系统级编程(csapp)
系统级编程漫游
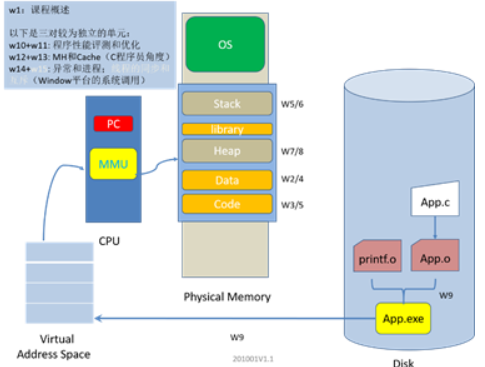
系统级编程提供学生从用户级、程序员的视角认识处理器、网络和操作系统,通过对汇编器和汇编代码、程序性能评测和优化、内存组织层次、网络协议和操作以及并行编程的学习,理解底层计算机系统对应用程序的影响,能够在编写高级语言代码的同时,思考低层次的影响与优化,即能够在系统层级进行编程及程序的优化。
编译系统的组成
一个程序的生命周期从高级语言的编写开始,然后被转化为一系列的低级机器语言指令,这些指令按照一种称为可执行目标程序的格式打包,并以二进制磁盘文件的形式存储起来。
Unix系统中,这个转化工作由GCC编译器驱动程序完成。GCC读取源文件hello.c,然后把它翻译成一个可执行目标程序hello,一共由四个阶段完成。执行这四个阶段的程序(预处理器、编译器、汇编器、链接器)一起构成了编译系统。
四个阶段的核心功能如下:
- 预处理阶段:预处理器根据字符#开头的命令,修改原始的C程序,读取进头文件的内容,直接插入到程序文本中,得到了另一个C程序- hello.i
- 编译阶段:编译器把文本文件 hello.i 翻译成文本文件 hello.s,包含一个汇编语言程序。
- 汇编阶段:汇编器把 hello.s 翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,保存在目标二进制文件 hello.o 中。
- 链接阶段:链接器负责合并各个的预编译好的目标文件,输出 hello 可执行目标文件,可以被加载到内存中,由系统执行。

操作系统概览
操作系统是介于硬件和应用程序之间的一层软件系统,所有应用程序对硬件的操作都必须经过操作系统。
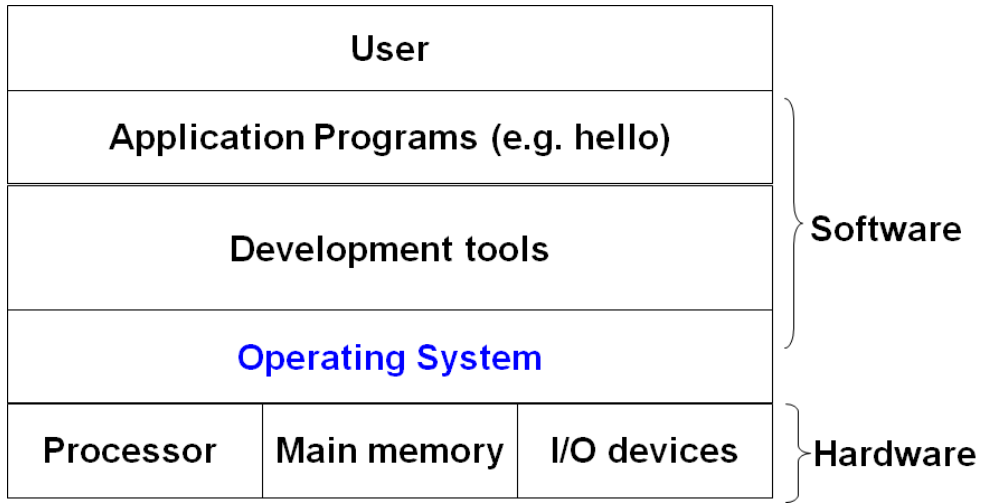
操作系统的两个基本功能是:
- 防止硬件被失控的应用程序滥用。
- 向应用程序提供简单一致的机制来控制复杂而又通常大不相同的低级硬件设备。
操作系统提供了三个抽象概念来实现这两个基本功能:
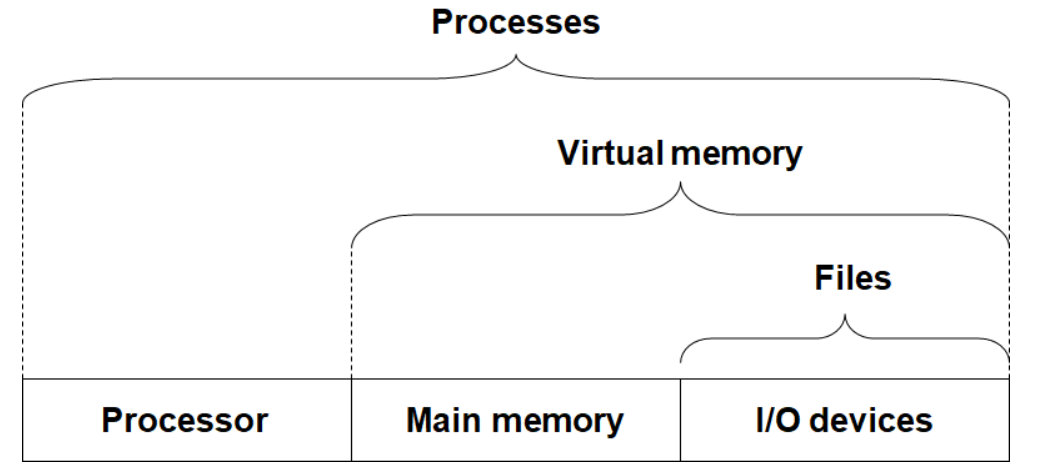
- 进程
操作系统提供了一种假象:系统上只有这个进程在运行,使程序看上去独占处理器、主存和I/O设备。实际上在一个系统上可以同时运行多个进程,进程数是可以多于CPU个数的。CPU通过在进程间快速切换来给人以所有进程都在并发执行的假象。
为了达到CPU在进程间切换的效果,操作系统负责管理进程运行的上下文,上下文包括PC、寄存器的当前值和主存的内容等。单处理器在任一时刻只能运行一个进程的代码。当操作系统决定要进行进程切换时,会先保存当前进程的上下文信息,然后将新进程的上下文恢复,并将控制权传递到新进程。新进程就会从它上次暂停的地方继续往下运行。
注:进程是操作系统进行资源分配的最小单位
在操作系统中,一个进程可以又多个称为线程的执行单元构成,每个线程都运行在进程的上下文中。同一进程中的多个线程共享代码和全局数据。
注:线程是操作系统进行任务调度和执行的最小单位
- 虚拟内存
虚拟内存提供了一种假象:每个进程都在独占地使用内存。每个进程看到的内存都是一致的,称为虚拟地址空间。
- 文件
文件就是字节序列。每个I/O设备,包括键盘、磁盘、显示器、打印机和网络都可以看成文件。系统中的所有输入输出都是通过调用一组称为Unix I/O的系统调用读写文件来实现的。
文件的概念简单而强大,它屏蔽了所有底层硬件的实现细节,通过一致的视图来操作这些硬件。这使得不同厂商提供的设备都能运行在同一台计算机上
硬件系统的组成
- 总线
贯穿整个系统的一组电子管道,携带信息字节并负责在各个部件间传递。
- IO设备
每个I/O设备都通过一个控制器或适配器与I/O总线相连。
- 主存
临时存储设备,在处理器执行程序时,用来存放程序和程序处理的数据。
主存在物理上由一组动态随机存取存储器(DRAM)芯片组成,逻辑上它是一个线性的字节数组,每个字节都有唯一的地址(数组索引),从0开始。
- 处理器
处理器是解释和执行存储在主存中指令的引擎,它的核心是一个大小为一个字的存储设备(寄存器),称作程序计数器(PC),在任何时刻,PC都指向主存中的某条机器语言指令,即PC保存的是主存中的某个地址。
处理器一直在不断地执行PC指向指令,接着更新PC,将其指向下一条指令,下一条指令的地址和刚被执行的上一条指令的地址不一定是相邻的。
处理器中包含一些拥有固定名字的寄存器,这些寄存器的大小是单个字长。
Amdahl’s Law (阿姆达尔定律)
阿姆达尔定律的主要思想是,当我们对系统的某个部分加速时,其对系统整体性能的影响取决于该部分的重要性和加速程度。其加速比公式如下:(a=该部分所占的比例 k=该部分提升的比例)
程序生命周期
- 编写 edit
在编辑器中编写出高级语言代码
- 编译 compile
高级语言源代码通过编译系统的编译,被翻译成可执行文件 - 执行 execute
可执行文件首先存储在硬盘中,当IO设备(如:键盘)读入运行命令之后,总线负责把程序从硬盘中加载到主存中,处理器进一步执行程序,然后进行输出。
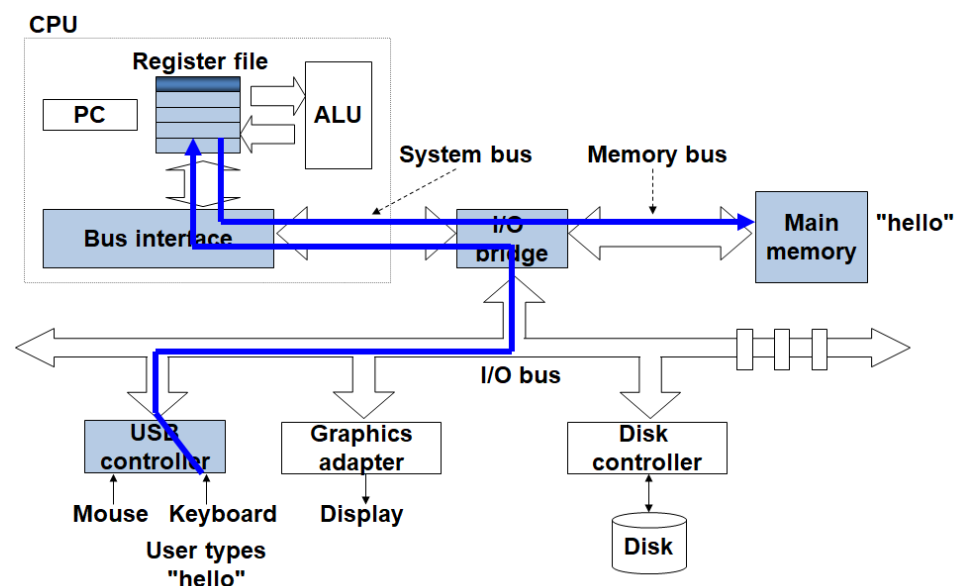
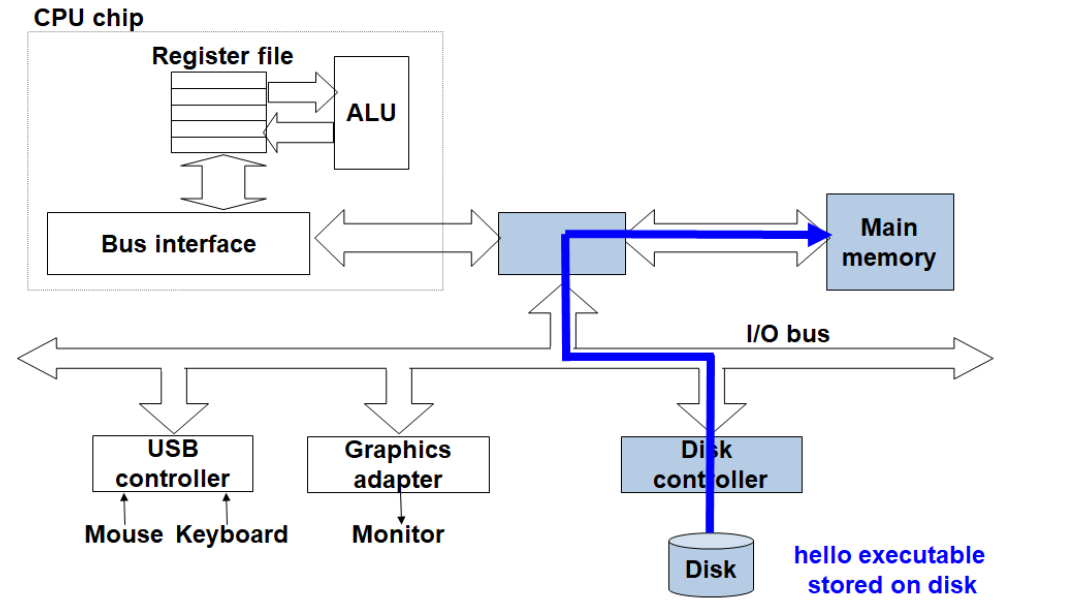
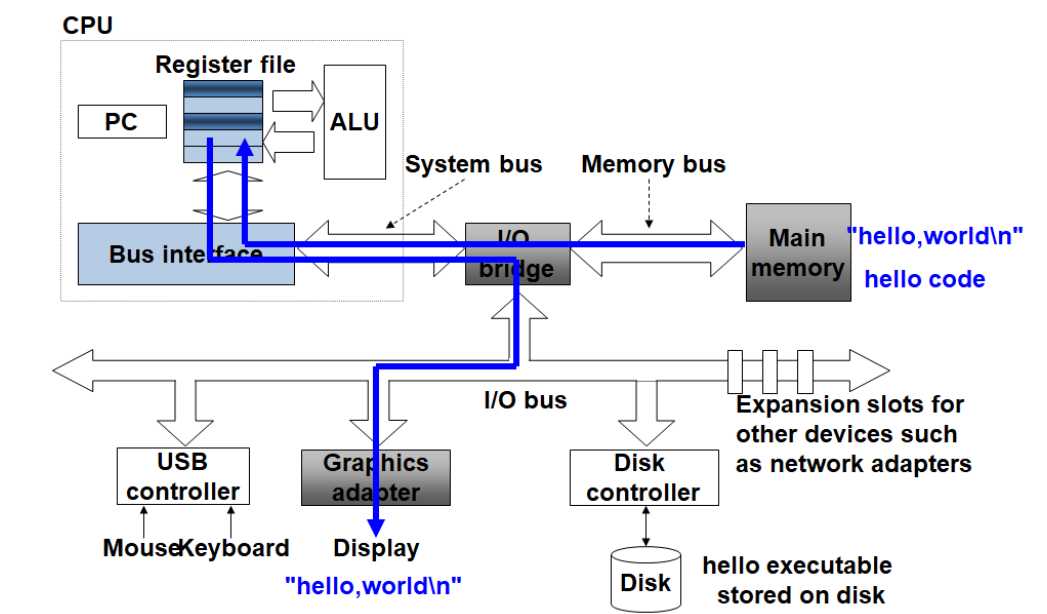
数据的表示
信息存储
整数的表示虽然只能编码一个相对较小的数值范围,但这种表示是精确的;浮点数虽然能编码一个较大的数值范围,但这种表示是近似的。
- 计算机使用字节(byte, 1byte=8bits)而不是单独的位来作为最小寻址单位。
- 机器级程序将内存视为一个非常大的字节数组,称为虚拟内存。内存的每个字节都由一个唯一的数字来标识,称为它的地址,所有可能的地址的集合就称为虚拟地址空间。
- 十六进制表示法,以0x开头表示十六进制值。
- 字长(word size)指明了指针数据的标称大小,字长决定了虚拟地址空间的最大大小。对于一个字长为w的机器而言,其虚拟地址空间范围为0-2w-1,程序最多访问2w个字节。字:固定大小的字节块
- 有两种有两种字节顺序:小端法(little endian)是最低有效字节在最前面。大端法(big endian)是最高有效字节在最前面。对于选择哪种字节顺序并没有任何技术上的理由,但是一旦选择了特定的操作系统,字节顺序就固定下来。
- C语言中的数据类型
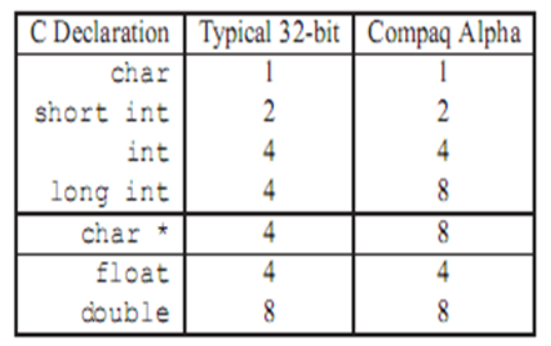
位操作
- 与或非
- Bit Shifts ( << and >> )
- 左移:x向左移动 k 位,丢弃最高的 k 位,在右端补 k 个0
- 逻辑右移:在左端补 k 个 0
- 算术右移:在左端补 k 个 最高有效位的值。
- 实际上,几乎所有的编译器和机器组合都对有符号数使用算数右移,另外对于无符号数,右移必须是逻辑
- ^: 异或: 不同为1,相同为0
- 德摩根定理:与的非等于非的与
整数的表示
- 2s补码: 二进制 取反+1

- Overflow: 16位无符号的整数最大值是63535,如果超出这个范围,就会整数溢出,整数溢出在c语言中不会被检查到,因此程序员要进行检查
- Conversion:数的不同大小表示之间发生转换
浮点数的表示
- Fixed Point Notation:定点数形式
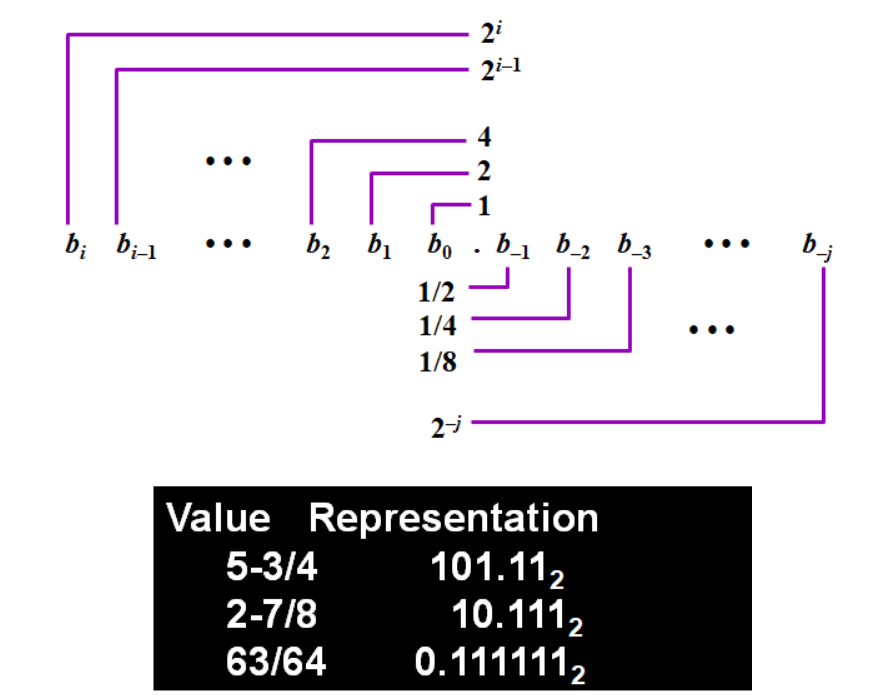

- BCD (Binary-Coded Decimal)
用二进制替换十进制数

- IEEE Floating Point
- 表现形式
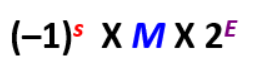

- 计算方式:
E (真值) = Exp(机器表示(移码)) – Bias(偏移量) 32位的时候 Bias-127
M = 1 + frac = 1.xxx…x

- 逆运算:
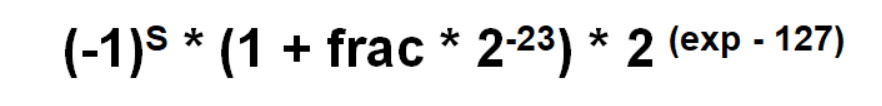
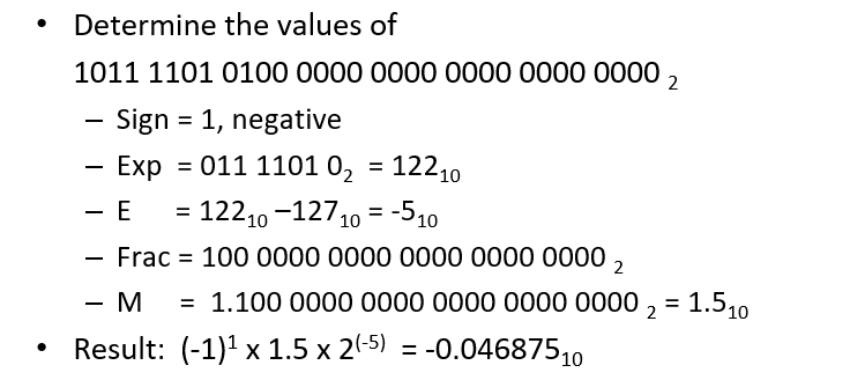
- 非规格化的 E全为0: E=1-Bias M=f
- 特殊值: E全为1: M 全为 0 的时候表示无穷大 ,否则表示 NaN
