才出现,效果极其好
- 从一个layer到另一个layer的value被称为activation
- 将一个layer到另一个layer的value的中,随机地取一半的数据变为0,这其实是将一半的数据直接丢掉
- 由于数据缺失,所以就强迫了神经网络学习redundant的知识,以作为损失部分的补充
- 由于神经网络中总有其他部分作为损失部分的补充,所以最后的结果还是OK的
- More robust and prevent overfit
如果这种方法不能生效,那可能就要使用更大的神经网络了
- 评估神经网络时,就不需要DropOut,因为需要确切的结果
- 可以将所有Activation做平均,作为评估的依据
因为我们在训练时去掉了一半的随机数据,如果要让得到Activation正确量级的平均值,就需要将没去掉的数据翻倍

觉得得我的文章对您有帮助的话,就给个star吧~
TensorFlow 深度学习笔记 从线性分类器到深度神经网络的更多相关文章
- TensorFlow深度学习笔记 文本与序列的深度模型
Deep Models for Text and Sequence 转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎st ...
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- Google TensorFlow深度学习笔记
Google Deep Learning Notes Google 深度学习笔记 由于谷歌机器学习教程更新太慢,所以一边学习Deep Learning教程,经常总结是个好习惯,笔记目录奉上. Gith ...
- UFLDL深度学习笔记 (五)自编码线性解码器
UFLDL深度学习笔记 (五)自编码线性解码器 1. 基本问题 在第一篇 UFLDL深度学习笔记 (一)基本知识与稀疏自编码中讨论了激活函数为\(sigmoid\)函数的系数自编码网络,本文要讨论&q ...
- UFLDL深度学习笔记 (七)拓扑稀疏编码与矩阵化
UFLDL深度学习笔记 (七)拓扑稀疏编码与矩阵化 主要思路 前面几篇所讲的都是围绕神经网络展开的,一个标志就是激活函数非线性:在前人的研究中,也存在线性激活函数的稀疏编码,该方法试图直接学习数据的特 ...
- UFLDL深度学习笔记 (六)卷积神经网络
UFLDL深度学习笔记 (六)卷积神经网络 1. 主要思路 "UFLDL 卷积神经网络"主要讲解了对大尺寸图像应用前面所讨论神经网络学习的方法,其中的变化有两条,第一,对大尺寸图像 ...
- UFLDL深度学习笔记 (三)无监督特征学习
UFLDL深度学习笔记 (三)无监督特征学习 1. 主题思路 "UFLDL 无监督特征学习"本节全称为自我学习与无监督特征学习,和前一节softmax回归很类似,所以本篇笔记会比较 ...
- Deep Learning.ai学习笔记_第一门课_神经网络和深度学习
目录 前言 第一周(深度学习引言) 第二周(神经网络的编程基础) 第三周(浅层神经网络) 第四周(深层神经网络) 前言 目标: 掌握神经网络的基本概念, 学习如何建立神经网络(包含一个深度神经网络), ...
- UFLDL深度学习笔记 (二)SoftMax 回归(矩阵化推导)
UFLDL深度学习笔记 (二)Softmax 回归 本文为学习"UFLDL Softmax回归"的笔记与代码实现,文中略过了对代价函数求偏导的过程,本篇笔记主要补充求偏导步骤的详细 ...
随机推荐
- css制作最简单导航栏
css制作最简单导航栏
- ccf练习---节日
问题描述 有一类节日的日期并不是固定的,而是以“a月的第b个星期c”的形式定下来的,比如说母亲节就定为每年的五月的第二个星期日. 现在,给你a,b,c和y1, y2(1850 ≤ y1, y2 ≤ 2 ...
- SQL查询 addScalar()或addEntity()
Hibernate除了支持HQL查询外,还支持原生SQL查询. 对原生SQL查询执行的控制是通过SQLQuery接口进行的,通过执行Session.createSQLQuery()获取这个接口.该 ...
- LeetCode_Longest Consecutive Sequence
Given an unsorted array of integers, find the length of the longest consecutive elements sequence. F ...
- UESTC_Eight Puzzle 2015 UESTC Training for Search Algorithm & String<Problem F>
F - Eight Puzzle Time Limit: 3000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Others) ...
- 【转】RTSP流理解
rtsp是使用udp还是tcp,是跟服务器有关,服务器那边说使用udp,那就使用udp,服务器说使用tcp那就使用tcp rtsp客户端的创建: 1.建立TCP socket,绑定服务器ip,用来传送 ...
- 【SSH三大框架】Hibernate基础第一篇:编写第一个Hibernate程序
接下来这几章节学习的是Hibernate,Hibernate的主要作用就是用来和数据库进行连接,简化了JDBC的操作. 首先,我们创建项目,然后把Hibernate的jar包和sqlserver的驱动 ...
- Java中基础类库使用
Java中基础类库: 在这里我仅仅介绍几种我个人觉得会常常使用的 1:Object类中的Clone机制仅仅是对对象进行浅层次的克隆,假设须要进行深层次的克隆的话那么就要自己写(详细Clone方法请參考 ...
- 9年经验,总结SEO职业瓶颈
昨天与某集团的副总与部门总监沟通了一些关于SEO发展与瓶颈的问题,有很多感触,今天整理出来分享给大家.其实关于SEO瓶颈这个话题已经不是一年两年了,很多新人老人越来越困惑,9年历程一路风雨走来,希望能 ...
- C程序设计语言(K&R)笔记
1.表达式中float类型的操作数不会自动转换为double类型.一般来说,数学函数(如math.h)使用双精度类型的变量.使用float类型主要是为了在使用较大数组时节省存储空间,有时也为了节省机器 ...