量子纠错码——Clifford group
Clifford code
Clifford group是什么?
简单的公式来表达,就是 \(Cl_{n}=\left\{U: U P_{n} U^{\dagger} \in P_{n}\right\}\) 。
用语言来描述,就是对一个泡利施加一个U操作,然后还是一个泡利。
首先,所有的泡利都属于\(Cl_n\),因为泡利矩阵自己相乘还是泡利。
但也有非泡利的矩阵在这里面,比如H也属于clifford,\(HXH=Z\),$ HZH=X$
另一个例子是 \(S=\sqrt{Z}=\left(\begin{array}{cc}1 & 0 \\ 0 & i\end{array}\right)\)
\(SZS^{\dagger}=ZSS^{\dagger}=Z\)
\(SXS^{\dagger}=iY\)
但是也并非所有的操作都属于\(Cl_n\),比如T门,\(TZT^{\dagger}=ZTT^{\dagger}=ZS \notin P\)
对于单量子比特来说:\(Cl_1=\langle X,Z,H,S\rangle\)
但是我们不仅只有单比特,对于多比特,他不是简单的\(Cl_1^{\otimes n}\) ,因为多比特有纠缠。
比如\(SWAP_{ij}\) ,将第i个和第j个交换一下,这很明显操作完了还是一个泡利,属于\(Cl_n\),\(\operatorname{SWAP}_{i j} X_{i} \operatorname{SWAP}_{i j}^{\dagger}=X_{j}\)
除此之外还有CNOT,CNOT对于原来的泡利在受控比特和控制比特上有所不一样,对X和Z的影响也不一样,其效果如下表:

事实上,我们可以用3个CNOT来构建一个SWAP
所以 \(C l_{n}=\langle H_{i},S_{j},CNOT_{i j}\rangle\)
Clifford group可以做什么?
ok,我们已经知道Clifford的定义了,但是我们为什么要定义一个Clifford group呢?他有什么用?
5 qubit code
定义一组对应五比特编码的stabilizer,\(S=\langle Z X X Z I, I Z X X Z, Z I Z X X, X Z I Z X\rangle\),我们可以很容易的给她加上最后一位变成\(S=\langle Z X X Z I, I Z X X Z, Z I Z X X, X Z I Z X, X X Z I Z\rangle\),多出来的这个就是前面4个的乘积,所以不会影响到最后的结果。
接下来,我们定义 normalizers of S ,也就是\(N(S)\)。
对于\(N(S)\),我们只有一个要求,那就是\(N(S)=\left\{p \in P_{n} | p S p^{\dagger}=S\right\}\)。
对于\(p S p^{\dagger}=S\),我们可以换一种理解方式,即\(pg=gp \forall g \in S\)。
trivial code
我们都知道,编码其实就是将低维的空间映射到高维,那么最为朴实的一种映射就是补零操作,\(V_{S} \in\left\{|0\rangle^{\otimes n-k} \otimes|\Psi\rangle:|\Psi\rangle \in \mathbb{C}^{2^{k}}\right\}\),这就是一个简单的把k比特映射到n比特空间的一种trival code。
这种编码的stabilizer很简单,\(S=\left\langle Z_{1}, Z_{2} \dots . Z_{n-k}\right\rangle\),\(Z_i\)的意思是除了第i个比特是Z其他都是I,这个很好理解,因为前面n-k个比特我们都是\(|0\rangle\),是Z的特征向量。
那这两个编码之间有什么关系吗?
我们可以给出以下声明:
对于任意的stabilizer code,都可以通过unitary的转化和trivial code等价。
而这个unitary就属于我们的Clifford group。
假设我有一组stabilizer \(S\),以及这个\(S\)对应的子空间\(V_S\),那么一定存在一个unitary U 使得 \(USU^{\dagger}=\left\langle Z_{1}, Z_{2} \dots . Z_{n-k}\right\rangle\)
这个时候,我们的子空间\(V_{S}\)就变成了\(V_{USU^{\dagger}}\)
后一句话很好理解,原来这个子空间里的向量为\(|\psi\rangle\),现在这个子空间里的每一个向量就变成了\(U|\psi\rangle\)
\((USU^{\dagger})U|\psi\rangle=US|\psi\rangle=U|\psi\rangle\)
那么前一个为什么会存在这个U呢?