程序的表示
寄存器
寄存器分成两种类型:用户寄存器和控制寄存器。用户寄存器如数据寄存器、地址寄存器,是ALU的一部分;控制寄存器如PC,IR,Status Flags,Stack Pointer,是CU的一部分。

前六个寄存器称为通用寄存器,有其『特定』的用途:
- ax 累加器:加法和乘法指令的缺省寄存器,存储函数返回值
- bx 基址寄存器:在内存寻址时存放基地址
- cx 计数器: REP & LOOP 指令的内定计数器
- dx 除法寄存器:存放整数除法产生的余数
- si 源索引寄存器:用于保存源索引值
- di 目标索引寄存器:用于保存目标索引值
%rsp(%esp) 和 %rbp(%ebp) 则是作为栈指针和基指针来使用的。
操作数
三种基本类型:立即数(Imm)、寄存器值(Reg)和内存值(Mem)
对于 movq 指令来说,需要源操作数和目标操作数,源操作数可以是立即数、寄存器值或内存值的任意一种,但目标操作数只能是寄存器值或内存值。指令的具体格式可以这样写 movq [Imm|Reg|Mem], [Reg|Mem],第一个是源操作数,第二个是目标操作数:
movq Imm, Reg -> mov $0x5, %rax -> temp = 0x5;
movq Imm, Mem -> mov $0x5, (%rax) -> *p = 0x5;
movq Reg, Reg -> mov %rax, %rdx -> temp2 = temp1;
movq Reg, Mem -> mov %rax, (%rdx) -> *p = temp;
movq Mem, Reg -> mov (%rax), %rdx -> temp = *p;
这里有一种情况是不存在的,没有 movq Mem, Mem 这个方式,也就是说,我们没有办法用一条指令完成内存间的数据交换。
上面的例子中有些操作数是带括号的,括号的意思就是寻址,这也分两种情况:
- 普通模式,(R),相当于
Mem[Reg[R]],也就是说寄存器 R 指定内存地址,类似于 C 语言中的指针,语法为:movq (%rcx), %rax也就是说以 %rcx 寄存器中存储的地址去内存里找对应的数据,存到寄存器 %rax 中
- 移位模式,D(R),相当于
Mem[Reg[R]+D],寄存器 R 给出起始的内存地址,然后 D 是偏移量,语法为:movq 8(%rbp),%rdx也就是说以 %rbp 寄存器中存储的地址再加上 8 个偏移量去内存里找对应的数据,存到寄存器 %rdx 中
对于寻址来说,比较通用的格式是 D(Rb, Ri, S) -> Mem[Reg[Rb]+S*Reg[Ri]+D],其中:
D- 常数偏移量
Rb- 基寄存器
Ri- 索引寄存器,不能是 %rsp
S- 系数
除此之外,还有如下三种特殊情况
(Rb, Ri)->Mem[Reg[Rb]+Reg[Ri]]
D(Rb, Ri)->Mem[Reg[Rb]+Reg[Ri]+D]
(Rb, Ri, S)->Mem[Reg[Rb]+S*Reg[Ri]]
指令
- Fetch-Execute Cycle
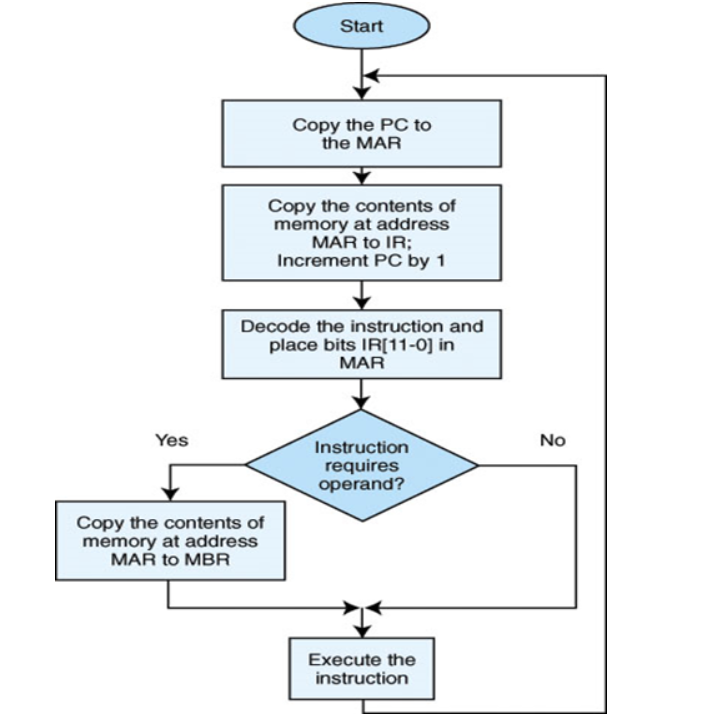
- 指令集
- 数据传送类
MOV PUSH POP LEA IN
- 算术运算类
ADD CMP
- 位与逻辑运算类
TEST
- 字符串处理类
STOSB REPE/REPZ REPNE/REPNZ
- 控制转移类
JMP CALL RET
- 处理器控制类
汇编语言
- 语言风格
- GAS Style :GAS(GNU Assembly)/AT&T - The one on the CSAPP book
- MASM Style:Intel/MASM- The one that we use on VC ++ IDE
- 区别
- 两者的源操作数和目的操作数的位置相反
- 前者的汇编指令中带有后缀(如b/w/l),指示操作数的长度(8/16/32 bits)
- s前者在寄存器前加“%”,在常数和符号地址前加“$”
- 前者间接寻址用( )表示,而后者用[ ]表示
- –movl %edx,%eax mov eax,edx
–movl (%edx),%eax mov eax,[edx]
- 汇编语言的元素
–Constants Statements Instructions Identifiers
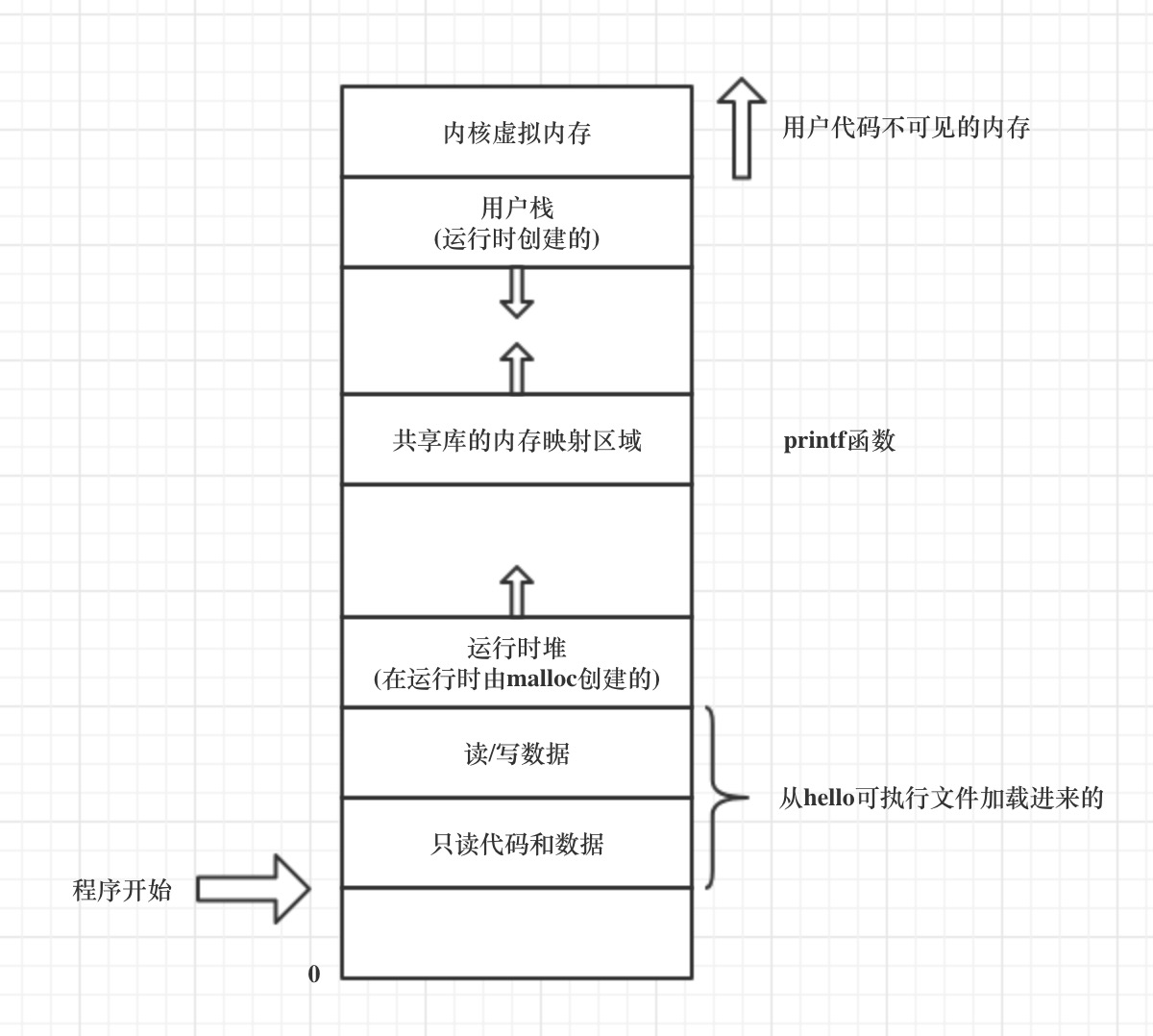
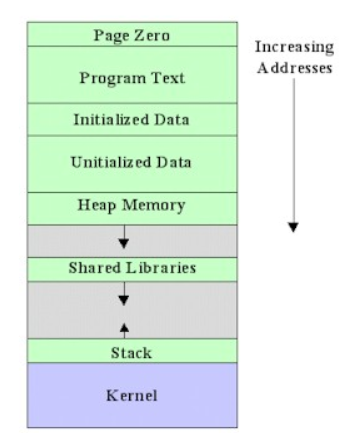
内存分配和布局
结构化数据
- 虚拟内存的大致分布
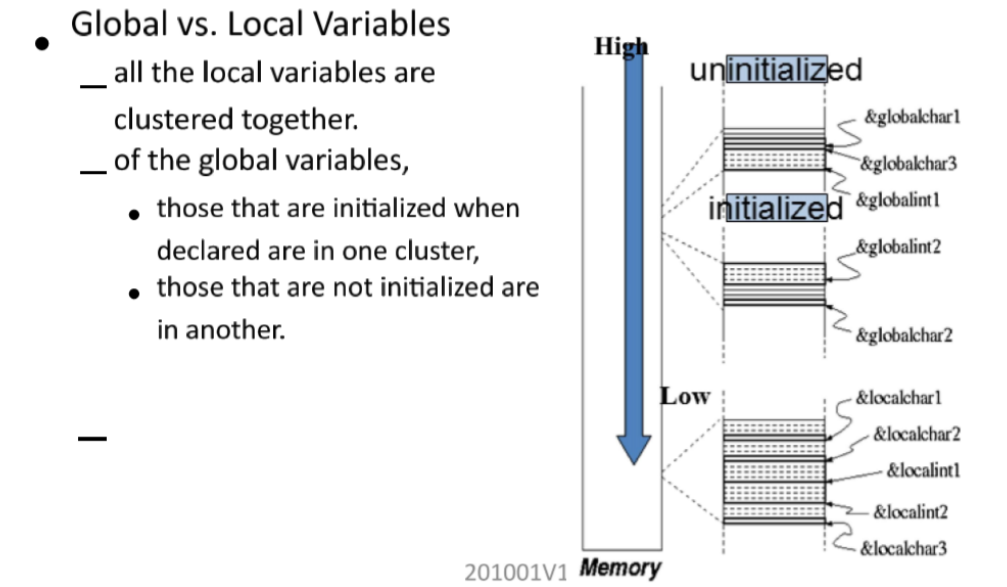
- 全局变量 vs 局部变量
- 数据存储在内存中,机器没有类型和变量的概念,只有位和字节的概念。所以所有的变量都可以通过字节来表示,所以可以通过一个读入一个 character 当作 int。
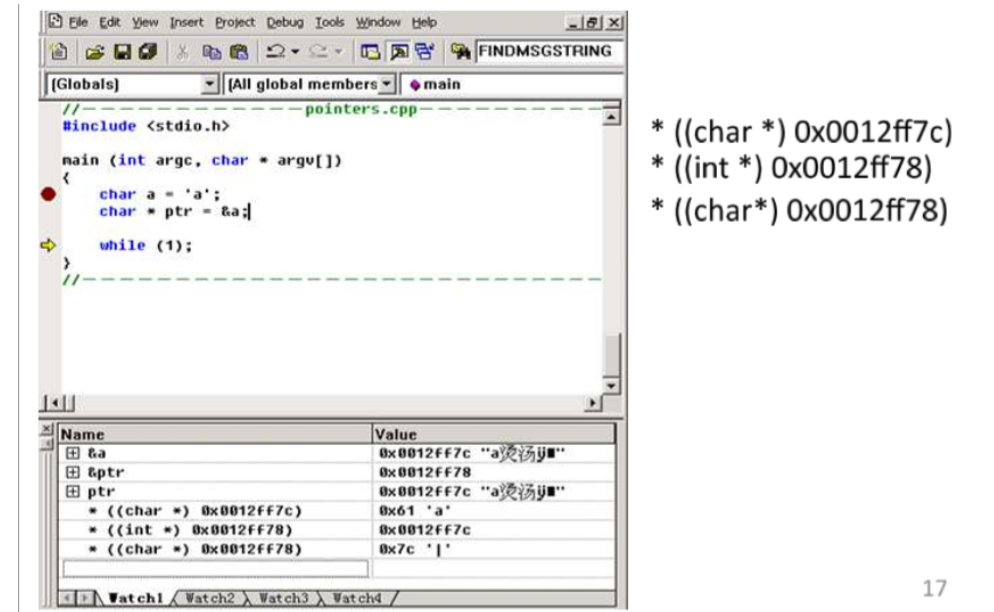
- 指针:我们可以通过引用来共享参数,而不需要进行赋值。指针赋予了动态分配内存的能力。但是使用好指针需要我们对所有的内存进行管理。
- 数组跟指针是可以转化的:指针指向数组的第一个元素
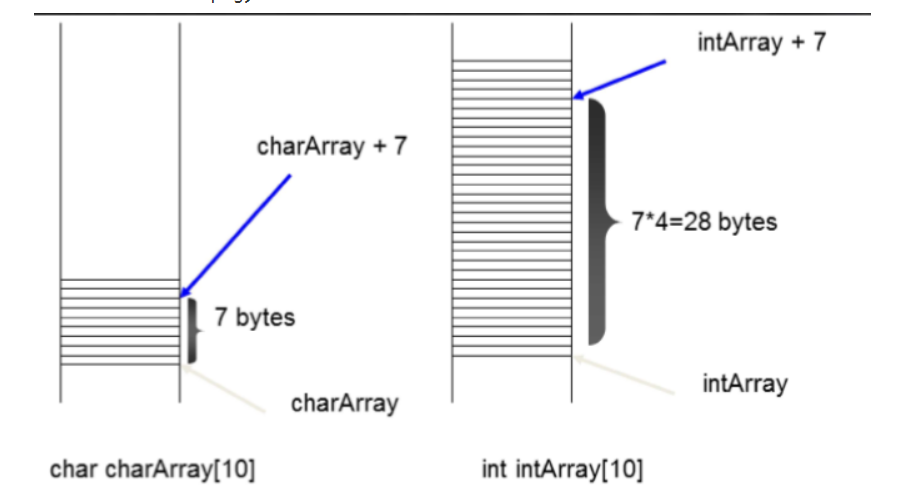
(区别char 和 int 型的数组,在增长的时候,intArray需要*4)
myarray + N = &(myarray[N])
myarray[N] = *(myarray + N)
–a[n] [m] == (a[n])[m] == ((a[n]) + m) == ((a + n*3) + m)
- 指针的运算
- 加、减:移动指针到下一个/上一个 元素,偏移量与数据类型,即类型的字节数相关。例如,当前地址为1000,如果是一个int型的指针,ptr++ 后 指向1004, 如果是一个char* 指针 ptr++ 后 指向1001

**&a 的类型是 int[5] a的类型是 int
- 相等、大于、小于
- 字符串:C语言中没有字符串类型,是一个char数组以 ‘\0’ (0x00)结尾。
- 结构体:长度计算 1. alignment 取最大 2. size 取 alignment 和 元素个数的 乘积
- 联合体:size 取 最大元素的 size
- 对齐(Alignment):对齐数据边界甚至允许到双字边界,使用padding来对齐。能够提升计算机查找的效率
函数调用和栈帧
- 变量和参数
- 变量具有生存域:同名的变量也会被映射到不同地址存储来实现域,如局部变量和全局变量
- 形参和实参也是存在不同的地址中,防止其操作带来的影响。
- 按值传递和按引用传递(传递地址)
- 参数的实现机制
全局变量会被静态的分配,在程序执行之前;局部变量则是动态分配(编译器也会实现留出一个大空间给局部变量),同样的,实参也是需要被动态分配的。
- Activation Record and Stack Frame
- 为了最小化动态分配的成本,编译器计算每一个 function 需要的总空间,并把这些空间放在一个 chunk 中,这就是激活记录/栈帧。显然,他们是被存储在栈中的。
- 硬件的支持:stack pointer register esp;frame pointer register ebp
- 规则:只有栈顶的激活记录能够被访问;分配规律:从高地址向低地址(栈顶)拓展
- 调用/返回的过程
当函数发生调用的时候,调用方需要进行保存现场:
- push parameters & return address into the stack
被调用方需要构造自己的栈帧:
- push frame pointer (ebp) into the stack
- set the ebp equal to esp
- allocate a chunk of memory by decrement the stack pointer(esp) by as many memory addresses as are required to store the local state of the callee.
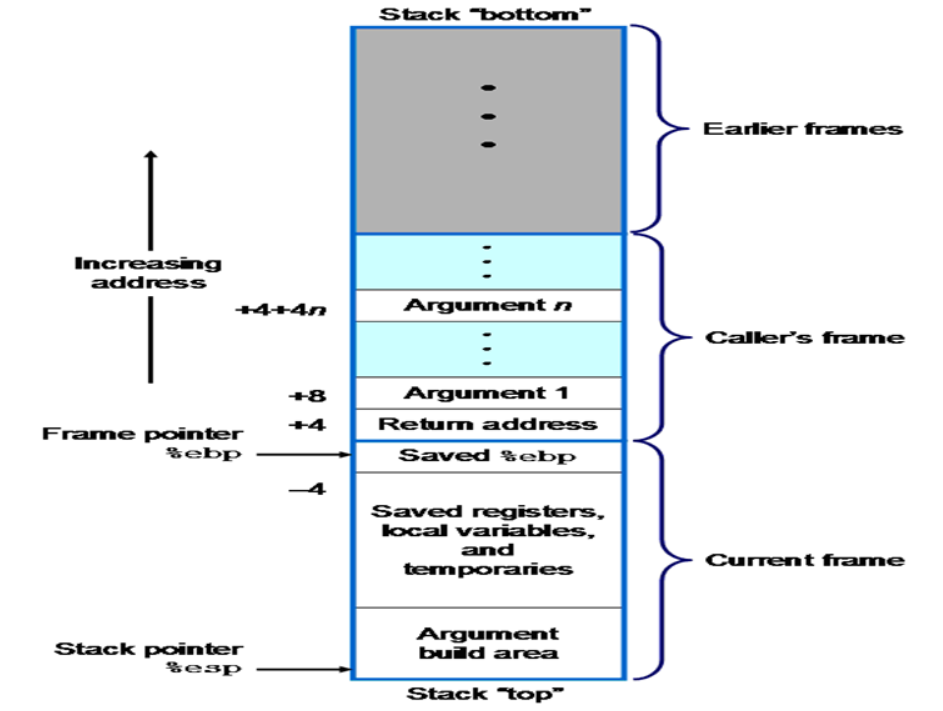
