RDD(一)——概述
什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象(其实是计算抽象)。代码中是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
不可变:数据一旦写入,不可更改;联想到java 中的String类型,执行replace方法,它会返回一个新的字符串,但是原来的字符串不发生变化。RDD也是类似的;
可分区:每个RDD拥有多个分区(Partition),数据在多个分区同时计算。
RDD的属性
1) 一组分区(Partition),分区是数据集的基本组成单位;
2) 对每个分区数据进行处理的函数;
3) RDD与RDD之间的依赖关系;
4) 一个Partitioner,即RDD的分区函数,决定分区的形成;
5) 一个列表,存储 存取每个Partition的优先位置(preferred location),就是距离原则,即哪个partition应该被调用
RDD特点
1)分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。
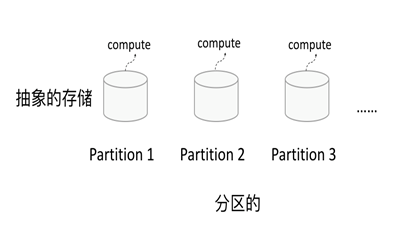
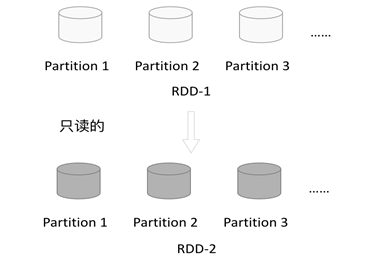
2)只读
如下图所示,RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
由一个RDD转换到另一个RDD,可以通过丰富的操作算子实现,不再像MapReduce那样只能写map和reduce了,如下图所示。
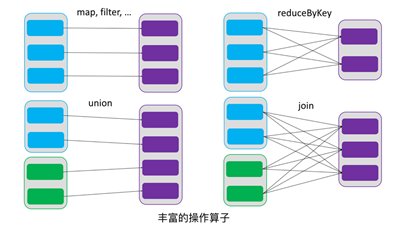
RDD的操作算子包括两类,一类叫做transformations,它是用来将RDD进行转化,构建RDD的血缘关系;另一类叫做actions,它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。
3) 依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系,也称之为依赖。如下图所示,依赖包括两种,一种是窄依赖,RDDs之间分区是一一对应的,另一种是宽依赖,下游RDD的每个分区与上游RDD(也称之为父RDD)的每个分区都有关,是多对多的关系。

4)缓存
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。如下图所示,RDD-1经过一系列的转换后得到RDD-n并保存到hdfs,RDD-1在这一过程中会有个中间结果,如果将其缓存到内存,那么在随后的RDD-1转换到RDD-m这一过程中,就不会计算其之前的RDD-0了。
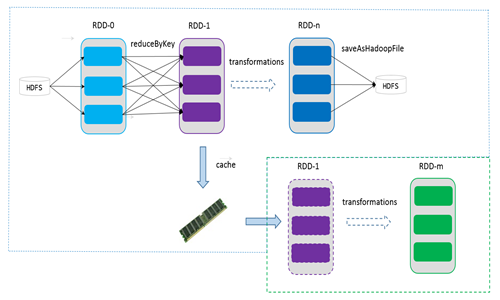
5)checkpoint
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处拿到数据。
编程模型
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
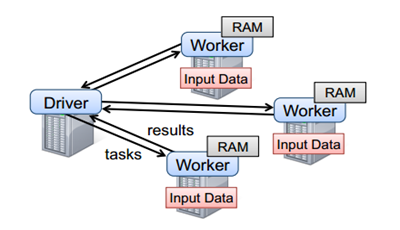
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。
RDD(一)——概述的更多相关文章
- Spark里边:到底是什么RDD
RDD它是Spark基,它是最根本的数据抽象.http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf 它开着RDD文件.假设英语阅读太 ...
- Spark技术内幕:究竟什么是RDD
RDD是Spark最基本,也是最根本的数据抽象.http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf 是关于RDD的论文.如果觉得英 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark(三)RDD与广播变量、累加器
一.RDD的概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可 ...
- Spark之RDD
Spark学习之路Spark之RDD 目录 一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数 ...
- Spark RDD :Spark API--Spark RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark学习之路 (三)Spark之RDD[转]
RDD的概述 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- 【Spark】RDD的依赖关系和缓存相关知识点
文章目录 RDD的依赖关系 宽依赖 窄依赖 血统 RDD缓存 概述 缓存方式 RDD的依赖关系 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency) 和宽依赖 ...
随机推荐
- Sequence Models Week 1 Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
- HDU 5311:Hidden String
Hidden String Accepts: 437 Submissions: 2174 Time Limit: 2000/1000 MS (Java/Others) Memory Limit ...
- UVA 10534 LCS变种题
求一个序列中 的2*n-1个数字 ,前n+1个数字为严格升序 后n+1个为严格降序,求最长的长度 一开始还没想清楚怎么解,其实就是一个LCS问题,从头到尾以及反序求一下LCS 由于 d[i]为包含了自 ...
- [转]java 的HashMap底层数据结构
java 的HashMap底层数据结构 HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在.在HashMap中,key-v ...
- SQL基础教程(第2版)第2章 查询基础:2-1 SELECT语句基础
● 通过指定DISTINCT可以删除重复的行.● 为列设定显示用的别名. ■列的查询 通过 SELECT 语句查询并选取出必要数据的过程称为查询(query). 该 SELECT 语句包含了 SELE ...
- ubuntu16.04 + Kdevelop + ROS开发和创建catkin_ws工作空间
https://blog.csdn.net/p942005405/article/details/75715288 https://blog.csdn.net/LOVE1055259415/artic ...
- Thread--生产者消费者假死分析
package p_c_allWait; public class ValueObject { public static String value = ""; } package ...
- ubuntu 插网线无法上网解决方案
前言 不知道最近是什么情况,ubuntu链接网线总是上不去网,但是wifi还能用,一直也就没有捣鼓,不过今天连wifi都不能用了,只能开始修理了. 修复方案 使用ifconfig命令查看以太网的名称 ...
- Feign整合测试
1.测试使用 (1)服务调用方引入依赖 <dependency> <groupId>org.springframework.cloud</groupId> < ...
- 91.一次性处理多条数据的方法:bulk_create,update,delete
(1)bulk_create: 可以一次性的创建多个对象 示例代码如下: from django.http import HttpResponse from .models import Pulish ...