先来论证一下他的可能性,U会改变一些东西,但是有一些不会改变,比如,他不会改变这个的特征值,而正好,他们都是泡利矩阵,特征值都是正负1;又比如,U不会改变他们的对易和反对易,他们正好都是对易的操作。
事实上,对于泡利矩阵来说,只要他们的对易反对易的模式相同,那么我就可以用U对他们进行一个映射。
我们可以换一个视角从向量的角度来看一看这个问题
令\(a,b \in \mathbb{F}^n\),那么\(v=\left(\begin{array}{l}a \\ b\end{array}\right) \in F^{2 n}\)
任意一个Pauli都可以用v来表示\(X^{a} Z^{b}=\sigma^{\left(\begin{array}{c}a \\ b\end{array}\right)}\)
那么Clifford group在做什么?
$U\sigmavU{\dagger} \in P_n $
即,其实就是把\(\sigma^{v_1}\)映射成$\sigma^{v_2} $
\(U\sigma^{v}U^{\dagger}=(-1)^{f(v)}\sigma^{g(v)}\)
我们的下一步就是看这里的函数f(v)和g(v)需要满足哪些条件
这里面一个限制就是U变换不会改变操作本来的对易和反对易。
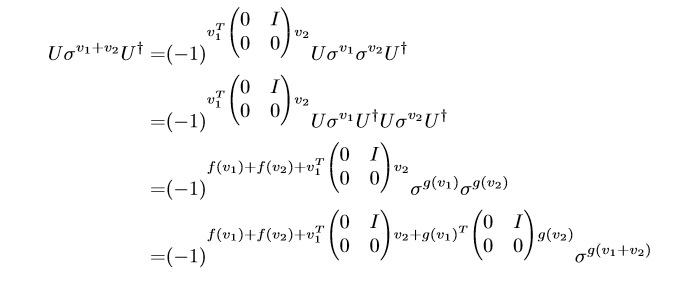
第二个等式是加上了\(U^{\dagger}U\),因为这两个乘积为\(I\)不会有影响
第三个等式是带入公式\(U\sigma^{v}U^{\dagger}=(-1)^{f(v)}\sigma^{g(v)}\)
如果这里面的\(\sigma^v\)就是我们的\(\sigma^{v_1+v_2}\),那么后面我们的到的就是\((-1)^{f(v_1+v_2)}\sigma^{g(v_1+v_2)}\)
即\(g(v_1+v_2)=g(v_1)+g(v_2)\),函数g是一个线性函数
g(v)=Mv
但是也不是所有的M是可行的。
\(\sigma^{v} \sigma^{w} \sigma^{v} \sigma^{w}=(-1)^{v^{T}\Lambda w} I\) 其中\(\lambda=\left(\begin{array}{ll}0 & I \\ 0 & 0\end{array}\right)\)
我们可以先把他展开:
\(U \sigma^{N} U^{\dagger}U \sigma^{W} U^{\dagger}U \sigma^{N} U^{\dagger}U\sigma^{W}U=\sigma^{Mv}\sigma^{Mw}\sigma^{Mv}\sigma^{Mw}\)
这里没有系数,因为两个一模一样的系数乘起来就是1,所以系数可以省略掉。
而如果把\(\sigma^{Mw}\sigma^{Mv}\)交换一下可以变成:
\((-1)^{(Mv)^T\Lambda Mw}I\)
我们可以得出:
\(v^T \Lambda w= v^TM^T \Lambda M w\)
即\(\Lambda=M^T \Lambda M\)
而这个就是M需要满足的条件,属于symplectic group。
量子纠错码——Clifford group的更多相关文章
- 量子纠错码——Stabilizer codes
对于错误,一般有两种: random: 错误以一定的概率发生在每个比特上(对这种问题的研究一般是信息论中,信道熵一类的问题) worst case: 错误发生在某个比特上,这也是纠错码襄阳解决的问题 ...
- LINQ Group By操作
在上篇文章 .NET应用程序与数据库交互的若干问题 这篇文章中,讨论了一个计算热门商圈的问题,现在在这里扩展一下,假设我们需要从两张表中统计出热门商圈,这两张表内容如下: 上表是所有政区,商圈中的餐饮 ...