- 函数调用规则
_cdecl(C语言默认的规则)
- 参数顺序: 从右到左入栈
- 参数存储位置
- 寄存器使用
- 调用方还是被调用方进行unwinding?调用方负责清理栈上面的函数
静态内存分配
- 静态意味着发生在编译和链接时期,编译完成之后,不能够修改
- 所有的全局变量、声明为静态的局部变量、explicit constants(strings sets) 都进行静态分配
- 静态分配会在main函数之前开始,之后结束。局部静态变量只有在作用域中起作用,每次调用不会重新初始化。
- 静态分配的问题
- 命名困难
- 程序在运行前不能很准确的知道需要多大的存储
- 静态分配预留了内存空间,但是有时候某个数据结构只是暂时性的被需要
- 递归调用无法实现
动态内存分配
- 动态是指在运行期间分配内存
- 栈分配:Allocated & deallocated in last-in, first-out order, with functions calls and returns
- Register EBP indicates highest stack address
- Register ESP indicates lowest stack address (address of top element)
- Pushing : Decrement esp by 4 & Write operand at address given by ESP
- Poping: Increment esp by 4 & Write to Dest
- 堆分配:Allocated and deallocated memory at arbitrary times & programs use to store data(eg. malloc).
- 栈是自动分配的,当在作用域的时候创建,不在域的时候摧毁;堆是手工分配的,创建和摧毁都基于请求
int main() {
int myInt; // declare an int on the stack
myInt = 5; // set the memory to five
return 0;
}
int main() {
int* myInt = (int*) malloc(sizeof(int));
if ( myInt != NULL ) {
*myInt = 5;
// free is uesd to release memory but
// do not: free memory in stack or free same memory twice
free(myInt);
myInt = NULL; //Should set pointer to NULL when done
}
return 0;
}
- 栈和堆的区别
- 栈:快速访问 ,不需要释放内存块, 空间由CPU管理,内存不会被fragment,仅限局部变量,限制于栈的大小,大小不能改变
- 堆:相对慢,需要自己来管理内存,效率无法保证,内存会被fragment,变量可以重新调整大小(realloc)
内存分配算法
- 内存分配的困难: malloc会分配之前没有使用过的内存,算法要能够决定哪些块能够使用
- 常见算法
- First Fit: 第一块满足条件的
- Best Fit: 与要求最贴切的
- Worst Fit: 最大的内存块
内存缺陷
- 野指针:指向“垃圾”内存的指针。人们一般不会错用NULL指针,因为用if语句很容易判断。
- 指针变量没有被初始化。任何指针变量刚被创建时不会自动成为NULL指针,它的缺省值是随机的,它会乱指一气。所以,指针变量在创建的同时应当被初始化,要么将指针设置为NULL,要么让它指向合法的内存。
- 指针p被free或者delete之后,没有置为NULL,让人误以为p是个合法的指针。
- 指针操作超越了变量的作用范围。这种情况让人防不胜防,示例程序如下:
class A
{
public:
void Func(void){ cout << “Func of class A” << endl; }
};
void Test(void)
{
A *p;
{
A a;
p = &a; // 注意 a 的生命期
}
p->Func(); // p是“野指针”
}其他各种的错误程序 (bad references)
void GetMemory (char* p, int num) {
p = (char *) malloc(sizeof(char) * num);
}
void main (void) {
char *str = NULL;
GetMemory(str, 100);
strcpy(str, "hello");
}char *GetString(void){
char p[ ] = "hello world";
return p;
// 编译器将提出警告
}
void main (void) {
char *str = NULL;
str = GetString();
// str 的内容是垃圾
cout<< str << endl;
} //correct code char *GetString(void){
char *p = "hello world";
return p;
}
void main (void){
char *str = NULL;
str = GetString();
cout<< str << endl;
}int i;
double d;
// wrong!!!
scanf("%d %lf", i, d);
// here is the correct call:
scanf("%d %lf", &i, &d);int* ptr_to_zero() {
int i = 0;
return &i;
}
//不要用return语句返回指向“栈内存”的指针
- Overwrite Problem
- 数组访问越界
#define array_size 100
int* a = (int *) malloc(sizeof(int) * array_size);
for (int i = 0; i <= array_size; i++)
a[i] = NULL;
- 内存分配,大小指定错误
#define array_size 100
int *a = (int *) malloc(array_size);
a[99] = 0; // this overwrites memory beyond the block //correct
int *a = (int *) malloc( array_size* sizeof(int));
- 输入超出内存空间
char s[8];
int i;
gets(s); /* reads “123456789” from stdin */
- String要以 \0 结尾、
char *heapify_string(char *s) {
int len = strlen(s);
char *new_s = (char *) malloc(len);
strcpy(new_s, s);
return new_s;
}
//correct
char *new_s = (char *) malloc(len + 1);
- 二次释放 (twice free)
- 内存泄漏(memory leak)
- 不再使用的内存没有回到内存池中
- 最终系统会用光所有的内存
- 是一个慢性、长期的内存杀手,多数的异常、错误都是由内存泄漏引起的
- 特别注意一种情形,当释放结构体的时候,只释放了结构体本身,没有释放结构体内部属性所指向的内存空间
typedef struct {
char *name;
int age;
char *address;
int phone;
} Person;
void my_function() {
Person *p = (Person *) malloc(sizeof(Person));
p->name = (char *) malloc(M); ...
p->address = (char *) malloc(N); ...
free(p); // what about name and address?
}
- Exterminating Memory Bugs
内存管理
- keep track of memory allocation
- bitmap: an array of bits, one per allocation chunk
- linked list : stores contiguous regions of free or allocated memory
- Implicit free list using lengths : 隐式空闲链表
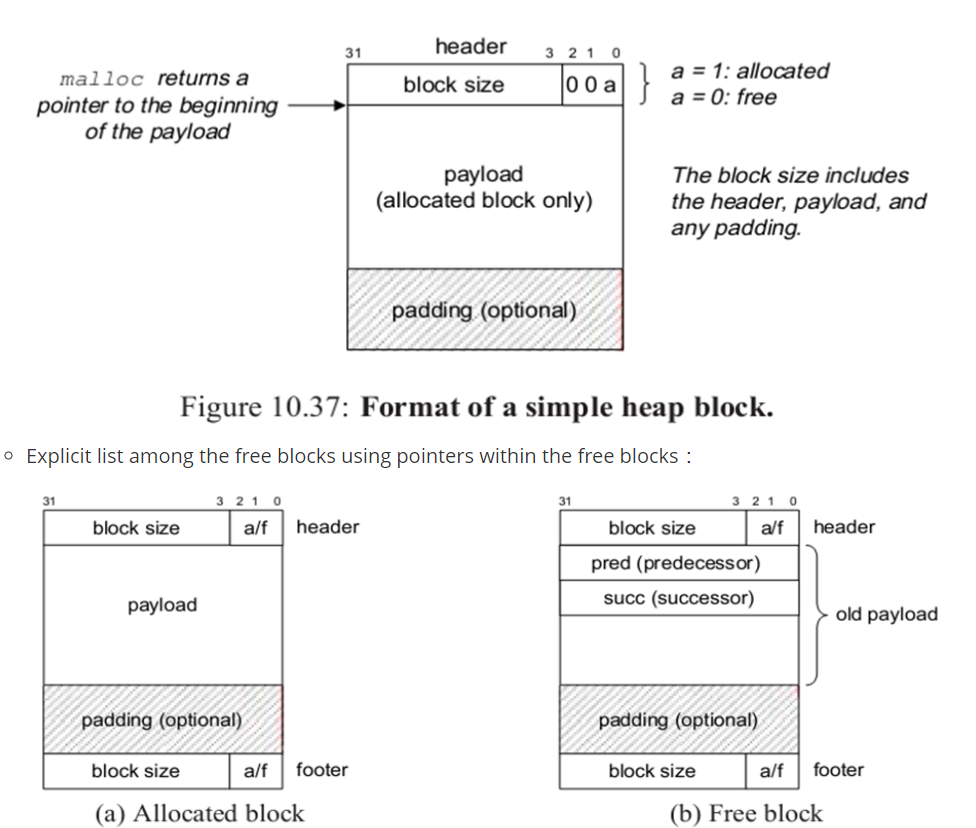
- Explicit list among the free blocks using pointers within the free blocks :
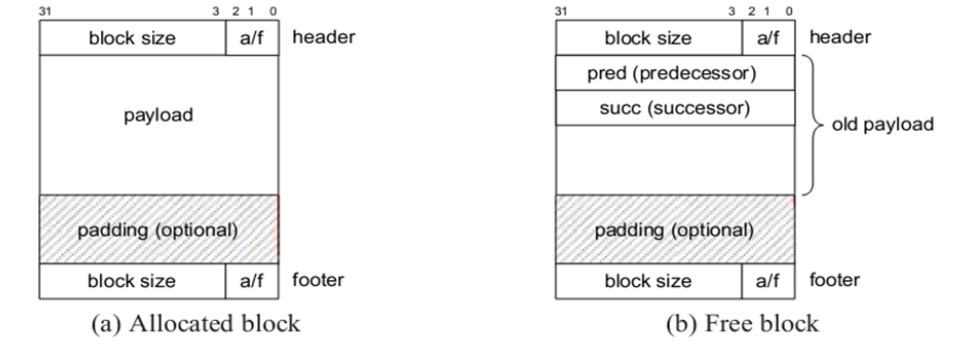
- Segregated free lists 分离的空闲链表
Different free lists for different size classes
- Blocks sorted by size :
Can use a balanced tree (e.g. Red-Black tree) with pointers within each free block, and the length used as a key
- Placement Policy
- First Fit
- Best Fit
- Worst Fit
- Segregated Fit (分离适配)
- 确定请求类的大小,并且对适当的空闲链表做首次适配,查找合适的块
- 如果找到一个,我们(可选地)分割它,并将剩余的部分插入到适当的空闲链表中
- 如果找不到,我们就搜索下一个更大的大小类的空闲链表。如此重复,直到找到一个合适的块
- 如果没有空闲链aaaaa'a'a'a'a'a'a'a'a'a表中有合适的块,那么就向操作系统请求额外的对存储器,从这个新的对存储器中分配出一个块,将剩余的部分放置在最大的大小类中。
- Splitting Free Blocks
- Getting Additional Heap Memory
- Coalescing free blocks:Immediate coalescing (立即合并) & Deferred coalescing (推迟合并)
- Asks the kernel for additional heap memory
- Deallocation
- Coalesce: To combine two or more nodes into one. (with Boundary Tags(边界标记))
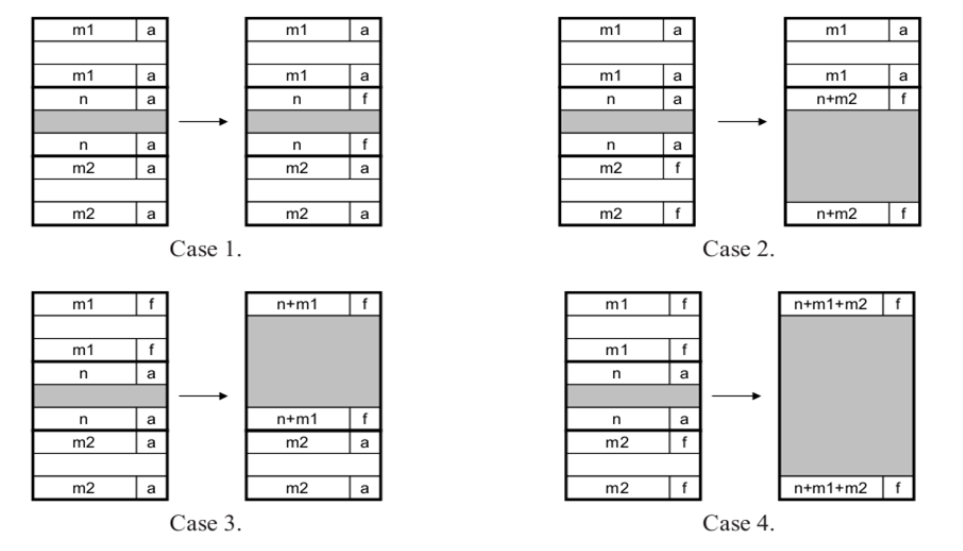
- Dynamic Memory Management
- Explicit Memory Management (EMM)
- Automatic Memory Management (AMM)
- Lazy processing: blocks are reorganized only if needed
- Implicit Memory Management -- application never has to free
- automatic reclamation of heap-allocated storage
- Common in functional languages, scripting languages, and modern object oriented languages: Lisp, Java, Perl, …
垃圾回收
- Mark and Sweep Collecting 标记清除法
- Use extra mark bit in the head of each block
- Mark: Start at roots and sets mark bit on all reachable memory
- Sweep: Scan all blocks and free blocks that are not marked
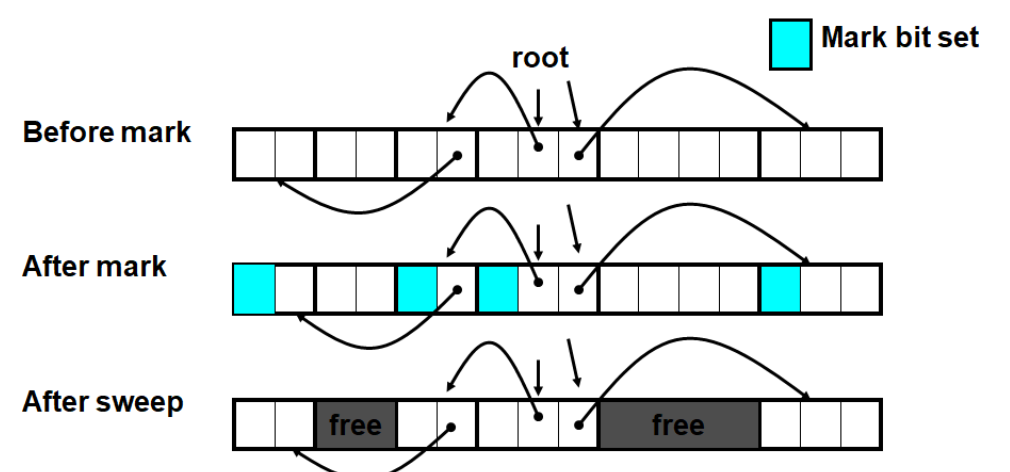
void mark ( ptr p ) {
if (( b = isPtr(p)) == NULL)
return;
if ( blockMarked(b))
return;
markBlock(b);
len = length(b);
for (i=0; i < len; i++)
mark(b[i]); //mark all child
return;
}
void sweep ( ptr b, ptr end) {
while (b < end) {
if (blockMarked(b))
unmarkBlock(b);
else if (blockAllocated(b))
free(b);
b = nextBlock(b);
}
return;
}
- Copying Collection 复制法
- use 2 heaps
- One used by program & The other unused until GC time
- Process:
- Start at the roots & traverse the reachable data
- Copy reachable data from the active heap (from-space) to the other heap (to-space)
- Dead objects are left behind in from space
- Heaps switch roles
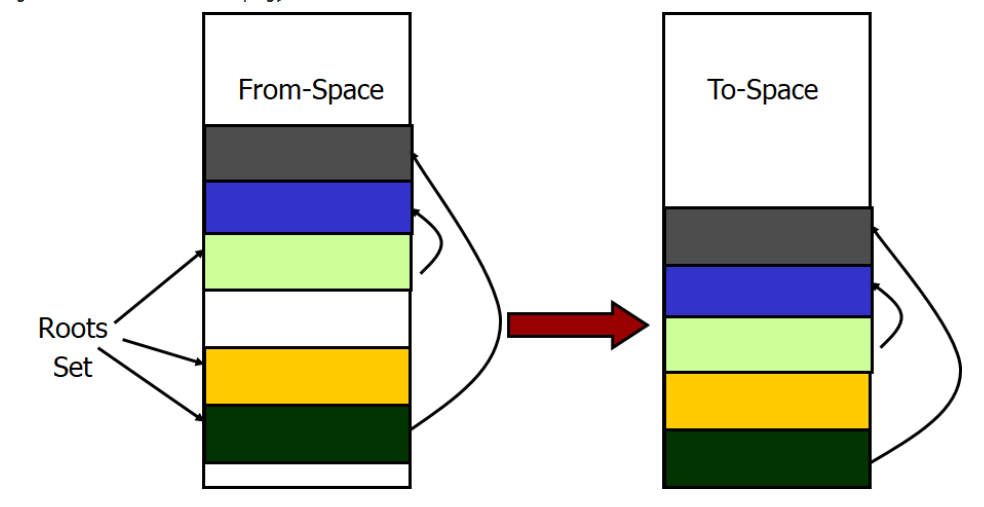
- Reference Counting
- Keep track of the number of pointers to each object (the reference count).