- Kafka消费组(consumer group)
一直以来都想写一点关于kafka consumer的东西,特别是关于新版consumer的中文资料很少.最近Kafka社区邮件组已经在讨论是否应该正式使用新版本consumer替换老版本,笔者也觉得时 ...
- LINQ to SQL语句(6)之Group By/Having
适用场景:分组数据,为我们查找数据缩小范围. 说明:分配并返回对传入参数进行分组操作后的可枚举对象.分组:延迟 1.简单形式: var q = from p in db.Products group ...
- 学习笔记 MYSQL报错注入(count()、rand()、group by)
首先看下常见的攻击载荷,如下: select count(*),(floor(rand(0)*2))x from table group by x; 然后对于攻击载荷进行解释, floor(rand( ...
- [备查]使用 SPQuery 查询 "Person or Group" 字段
原文地址:http://www.stum.de/2008/02/06/querying-the-person-or-group-field-using-spquery/ Querying the “P ...
- order by 与 group by 区别
order by 排序查询.asc升序.desc降序 示例: select * from 学生表 order by 年龄 ---查询学生表信息.按年龄的升序(默认.可缺省.从低到高)排列显示 也可以多 ...
- Group by
分组语句必须和聚合函数在一起使用, group by子句负责将数据分成逻辑组,聚合函数对每一组进行统计计算 group by 必须放到 select 语句后面,如果select语句中有where子句, ...
- Oracle学习笔记五 SQL命令(三):Group by、排序、连接查询、子查询、分页
GROUP BY和HAVING子句 GROUP BY子句 用于将信息划分为更小的组每一组行返回针对该组的单个结果 --统计每个部门的人数: Select count(*) from emp group ...
随机推荐
- Shiro踩坑记(一):关于shiro-spring-boot-web-starter自动注解无法注入authorizer的问题
一)问题描述: 我在一个Spring的项目中使用shiro搭建权限控制框架.主要通过shiro-spring-boot-web-starter包快速集成Shiro.但是项目无法启动,报没有author ...
- pfSense®2.4.4发布后,原pfSense 黄金会员的服务将免费使用!
2018年7月16日,Doug McIntire 从即将发布的pfSense®2.4.4开始,之前在"pfSense Gold"下提供的所有服务都将继续,但所有pfSense用户都 ...
- 2018年要学习的10大Python Web框架
通过为开发人员提供应用程序开发结构,框架使开发人员的生活更轻松.他们自动执行通用解决方案,缩短开发时间,并允许开发人员更多地关注应用程序逻辑而不是常规元素. 在本文中,我们分享了我们自己的前十大Pyt ...
- vSphere可用性之三准备实验环境
第三章 准备实验环境 在上篇内容中,讲述了进行VMware HA实验所必需的软硬件条件.接下来将使用这些来搭建实验环境.主要内容为依据拓扑图安装ESX主机系统.ISCSI存储系统. 此次实验环境的建置 ...
- PHP版DES算法加密数据(3DES)另附openssl_encrypt版本
PHP版DES算法加密数据(3DES) 可与java的DES(DESede/CBC/PKCS5Padding)加密方式兼容 <?php /** * Created by PhpStorm. * ...
- 学习笔记之pip的基本使用
粗略学习了pip的基础知识,便将此作为学习笔记记录下来同样希望分享的能帮到大家! 如果自己电脑没有pip,小澈在此分享如何安装,解决办法很多呢 1.使用easy_install安装: 各种进入到eas ...
- 安卓commandlinetools-win-6200805_latest配置
JDK:1.8.0_251 系统:win10 64bit 问题1 官网下载commandlinetools,解压运行报错 解决方法 打开sdkmanager.bat,修改第17行为set DEFAUL ...
- spring注入bean的几种策略模式
上篇文章Spring IOC的核心机制:实例化与注入我们提到在有多个实现类的情况下,spring是如何选择特定的bean将其注入到代码片段中,我们讨论了按照名称注入和使用@Qualifier 注解输入 ...
- Python基础02 变量
Python中的变量有两个特点: 1. 无需声明 a = 1 2. 不与类型绑定 a = 1 a = 'hello world' 变量名只是内存中具体对象的一个引用(reference). 对于 a ...
- MySQL命令2
索引与外键 // 添加索引 ALTER TABLE orders ADD KEY order_ix_custid(cust_id); // 删除索引 ALTER TABLE orders DROP K ...