- When the reference count goes to 0, the object is unreachable garbage
- Generational GC 分代式垃圾回收法
- If an object has been reachable for a long time, it is likely to remain so
- In many languages, most objects died young
- we save work by scanning the young objects frequently and the old objects infrequently
- process:
- Assign objects to different generations G0, G1,…
- •G0 contains young objects, most likely to be garbage
•G0 scanned more often than G1
- 总结
- 引用计数是解决显式内存分配问题的常用解决方案。实现赋值时递增和递减操作的代码通常是程序缓慢的原因之一。无论如何,引用计数也不是全面的解决方案,因为循环引用从不会被删除。
- 垃圾回收只会在内存变得紧张时才会运行。当内存尚且宽裕时,程序将全速运行,不会在释放内存上花费任何时间。
- 分代, 复制回收程序在很大程度上克服了早期的标记&清除算法的低效。
- 现代垃圾回收程序进行堆紧缩。堆紧缩将减少程序引用的页的数量,这意味着内存访问命中率将更高,交换将更少。
- 采用垃圾回收的程序不会因为内存泄漏的累积而崩溃。采用 GC 的程序拥有更长期的稳定性。
- 采用垃圾回收的程序更容易发现指针错漏。 这是因为没有指向已经释放的内存的悬挂指针。因为没有显式的内存管理代码,也就不可能有相应的错漏。
- 垃圾回收并非什么仙丹妙药。它有着以下不足:
•内存回收何时运行是不可预测的,所以程序可能意外暂停。
•运行内存回收的时间是没有上界的。尽管在实践中它的运行通常很快,但无法保证这一点。
•除了回收程序以外的所有线程在回收进行时都会停止运行。
- 垃圾回收程序也许会留下一些本该回收的内存
- 垃圾回收应该被实现为一个基本的操作系统内核服务。但是现实并非如此,造成了采用垃圾回收的程序被迫带着它们的垃圾回收实现到处跑。显式内存回收程序通常会把内存放回自己的内部内存池中而不是把内存交还给操作系统。
链接和加载
链接器
- 功能:将可重定位的目标文件(包括库)转化为可执行目标文件。静态链接在编译之后进行,动态链接在加载和运行期间进行。
- 主要任务:
- 符号解析:将每个符号引用正好和一个符号定义关联起来,每个符号对应一个函数、一个全局变量或一个静态变量。
- 重定位:把每个符号定义与一个内存位置关联起来,重定位这些节,然后修改所有对这些符号的引用。
- 静态链接:在我们的实际开发中,不可能将所有代码放在一个源文件中,所以会出现多个源文件,而且多个源文件之间不是独立的,而会存在多种依赖关系,如一个源文件可能要调用另一个源文件中定义的函数,但是每个源文件都是独立编译的,即每个.c文件会形成一个.o文件,为了满足前面说的依赖关系,则需要将这些源文件产生的目标文件进行链接,从而形成一个可以执行的程序。这个链接的过程就是静态链接。
优缺点:浪费空间,更新困难(如果库函数的代码修改,需要重新编译链接);在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快。
- 动态链接:动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。
- 链接器的重要性:
- 帮助构造大型程序
- 避免一些危险的编程错误,如解析符号引用出现的错误
- 理解语言的作用域规则的实现
- 理解其他重要的系统概念:加载和运行程序、虚拟内存、分页、内存映射
- 利用共享库
- 链接过程
- 符号解析
链接器只知道非静态的全局变量/函数,而对于局部变量一无所知;局部非静态变量会保存在栈中;局部静态变量会保存在.bss或.data中
- 聚合
- 重定位
把不同可重定位对象文件拼成可执行对象文件
当链接器进行链接的时候,首先决定各个目标文件在最终可执行文件里的位置。然后访问所有目标文件的地址重定义表,对其中记录的地址进行重定向(加上一个偏移量,即该编译单元在可执行文件上的起始地址)。然后遍历所有目标文件的未解决符号表,并且在所有的导出符号表里查找匹配的符号,并在未解决符号表中所记录的位置上填写实现地址。最后把所有的目标文件的内容写在各自的位置上,再作一些另的工作,就生成一个可执行文件。
目标文件格式
- 目标文件格式:
- File header
包含文件属性:是否可执行、动态还是静态编译、启动地址、操作系统 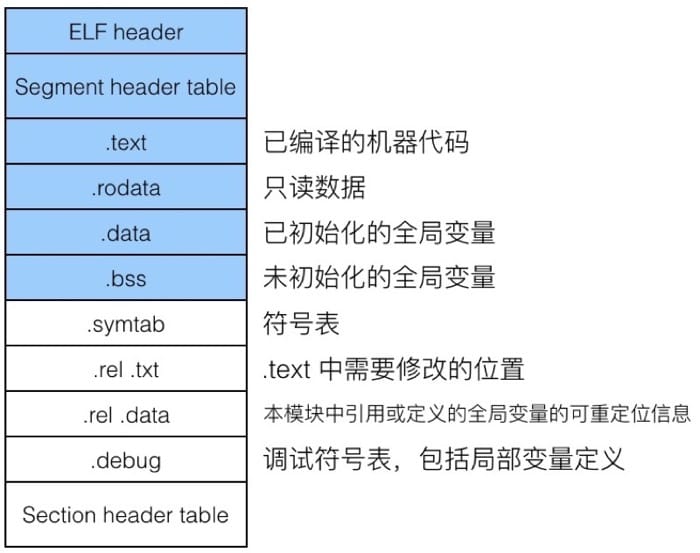
- Sections
包含 text data bss 三个节,包含已编译的机器代码、已初始化的全局变量、未初始化的全局变量
把数据和代码放在不同的section中,能够 1. 保护代码 2. 提升命中率 3.共享内存
此外还有如 .rodate .symtab .rel .txt .rel .data .debug - Section header table
描述每一个区的 名字、长度、偏移量、是否可读可写
- 目标文件类型:
- 可重定位:包含二进制代码和数据,如 .o .a .lib .obj
- 可执行: 包含二进制代码和数据,可以复制到内存中执行,如 /bin/bash .out .exe
- 共享:一种特殊类型的可重定位目标文件,可以在加载或者运行时被动态地加载到内存中并链接,如 .so .dll
符号解析
- 在链接器的上下文中,有三种不同的符号
- 由模块m定义并被其他模块引用的 全局符号。对应于非静态的C函数和全局变量
- 由其他模块定义并被模块m引用的 全局符号,也称外部符号。 对应于在其他模块中定义的非静态的C函数和全局变量
- 只被模块m定义和引用的 局部符号。对应于带 static 属性的 C函数和全局变量,这些符号在模块m中随处可见,但是不能被其他模块引用。
- 多重定义的全局符号
- 强符号:函数和初始化的全局变量
- 弱符号:未初始化的全局变量
链接器在处理强弱符号的时候遵守以下规则:
- 不能出现多个同名的强符号,不然就会出现链接错误
- 如果有同名的强符号和弱符号,选择强符号,也就意味着弱符号是『无效』d而
- 如果有多个弱符号,随便选择一个
- 静态库:将所有相关的目标模块打包成为一个单独的文件,成为静态库,可以用作链接器的输入。
重定位
- 重定位的功能
完成了符号解析之后,代码中的符号引用和符号定义就关联起来了,并且链接器也知道目标模块中代码节和数据节的确切大小。此时进行重定位, 合并输入模块,为每个符号分配运行时地址:
- 重定位节和符号定义:合并相同类型的节为聚合节;
- 重定位节中的符号引用:修改代码节和数据节中对每个符号的引用,使得他们指向正确的运行时地址。
- 重定位条目:汇编器遇到对最终位置未知的目标引用,就会生成一个重定位条目,告诉链接器如何修改引用。
- 重定位算法:
事先知道 text 和 m.symobl 的重定位地址
- 相对引用:
refaddr=ARRD(text)+ m.offset
*refptr= (unsigned) (ADDR(m.symbol)+m.append -refaddr)
- 绝对引用
*refptr= (unsigned) (ADDR(m.symbol)+m.append )
加载
Liux系统中的每个程序都运行在一个进程上下文中,有自己的虚拟地址空间。
当shell运行一个程序时,父shell进程生成一个子进程,是父进程的复制。子进程通过execve系统调用启动加载器
加载器删除子进程现有的虚拟内存段,并创建一组新的代码、数据、堆和栈段。新的栈和堆段被初始化为零。通过将虚拟地址空间中的页映射到可执行文件的页的大小的片,新的代码和数据段被初始化为可执行文件的内容。
加载器跳转到-_start地址,调用应用程序的main函数。
除了一些头部信息,没有任何从磁盘到内存的数据复制。直到CPU引用一个被映射的虚拟页时才会进行复制。此时,操作系统利用他的页面调度机制自动将页面从磁盘传送到内存。
优化程序性能
性能优化的逻辑问题
- 性能测量:这个程序是不是 run fast
bottlenecks/ Hot spots
- 优化程序:怎么让程序变得更快
创建基准线 找到程序中的瓶颈 找到归因 优化代码 重新测试
性能测量原则
- 二八定理
80%的CPU运行时间和资源被20%的程序占用
锁定20%的代码就能获得更好的性能
- Amdahl’s Law
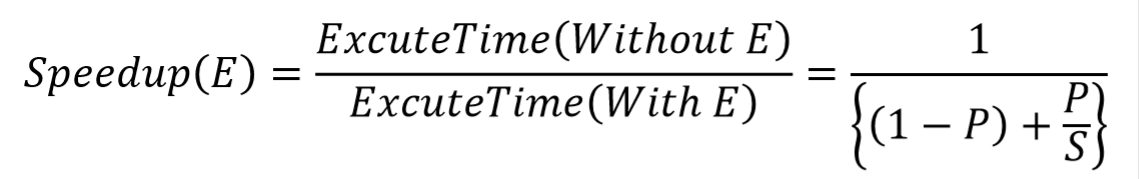
p=该部分所占的比例 s=该部分提升的比例
性能测量方式
- 测量对象:时间(墙上时钟时间、CPU时间)
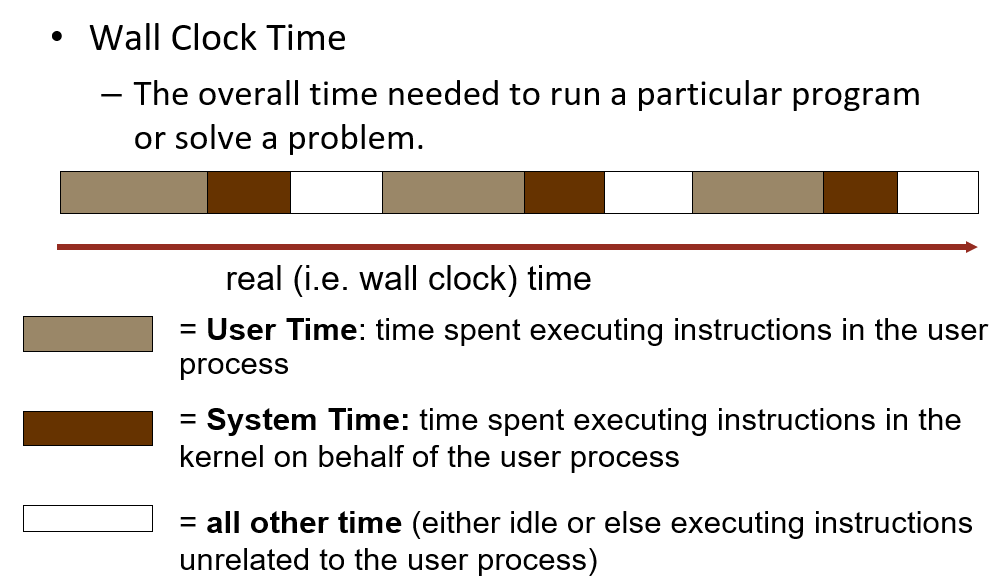
CPU time = user CPU time + system CPU time
Wall Clock Time > CPU time
- 测量工具:Timer (硬件、操作系统、编程语言 c/c++)
- In Hardware
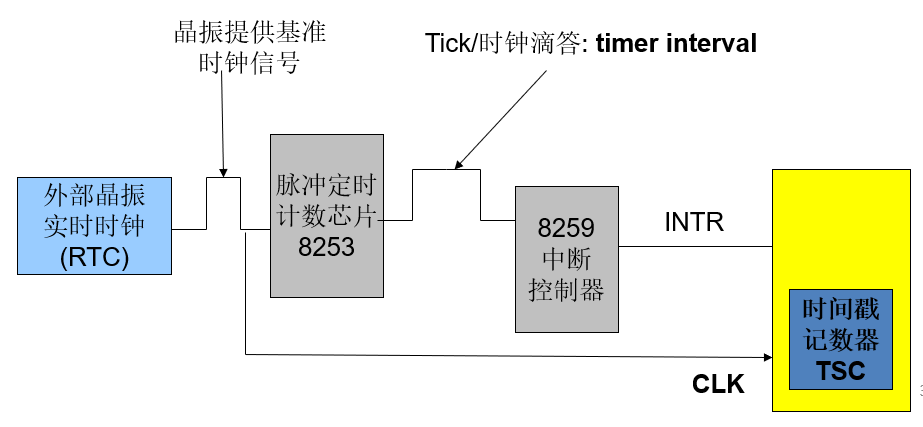
- Real Time CMOS Clock:
使用CMOS RAM 来存储时间
原理是使用晶体振荡器产生原始时钟频率
Clock Cycle (时钟周期/振荡周期 ) = seconds per cycle
Clock Frequency (时钟频率) = cycles per second (1 Hz.=1 cycle/sec), etc.14.318MHz
- PIT: 可编程间隔定时器
- TSC: 时间戳记数器
- In Os
以Windows为例,系统时间计时始于:启动的时候读取RTC后,进行转换。Windows time是自上次启动系统以来经过的毫秒数。Windows时间周期为49.7天。返回值是一个DWORD类型:DWORD GetTickCount(void);
- In C/C++
•数据类型:clock_t, time_t
•结构:struct tm
•函数: Clock() Time() Difftime() Mktime() .....
总结:
在硬件中,是通过时钟和外部晶体实时时钟RTC以及时间戳TSC
在操作系统中,是通过读取RTC后,通过系统调用时间函数,和时间片来确定时间的
在程序中是通过CLOCK(函数),通过其返回的值来确定当前的时间
- 测量技术:抽样分析
- 原理:计时器周期性地中断程序并记录程序计数器,然后估计在程序中花费的时间,进一步检查程序是否将大部分时间花在几个地方
- 原因:节省时间和成本,高效
- 工具:GNU Gprof ; Vtune ; VC profiler
分析器 (profiler/profiling) 的主要功能在于 1. 确认引起程序瓶颈的主要代码块 2. 哪个部分的代码被最为频繁的调用
优化程序性能
- 用好编译器的不同参数设定
- 写对编译器友好的代码,尤其是过程调用和内存引用,时刻注意内层循环
- 根据机器来优化代码,包括利用指令级并行、避免不可以预测的分支以及有效利用缓存
最根源的优化是对编译器的优化,比方说在寄存器分配、代码排序和选择、死代码消除、效率提升等方面,都可以由编译器做一定的辅助工作。
但是因为这毕竟是一个自动的过程,而代码本身可以非常多样,在不能改变程序行为的前提下,很多时候编译器的优化策略是趋于保守的。并且大部分用来优化的信息来自于过程和静态信息,很难充分进行动态优化。
接下来会介绍一些我们自己需要注意的地方,而不是依赖处理器或者编译器来解决。
代码移动
如果一个表达式总是得到同样的结果,最好把它移动到循环外面,这样只需要计算一次。编译器有时候可以自动完成,比如说使用 -O1 优化。一个例子:
void set_row(double *a, double *b, long i, long n){
long j;
for (j = 0; j < n; j++){
a[n*i + j] = b[j];
}
}
这里 n*i 是重复被计算的,可以放到循环外面
long j;
int ni = n * i;
for (j = 0; j < n; j++){
a[ni + j] = b[j];
}
减少计算强度
用更简单的表达式来完成用时较久的操作,例如 16*x 就可以用 x << 4 代替,一个比较明显的例子是,可以把乘积转化位一系列的加法,如下:
for (i = 0; i < n; i++){
int ni = n * i;
for (j = 0; j < n; j++)
a[ni + j] = b[j];
}
可以把 n*i 用加法代替,比如:
int ni = 0;
for (i = 0; i < n; i++){
for (j = 0; j < n; j++)
a[ni + j] = b[j];
ni += n;
}
公共子表达式
可以重用部分表达式的计算结果,例如:
/* Sum neighbors of i, j */
up = val[(i-1)*n + j ];
down = val[(i+1)*n + j ];
left = val[i*n + j-1];
right = val[i*n + j+1];
sum = up + down + left + right;
可以优化为
long inj = i*n + j;
up = val[inj - n];
down = val[inj + n];
left = val[inj - 1];
right = val[inj + 1];
sum = up + down + left + right;
虽然说,现代处理器对乘法也有很好的优化,但是既然可以从 3 次乘法运算减少到只需要 1 次,为什么不这样做呢?蚂蚁再小也是肉嘛。
小心过程调用
void lower1(char *s){
size_t i;
for (i = 0; i < strlen(s); i++)
if (s[i] >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
}
在字符串长度增加的时候,时间复杂度是二次方的!每次循环中都会调用一次 strlen(s),而这个函数本身需要通过遍历字符串来取得长度,因此时间复杂度就成了二次方。
那么只计算一次就好了:
void lower2(char *s){
size_t i;
size_t len = strlen(s);
for (i = 0; i < len; i++)
if (s[i] >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
}
为什么编译器不能自动把这个过程调用给移到外面去呢?
编译器的策略必须是保守的,因为过程调用之后所发生的事情是不可控的,所以不能直接改变代码逻辑,比方说,假如 strlen 这个函数改变了字符串 s 的长度,那么每次都需要重新计算。如果移出去的话,就会导致问题。
所以很多时候只能靠程序员自己进行代码优化。
注意内存问题
接下来我们看另一段代码及其汇编代码
// 把 nxn 的矩阵 a 的每一行加起来,存到向量 b 中
void sum_rows1(double *a, double *b, long n)
{
long i, j;
for (i = 0; i < n; i++)
{
b[i] = 0;
for (j = 0; j < n; j++)
b[i] += a[i*n + j];
}
}
对应的汇编代码为
# sum_rows1 的内循环
.L4:
movsd (%rsi, %rax, 8), %xmm0 # 浮点数载入
addsd (%rdi), %xmm0 # 浮点数加
movsd %xmm0, (%rsi, %rax, 8) # 浮点数保存
addq $8, %rdi
cmpq %rcx, %rdi
jne .L4
可以看到在汇编中,每次都会把 b[i] 存进去再读出来,为什么编译器会有这么奇怪的做法呢?因为有可能这里的 a 和 b 指向的是同一块内存地址,那么每次更新,都会使得值发生变化。但是中间过程是什么,实际上是没有必要存储起来的,所以我们引入一个临时变量,这样就可以消除内存引用的问题。
// 把 nxn 的矩阵 a 的每一行加起来,存到向量 b 中
void sum_rows2(double *a, double *b, long n)
{
long i, j;
for (i = 0; i < n; i++)
{
double val = 0;
for (j = 0; j < n; j++)
val += a[i*n + j];
b[i] = val;
}
}
对应的汇编代码为
# sum_rows2 内循环
.L10:
addsd (%rdi), %xmm0 # 浮点数载入 + 加法
addq $9, %rdi
cmpq %rax, %rdi
jne .L10
可以看到,加入了临时变量后,解决了奇怪的内存问题,生成的汇编代码干净了许多。
处理条件分支
这个问题,如果不是对处理器执行指令的机制有一定了解的话,可能会难以理解。
现代处理器普遍采用超标量设计,也就是基于流水线来进行指令的处理,也就是说,当执行当前指令时,接下来要执行的几条指令已经进入流水线的处理流程了。
这个很重要,对于顺序执行来说,不会有任何问题,但是对于条件分支来说,在跳转指令时可能会改变程序的走向,也就是说,之前载入的指令可能是无效的。这个时候就只能清空流水线,然后重新进行载入。为了减少清空流水线所带来的性能损失,处理器内部会采用称为『分支预测』的技术。
比方说在一个循环中,根据预测,可能除了最后一次跳出循环的时候会判断错误之外,其他都是没有问题的。这就可以接受,但是如果处理器不停判断错误的话(比方说代码逻辑写得很奇怪),性能就会得到极大的拖累。
分支问题有些时候会成为最主要的影响性能的因素,但有的时候其实很难避免。
存储器层次结构
存储技术
存储技术分为三大板块:随机访问存储器、磁盘存储、固态硬盘
随机访问存储器
- 静态RAM
静态RAM比动态RAM更快也更贵,常用来做高速缓存存储器。将每个位存储在一个双稳态存储器单元里,只要有电,就能保持稳定值。 【每位晶体管-6 相对访问时间-1x 花费-1000x 持续 不敏感 】
- 动态RAM
DRAM用来作为主存以及图形系统的帧缓冲区。将每个为存储为对一个电容的充电。每个单元由一个电容和一个访问晶体管组成,对干扰比较敏感。【每位晶体管-1 相对访问时间-10x 花费-1x 持续 不敏感 】
- 传统的DRAM: DRAM芯片中的单元被分成d个超单元,每个超单元被分成w个 DRAM 单元。 一个d*w 的 DRAM单元存储了 dw 位信息。DRAM被组织成二维阵列能够降低芯片上地址引脚的数量,但是也因此必须分两次发送地址,增加了访问时间。
- 内存模块:DRAM芯片封装在内存模块中,插到主板的扩展槽上。分为:SIMM (Single Inline Memory Module) 单列直插内存模块 && DIMM (Dual Inline Memory Module) 双列直插内存模块。多个模块连接到内存控制器,能够聚合成主存。
- 增强的DRAM:•快页模式 •扩展数据输出 •同步DRAM •Rambus DRAM •双倍速率SDRAM
- 非易失性存储器
无论是 DRAM 还是 SRAM,一旦不通电,所有的信息都会丢失。由于历史原因,整体都被成为 ROM (read-only Memory),虽然现在有的类型是可写的。 ROM以他们能够被重编程(重写)的次数和对它们进行重编程的机制来进行区分:
- PROM: 可编程,只能被编程一次,每个存储器单元有一种熔丝,只能用高电流熔断一次。
- EPROM:可擦除可编程,利用光进行擦除,可以达到1000次
- EEPROM:电可擦除可编程,可达到100000次
- Flash Memory:基于EEPROM,为大量的电子设备提供快速持久的存储,如数码相机、手机、音乐播放器等
固件程序会存储在 ROM 中(比如 BIOS,磁盘控制器,网卡,图形加速器,安全子系统等等)
硬盘存储(传统机械硬盘)
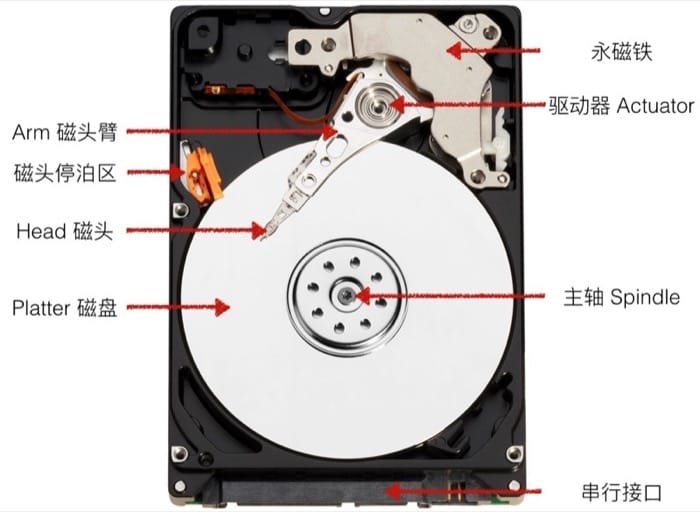
机械硬盘有许多片磁盘(platter)组成,每一片磁盘有两面;每一面由一圈圈的磁道(track)组成,而每个磁道会被分隔成不同的扇区(sector)。
//
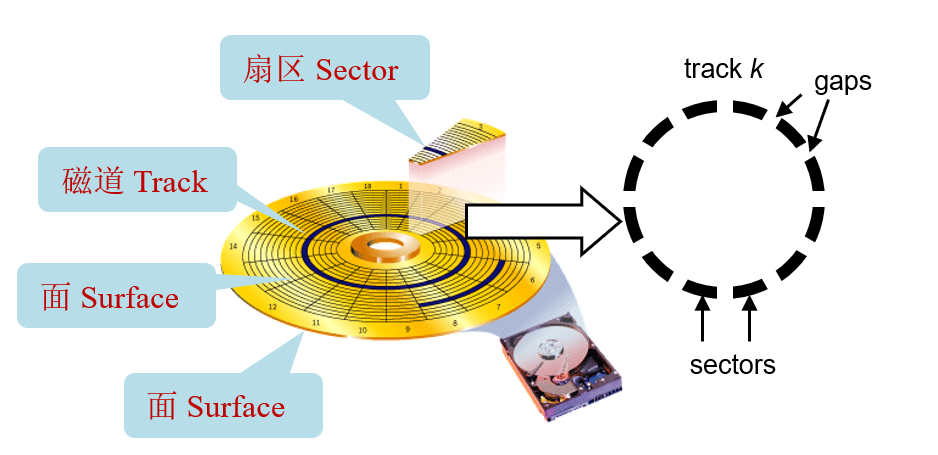
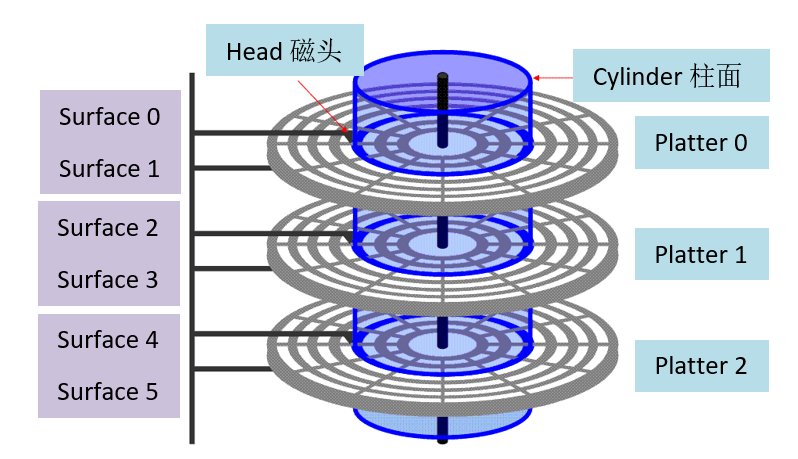
硬盘的容量指的是最大能存储的比特数,与硬盘的结构分层类似,容量取决于下面三个方面:
- 记录密度(bits/in):track 中 1 英寸能保存的字节数
- 磁道密度(tracks/in):1 英寸直径能保存多少条 track
- Areal 密度(bits/in 的平方):上面两个数值的乘积
现在硬盘会把相邻的若干个磁道切分成小块,每一块叫做记录区(recording zone)。记录区中的每条磁道都包含同样数量的扇区(sector);但是每个记录区中包含的扇区和磁道的数目是不一样的,外层的更多,内层的更少;正因为如此,我们计算容量用的是平均的数值。
容量 Capacity = 每个扇区的字节数(bytes/sector) x 磁道上的平均扇区数(avg sectors/track) x 磁盘一面的磁道数(tracks/surface) x 磁盘的面数(surfaces/platter) x 硬盘包含的磁盘数(platters/disk)
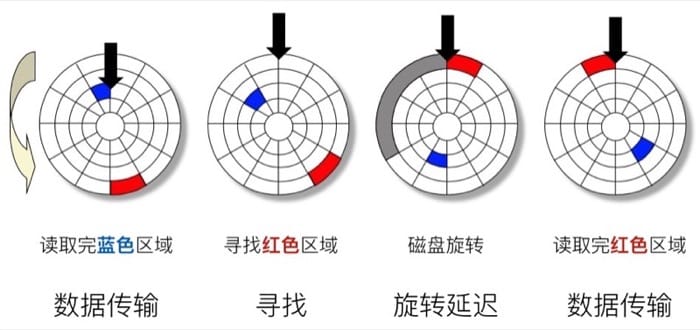
假设我们现在已经从蓝色区域读取完了数据,接下来需要从红色区域读,首先需要寻址,把读取的指针放到红色区域所在的磁道,然后等待磁盘旋转,旋转到红色区域之后,才可以开始真正的数据传输过程。
总的访问时间 Taccess = 寻址时间 Tavg seek + 旋转时间 Tavg rotation + 传输时间 Tavg transfer
- 寻址时间 Tavg seek 因为物理规律的限制,一般是 3-9 ms
- 旋转延迟 Tavg rotation 取决于硬盘具体的转速,一般来说是 7200 RPM,
T= (60s/min)/(2×PRM)
- 传输时间 Tavg tranfer 就是需要读取的扇区数目
T= (60s/min)/RPM×1/(avg #sectors/track)
举个例子,假设转速是 7200 RPM,平均寻址时间 9ms,平均每个磁道的 sector 数目是 400,那么我们有:
- Tavg rotation = 1/2 x (60 secs / 7200 RPM) x 1000 ms/sec = 4 ms
- Tavg transfer = 60 / 7200 RPM x 1/400 secs/track x 1000 ms/sec = 0.02 ms
- Taccess = 9 ms + 4 ms + 0.02 ms
从这里可以看出,主要决定访问时间的是寻址时间和旋转延迟;读取一个扇区的第一个比特是非常耗时的,之后的都几乎可以忽略不计;硬盘比 SRAM 慢 40,000 倍,比 DRAM 慢 2500 倍。
最后需要知道的就是逻辑分区和实际的物理分区的区别,为了使用方便,会用连续的数字来标志所有可用的扇区,具体的映射工作由磁盘控制器完成。
磁盘控制器的主要功能包括: 逻辑分区到物理分区的映射、 磁盘的操作控制、缓存、中断
固态硬盘
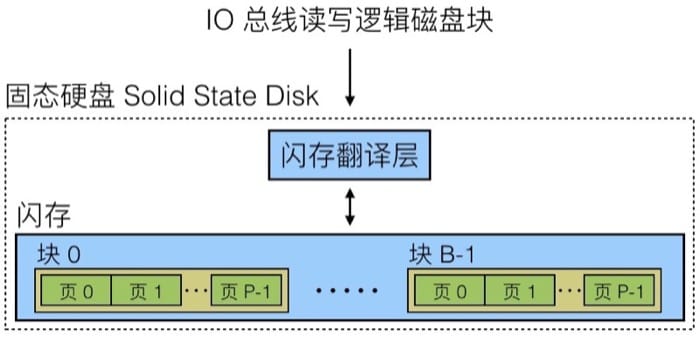
一个SSD由一个或多个闪存芯片和一个闪存翻译层组成,闪存芯片替代传统磁盘中的机械驱动器,闪存翻译层是一个硬件/固件设备,扮演与磁盘控制器相同的角色,将对逻辑块的请求翻译成对底层物理设备的访问。
固态硬盘中分成很多的块(Block),每个块又有很多页(Page),大约 32-128 个,每个页可以存放一定数据(大概 4-512KB),页是进行数据读写的最小单位。但是有一点需要注意,对一个页进行写入操作的时候,需要先把整个块清空(设计限制),而一个块大概在 100,000 次写入之后就会报废。
与传统的机械硬盘相比,固态硬盘在读写速度上有很大的优势。但是因为设计本身的约束,连续访问会比随机访问快,但是如果需要写入 Page,那么需要移动其他 Page,擦除整个 Block,然后才能写入,则相对慢。现在固态硬盘的读写速度差距已经没有以前那么大了,但是仍然有一些差距。
不过与机械硬盘相比,固态硬盘存在一个具体的寿命限制,价格也比较贵,但是因为速度上的优势,越来越多设备开始使用固态硬盘。
存储技术趋势
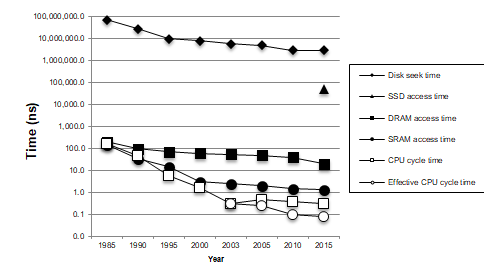
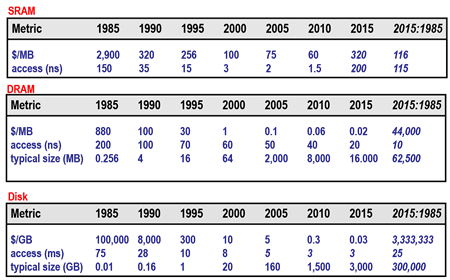
现代计算机频繁地使用基于SRAM的高速缓存,试图弥补 处理器-内存 之间的差距。这种方法行之有效是因为应用程序的一个称为局部性原理的基本属性。
局部性原理
- 时间局部性(Temporal Locality): 如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。程序循环、堆栈等是产生时间局部性的原因。
- 空间局部性(Spatial Locality): 在最近的将来将用到的信息很可能与现在正在使用的信息在空间地址上是临近的
- 顺序局部性(Order Locality): 在典型程序中,除转移类指令外,大部分指令是顺序进行的。顺序执行和非顺序执行的比例大致是5:1。此外,对大型数组访问也是顺序的。指令的顺序执行、数组的连续存放等是产生顺序局部性的原因。
sum = 0;
for (i = 0; i < n; i++){
sum += a[i];
}
return sum;
这里每次循环都会访问 sum 是满足时间局部性的;数组的访问是连续的,属于空间局部性。
根据这个特性,在写遍历数组的时候(尤其是高维),尤其要注意按照内存排列顺序来访问,不然性能会惨不忍睹。程序员应该理解局部性原理:有良好局部性的程序比局部性差的程序运行得更快。在硬件层,高速缓存存储器的小而快速的存储器来保存最近被引用的指令和数据项,从而提高对主存的访问速度。在操作系统级,局部性原理允许系统使用主存作为虚拟地址空间最近被引用块的高速缓存,用主存来缓存磁盘文件系统中最近被使用的缓存块。
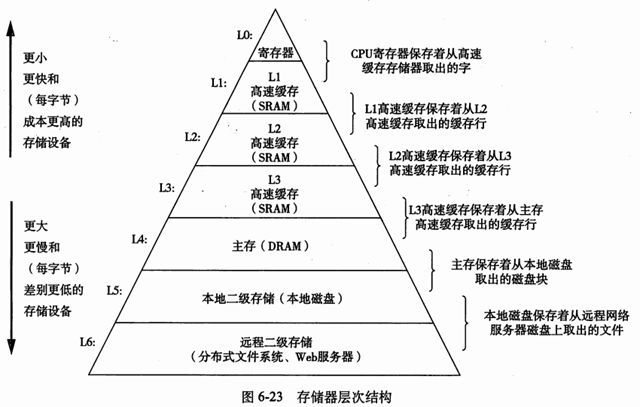
存储器层次结构
存储器层次结构呈金字塔状。从上至下,设备的访问速度越来越慢,容量越来越大,单位字节的造价越来越低。
存储器层次结构的主要思想是上一层存储器作为下一层存储器的高速缓存。
利用局部性原理,程序会更倾向于访问第 k 层的数据,而非第 k+1 层,这样就减少了访问时间。
缓存管理
- 缓存命中:当程序需要 k+1 层的某个数据对象 d 时,它首先在当前存储在第 k 层的一个块中查找 d 。如果 d 刚好缓存在第 k 层中,那么就称为缓存命中。
- 缓存不命中:如果第k层中没有缓存数据对象d,那么就是缓存不命中。
- 强制性失效(Cold/compulsory Miss): CPU 第一次访问相应缓存块,缓存中肯定没有对应数据,这是不可避免的
- 冲突失效(Confilict Miss): 在直接相联或组相联的缓存中,不同的缓存块由于索引相同相互替换,引起的失效叫做冲突失效。
- 容量失效(Capacity Miss): 有限的缓存容量导致缓存放不下而被替换,被替换出去的缓存块再被访问,引起的失效叫做容量失效
- 覆盖:当发生缓存不命中的时候,第k层的缓存会从第k+1层的缓存中取出包含 d 的那个块。如果第k层的缓存已经满了,可能就会覆盖现存的一个块。
- 缓存管理的各种政策
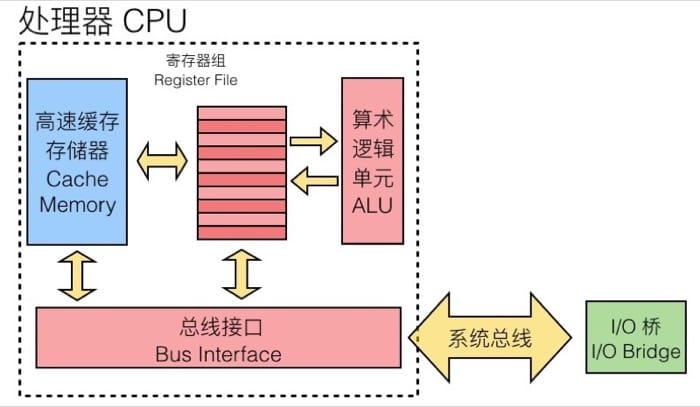
高速缓冲存储器
高速缓存存储器是由硬件自动管理的 SRAM 内存,CPU 会首先从这里找数据,其所处的位置如下(蓝色部分):
高速缓冲存储器的组成有三个部分:
- S 表示集合(set)数量
- E 表示数据行(line)的数量
- B 表示每个缓存块(block)保存的字节数目
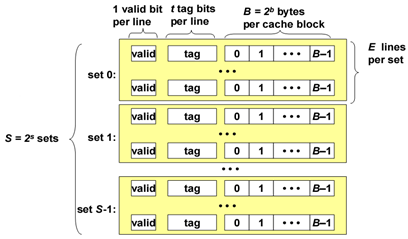
缓存中存放数据的空间大小为:C=S×E×B
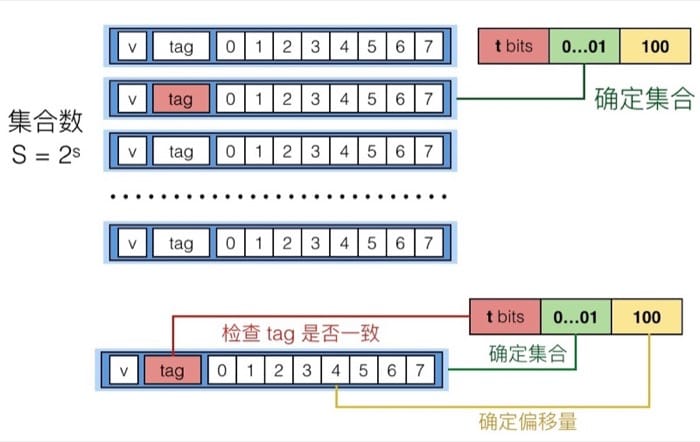
实际上可以理解为三种层级关系,对应不同的索引,这样分层的好处在于,通过层级关系简化搜索需要的时间,并且和字节的排布也是一一对应的。当处理器需要访问一个地址时,会先在高速缓冲存储器中进行查找,查找过程中我们首先在概念上把这个地址划分成三个部分:

读取过程:
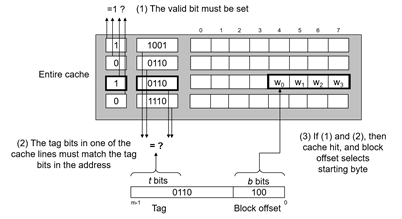
具体在从缓存中读取一个地址时,首先我们通过 set index 确定要在哪个 set 中寻找,确定后利用 tag 和同一个 set 中的每个 line 进行比对,找到 tag 相同的那个 line,最后再根据 block offset 确定要从 line 的哪个位置读起(这里的 line 和 block 是一个意思)。这个过程可以记为:组选择+行匹配+字提取
写入过程:
在整个存储层级中,不同的层级可能会存放同一个数据的不同拷贝(如 L1, L2, L3, 主内存, 硬盘)。如果发生写入命中的时候(也就是要写入的地址在缓存中有),有两种策略:
- Write-through: 命中后更新缓存,同时写入到内存中
- Write-back: 直到这个缓存需要被置换出去,才写入到内存中(需要额外的 dirty bit 来表示缓存中的数据是否和内存中相同,因为可能在其他的时候内存中对应地址的数据已经更新,那么重复写入就会导致原有数据丢失)
在写入 miss 的时候,同样有两种方式:
- Write-allocate: 载入到缓存中,并更新缓存(如果之后还需要对其操作,这个方式就比较好)
- No-write-allocate: 直接写入到内存中,不载入到缓存
这四种策略通常的搭配是:
- Write-through + No-write-allocate
- Write-back + Write-allocate
其中第一种可以保证绝对的数据一致性,第二种效率会比较高(通常情况下)。
高速缓存类型
根据每个组的高速缓存行数E,高速缓存被分为不同的类。
直接映射(Direct Mapped Cache)
每个组只有一行的高速缓存。映射方式:Y=X mod N
- 组选择:从w的地址空间中间抽取 s 个组索引位。
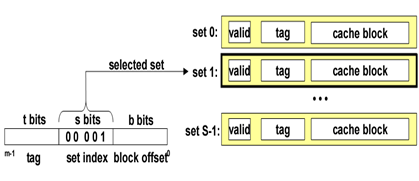
- 行匹配:当且仅当设置了有效位,并且tag与w地址中的tag匹配的时候,缓存中存在w的副本。
- 字选择:块偏移量提供了所需要的第一个字节的偏移。
- 不命中时的行替换
每个组只包含有一行,因此直接用新取出的行替换当前的行即可(根据组索引来定位)。
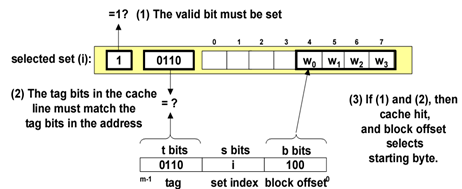
全相联高速缓存(fully assocative cache)
一个组包含所有的行。E=C/B (C: cache size B: block size )
映射方式:允许主存中每一个字块映射到Cache中的任何一块位置上。(当Cache查找时,所有标记都需要进行比对)
- 组选择:只有一个组,所以地址中没有组索引。
- 行匹配和字选择
标记和数据块一起存放在高速缓存中,当进行搜索的时候,CPU会将主存的标记域与Cache中的所有合法标记域进行比对(按内容寻址),如果比对成功,则找到,否则发生miss。如果Cache已经装满了,需要使用一种置换算法来决定从cache中丢弃的数据块(victim block),最简单的置换算法是FIFO,但较少使用,还有LRU等其他算法。
全相联映射降低了块的冲突率,提高了cache的命中率,但是增加了tag的位数,同时需要特殊的硬件支持,成本高,通常使用在小容量的Cache中。
(tag field唯一确定和标识一个数据块,增加了位数就需要更多的存储容量支持)
组关联高速缓存(set associtative cache)
每一组保存多于一个小于C/B的高速缓存行。优化冲突不命中的问题。
映射方式:将数据块映射到由几个高速缓存块组成的某个块组中,同一个高速缓存中的所有组的大小必须相同。
- 组选择:与直接映射相同,组索引表示组
- 行匹配:需要检查多个行的标记位和有效位,确定所有请求的字是否在集合中。
- 字选择:跟之前一样
- 行替换: 如果没有空行,需要进行抉择:随机选择 —> 利用局部性原理来替换将来引用可能性最小的行 如 最不常使用、最近最少使用
编写高速缓存友好的代码
- 让最常见的情况运行的快。把注意力集中在核心函数里的循环上。
- 尽量减少每个循环内部的缓存不命中数量: 对局部变量的反复引用,步长为1的引用模式;行优先访问
置换策略
最佳替换算法的基本思想是:替换掉在未来最长时间段内不再使用的高速缓存块
LRU 最近最少被使用:保留访问记录,需要存储空间,减慢缓存速度
LRU是最近最少使用页面置换算法(Least Recently Used),也就是首先淘汰最长时间未被使用的页面!
LFU是最近最不常用页面置换算法(Least Frequently Used),也就是淘汰一定时期内被访问次数最少的页!
LRU关键是看页面最后一次被使用到发生调度的时间长短;
而LFU关键是看一定时间段内页面被使用的频率!
FIFO 先进先出
随机选择:
有效存取时间和命中几率
EAT(effective access time):每次访问所需要的平均时间
H为命中率,Access_c是高速缓存的访问时间,Access_M是主存储器的访问时间
异常控制流和进程管理
异常控制流
从开机到关机,处理器做的工作其实很简单,就是不断读取并执行指令,每次执行一条,整个指令执行的序列,称为处理器的控制流。到目前为止,我们已经学过了两种改变控制流的方式:
- 跳转和分支
- 调用和返回
这两个操作对应于程序的改变。但是这实际上仅仅局限于程序本身的控制,没有办法去应对更加复杂的情况。系统状态发生变化的时候,无论是跳转/分支还是调用/返回都是无能为力的,比如:
- 数据从磁盘或者网络适配器到达
- 指令除以了零
- 用户按下 ctrl+c
- 系统的计时器到时间
这时候就要轮到另一种更加复杂的机制登场了,称之为异常控制流(exceptional control flow)。首先需要注意的是,虽然名称里包含异常(实际上也用到了异常),但是跟代码中 try catch 所涉及的异常是不一样的。
异常控制流存在于系统的每个层级,最底层的机制称为异常(Exception),用以改变控制流以响应系统事件,通常是由硬件的操作系统共同实现的。更高层次的异常控制流包括进程切换(Process Context Switch)、信号(Signal)和非本地跳转(Nonlocal Jumps),也可以看做是一个从硬件过渡到操作系统,再从操作系统过渡到语言库的过程。进程切换是由硬件计时器和操作系统共同实现的,而信号则只是操作系统层面的概念了,到了非本地跳转就已经是在 C 运行时库(应用层)中实现的了。
异常 Exception
这里的异常指的是把控制交给系统内核来响应某些事件(例如处理器状态的变化),其中内核是操作系统常驻内存的一部分,而这类事件包括除以零、数学运算溢出、页错误、I/O 请求完成或用户按下了 ctrl+c 等等系统级别的事件。
系统会通过异常表(Exception Table)来确定跳转的位置,每种事件都有对应的唯一的异常编号,发生对应异常时就会调用对应的异常处理代码
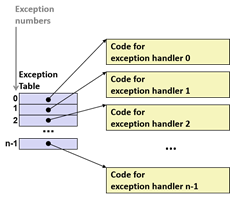
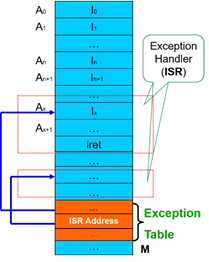
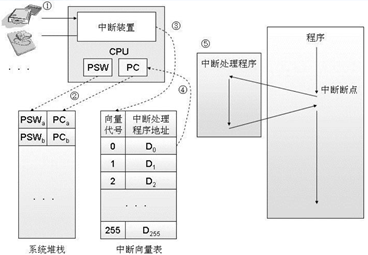
异常的类型
异步异常(中断)
异步异常(Asynchronous Exception)称之为中断(Interrupt),是由处理器外面发生的事情引起的。对于执行程序来说,这种“中断”的发生完全是异步的,因为不知道什么时候会发生。CPU对其的响应也完全是被动的,但是可以屏蔽掉[1]。这种情况下:
- 需要设置处理器的中断指针(interrupt pin)
- 处理完成后会返回之前控制流中的『下一条』指令
比较常见的中断有两种:计时器中断和 I/O 中断。计时器中断是由计时器芯片每隔几毫秒触发的,内核用计时器终端来从用户程序手上拿回控制权。I/O 中断类型比较多样,比方说键盘输入了 ctrl-c,网络中一个包接收完毕,都会触发这样的中断。
同步异常
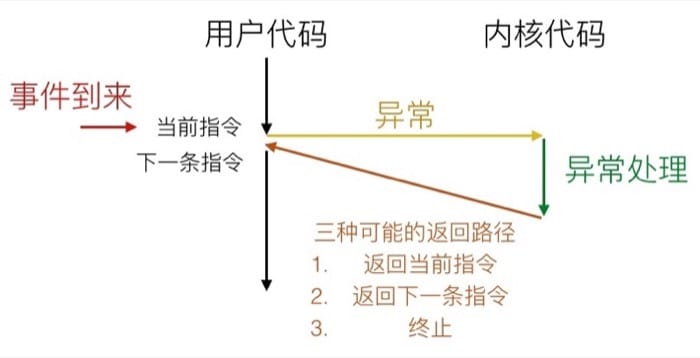
同步异常(Synchronous Exception)是因为执行某条指令所导致的事件,分为陷阱(Trap)、故障(Fault)和终止(Abort)三种情况。
| 类型 | 原因 | 行为 | 示例 |
| 陷阱 | 有意的异常 | 返回到下一条指令 | 系统调用,断点 |
| 故障 | 潜在可恢复的错误 | 返回到当前指令 | 页故障(page faults) |
| 终止 | 不可恢复的错误 | 终止当前程序 | 非法指令 |
这里需要注意三种不同类型的处理方式,比方说陷阱和中断一样,会返回执行『下一条』指令;而故障会重新执行之前触发事件的指令;终止则是直接退出当前的程序。
总结
- 中断是来自处理器外部的I/O设备的信号的结果。中断是I/O设备与处理器异步工作的重要机制。
- 陷阱是有意的异常,是执行一条指令的结果。陷阱最重要的用途是在用户程序和内核之间提供系统调用的接口。
- 故障由错误情况引起,它可能被故障处理程序所修正。如果修正了这个错误,就将控制返回到故障指令重新执行,否则返回到内核的终止例程。
- 终止是不可恢复的致命错误造成的结果。
系统调用示例
系统调用看起来像是函数调用,但其实是走异常控制流的,在 x86-64 系统中,每个系统调用都有一个唯一的 ID,如
| 编号 | 名称 | 描述 |
| 0 | read |
读取文件 |
| 1 | write |
写入文件 |
| 2 | open |
打开文件 |
| 3 | close |
关闭文件 |
| 4 | stat |
获取文件信息 |
| 57 | fork |
创建进程 |
| 59 | execve |
执行一个程序 |
| 60 | _exit |
关闭进程 |
| 62 | kill |
向进程发送信号 |
举个例子,假设用户调用了 open(filename, options),系统实际上会执行 __open 函数,也就是进行系统调用 syscall,如果返回值是负数,则是出错。
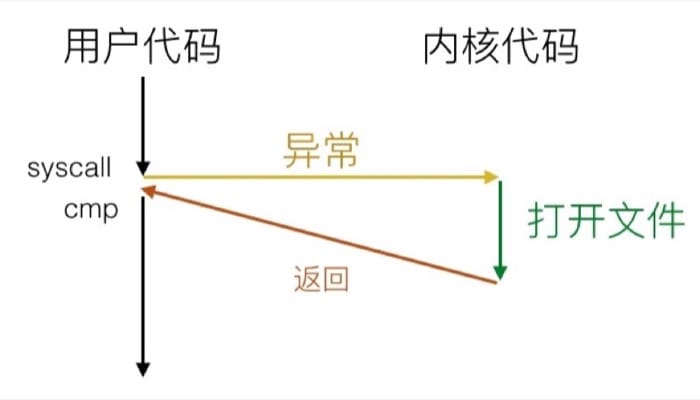
故障示例
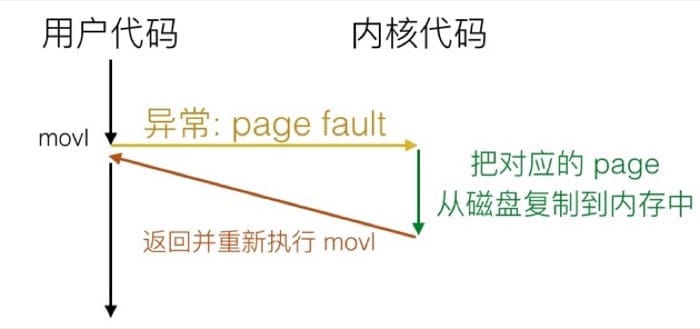
这里我们以 Page Fault 为例,来说明 Fault 的机制。Page Fault 发生的条件是:
- 用户写入内存位置
- 但该位置目前还不在内存中
那么系统会通过 Page Fault 把对应的部分载入到内存中,然后重新执行赋值语句:
进程
进程是程序(指令和数据)的真正运行实例。
进程给每个应用提供了两个非常关键的抽象:一是逻辑控制流,二是私有地址空间。逻辑控制流通过称为上下文切换(context switching)的内核机制让每个程序都感觉自己在独占处理器。私有地址空间则是通过称为虚拟内存(virtual memory)的机制让每个程序都感觉自己在独占内存。这样的抽象使得具体的进程不需要操心处理器和内存的相关适宜,也保证了在不同情况下运行同样的程序能得到相同的结果。
进程切换 Process Context Switch

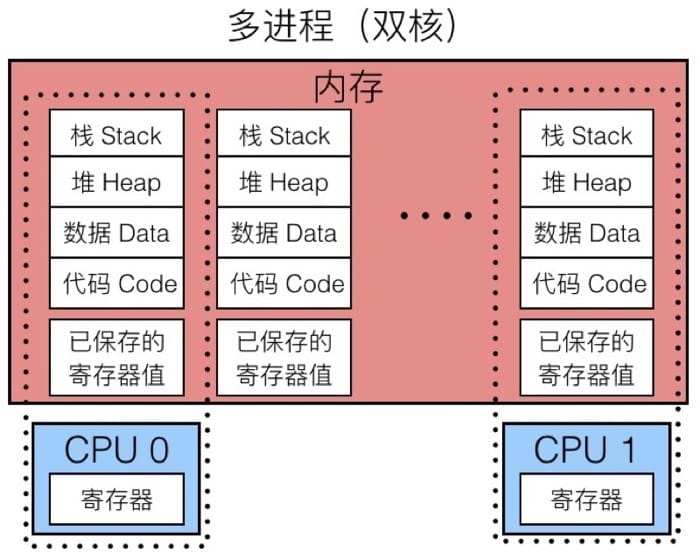
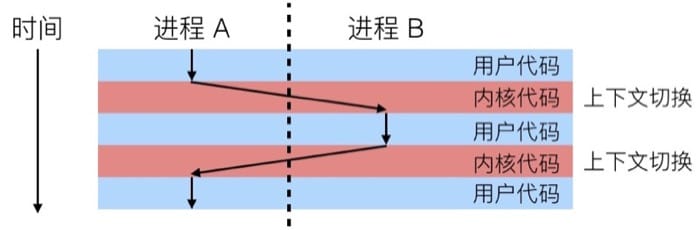
左边是单进程的模型,内存中保存着进程所需的各种信息,因为该进程独占 CPU,所以并不需要保存寄存器值。而在右边的单核多进程模型中,虚线部分可以认为是当前正在执行的进程,因为我们可能会切换到其他进程,所以内存中需要另一块区域来保存当前的寄存器值,以便下次执行的时候进行恢复(也就是所谓的上下文切换)。整个过程中,CPU 交替执行不同的进程,虚拟内存系统会负责管理地址空间,而没有执行的进程的寄存器值会被保存在内存中。切换到另一个进程的时候,会载入已保存的对应于将要执行的进程的寄存器值。
而现代处理器一般有多个核心,所以可以真正同时执行多个进程。这些进程会共享主存以及一部分缓存,具体的调度是由内核控制的,示意图如下:
多任务分为抢占式多任务和协作式多任务。切换进程时,内核会负责具体的调度,来决定运行哪一个进程:
线程
- 为什么要引入线程?
引入进程的目的是为了更好地使多道程序并发执行,以提高资源利用量和系统吞吐量,增加并发程度,(满足功能需求)。引入线程,则是为了减小程序在并发执行时所付出的时空开销,提高操作系统的并发性能。引入线程后,进程的内涵发生改变,只作为除CPU以外系统资源的分配单元,线程则作为处理器的分配单元。有了线程之后,线程切换时,有可能候会发生进程切换,也有可能不发生进程切换,平均下来,每次切换所需要的开销就小了,让更多的线程参与并发,也不会影响到响应时间的问题,提高系统并发性。
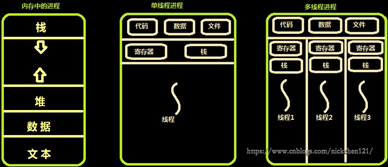
- 什么是多线程?
操作系统的一项能力来支持多个线程在一个进程内执行。
- 用户态和内核态?
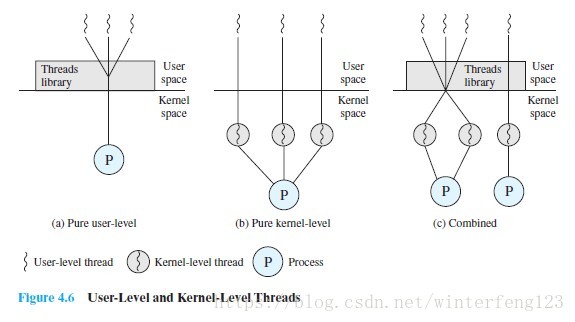
用户级线程相对内核级的优点:(1):所有线程管理数据结构都在一个进程的用户地址空间中,线程切换不需要内核态特权,进程不需要为了线程管理而切换到内核态,节省了两次状态转换的开销;(2) 调度可以是一个用程序相关的,为应用程序量身定做调度算法而不扰乱底层的调度程序;(3) 用户级线程可以在任何操作系统中运行,不需要对底层内核进行修改。线程库是一组供所有应用程序共享的应用程序级别的函数。
用户级线程相对于内核级的缺点:(1) 在典型的操作系统中,许多系统调用都会引起阻塞。当一个线程阻塞,整个进程阻塞(2) 一个多线程应用程序不能利用多处理技术。
Windows 进程API

#include <windows.h>
int WINAPI WinMain (HINSTANCE hInstance, HINSTANCE hPrevInstance, PSTR szCmdLine, int iCmdShow) {
MessageBox (NULL, TEXT ("Hello, world!"), TEXT ("HelloMsg"), 0) ;
return 0 ;
}
系统级编程(csapp)的更多相关文章
- ARMV8 datasheet学习笔记4:AArch64系统级体系结构之编程模型(1)-EL/ET/ST
1.前言 ARMV8系统级编程模型主要包括异常级别.运行状态.安全状态.同步异常.异步异常.DEBUG 本文主要对系统级编程模型做一个概要介绍 2. 异常级别 2.1 Exception level概 ...
- [CSAPP笔记][第十章 系统级I/O]
第十章 系统级I/O 输入/输出(I/O) : 是指主存和外部设备(如磁盘,终端,网络)之间拷贝数据过程. 高级别I/O函数 scanf和printf <<和>> 使用系统级I ...
- CSAPP:第十章 系统级I/O
CSAPP:第十章 系统级I/O 10.1 unix I/O10.2 文件10.3 读取文件元数据10.4 读取目录内容10.5 共享文件10.6 我们该使用哪些I/O函数? 10.1 unix I/ ...
- 转 系统级编程语言性能PK
http://www.solidot.org/story?sid=35754 看了此文,为什么我现在如此看好Rust C/C++已经统治系统编程很久,除了ObjectiveC之外语言都无法获得很高的关 ...
- 系统级I/O学习记录
重要知识点 输入/输出(I/O) I/O是主存和外部设备(如磁盘驱动器.终端和网络)之间拷贝数据的过程. 输入操作是从I/O设备拷贝数据到主存. 输出操作是从主存拷贝到I/O设备. Unix I/O ...
- 第十章 系统级I/O
第十章 系统级I/O 一.Unix I/O 1.一个unix文件就是一个m个字节的序列 2.unix外壳创建的每个进程开始时都有三个打开的文件:标准输入(0) .标准输出(1)和标准错误(-1). 二 ...
- 系统级I/O 第八周11.9~11.15
第十章 系统级I/O cp1 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include ...
- Java-Runoob-高级编程:Java 网络编程
ylbtech-Java-Runoob-高级编程:Java 网络编程 1.返回顶部 1. Java 网络编程 网络编程是指编写运行在多个设备(计算机)的程序,这些设备都通过网络连接起来. java.n ...
- 深入理解计算机系统10——系统级I/O
系统级I/O 输入/输出 是在主存和外部设备之间拷贝数据的过程. 外部设备可以是:磁盘驱动器.终端和网络. 输入和输出都是相对于主存而言的. 输入是从I/O设备拷贝数据到主存.输出时从主存拷贝数据到I ...
随机推荐
- python学习——list
list 序列是Python中最基本的数据结构.序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推.Python有6个序列的内置类型,但最常见的是列表和元组 ...
- [ZJOI2019]开关(生成函数+背包DP)
注:以下p[i]均表示概率 设F(x)为按i次开关后到达终止状态方案数的EGF,显然F(x)=π(ep[i]x/p+(-1)s[i]e-p[i]x/p)/2,然而方案包含一些多次到达合法方案的状态,需 ...
- uboot 编译
. 解包u-boot源码包(u-boot-2016.07) . 配置交叉编译器 根据内核编译里的步骤配置 . 编译uboot yum install ncurses* // ncurses是个终端的图 ...
- 华为鸿蒙系统pk安卓系统
Harmony OS Vs Android Comparison It isn’t based on Linux kernel The key difference between HarmonyOS ...
- PAT甲级——1041 Be Unique
1041 Be Unique Being unique is so important to people on Mars that even their lottery is designed in ...
- Xen入门系列二【使用 virt-install 安装虚拟机】
系统环境:Centos 6.5 + Xen4Centos安装方式 相关链接:Xen4Centos方式安装Xen请查看:http://www.cnblogs.com/hackboy/p/3662432. ...
- ckeditor+ckfinder添加水印。
1.修改ckfinder文件下面的config.php:添加一句include_once "plugins/watermark/plugin.php";//水印配置文件 2.修改p ...
- 学习C++之前要先学习C语言吗?
C++ 读作“C加加”,是“C Plus Plus”的简称.顾名思义,C++ 是在C语言的基础上增加新特性,玩出了新花样,所以叫“C Plus Plus”,就像 iPhone 7S 和 iPhone ...
- keras使用、函数功能
#1. keras.engine.input_layer.Input() def Input(shape=None, batch_shape=None, name=None, dtype=None ...
- C# for循环提升效率的写法
,,,,,}; ,iLen=arr.Length;i<iLen;i++) //必须是显示申明,不能var { ........... }