【Spark】RDD的依赖关系和缓存相关知识点
RDD的依赖关系
RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency) 和宽依赖(wide dependency)。
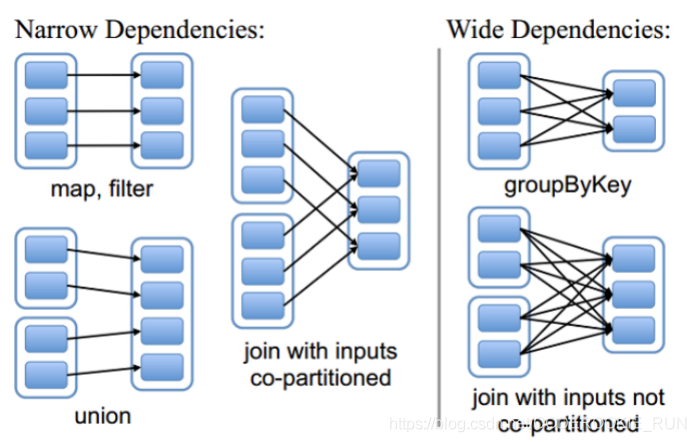
宽依赖
宽依赖指的是子RDD中的数据来源于父RDD中的多个分区,其实就是产生了shuffle
窄依赖
窄依赖指的是子RDD中的数据来源于父RDD当中的一个分区,也即没有产生shuffle
血统
Lineage —— 根据rdd之间的依赖关系,将依赖关系给记录下来叫做血统。
比如:
rdd1 ==> rdd2 ==> rdd3 ==> rdd4
记录下来每一个rdd的父rdd是谁,也记录下来每一个rdd的子rdd是谁,可以帮助我们做容灾
RDD缓存
概述
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或者缓存数据集。当持久化某个RDD后,每一个节点都将把计算分区结果保存在内存中,对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
缓存方式
通过查看StorageLevel的源码可以拿到
object StorageLevel {
//不缓存
val NONE = new StorageLevel(false, false, false, false)
//只在硬盘缓存
val DISK_ONLY = new StorageLevel(true, false, false, false)
//在硬盘缓存两份
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
//只在内存缓存
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
//在内存缓存两份
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
//在内存序列化缓存
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
//在内存序列化缓存两份
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
//同时在内存和硬盘缓存
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
//同时在内存和硬盘缓存两份(推荐)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
//同时在内存和硬盘序列化缓存
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
//同时在内存和硬盘序列化缓存两份
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
//对外内存
val OFF_HEAP = new StorageLevel(false, false, true, false)
......
}
两种方法:
1.cache(),其实底层就是调用了persist,将数据仅仅的放到内存里面去,放一份
2.persist()
(1)无参,也是将只在内存中缓存一份数据
(2)带StorageLevel参数,一般选择MEMORY_AND_DISK_2
【Spark】RDD的依赖关系和缓存相关知识点的更多相关文章
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- sparkRDD:第4节 RDD的依赖关系;第5节 RDD的缓存机制;第6节 DAG的生成
4. RDD的依赖关系 6.1 RDD的依赖 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- RDD的依赖关系
RDD的依赖关系 Rdd之间的依赖关系通过rdd中的getDependencies来进行表示, 在提交job后,会通过在DAGShuduler.submitStage-->getMissingP ...
- 021 RDD的依赖关系,以及造成的stage的划分
一:RDD的依赖关系 1.在代码中观察 val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val resultRD ...
- Spark RDD 窄依赖研究
1.. 简介 spark从RDD依赖上来说分为窄依赖和宽依赖. 其中可以这样区分是哪种依赖:当父RDD的一个partition被子RDD的多个partitions引用到的时候则说明是宽依赖,否则为窄依 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark RDD的依赖解读
在Spark中, RDD是有依赖关系的,这种依赖关系有两种类型 窄依赖(Narrow Dependency) 宽依赖(Wide Dependency) 以下图说明RDD的窄依赖和宽依赖 窄依赖 窄依赖 ...
- spark rdd 宽窄依赖理解
== 转载 == http://blog.csdn.net/houmou/article/details/52531205 Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过 ...
随机推荐
- 教你如何安装和使用Python pip
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:Starshot PS:如有需要Python学习资料的小伙伴可以加点击 ...
- Daily Scrum 12/25/2015
Process: Zhaoyang: Implement the Alex 50M model in the Caffe framework. Yandong: The Azure Back end ...
- Yii2.0 rules常用验证规则
设置一个修改方法,但是save(),没有成功,数据修改失败,查了好久,一般情况就是不符合rules规则,而我没有设置rules规则,重新设置了一个不能为空,然后就修改成功,rules里面什么也不写,也 ...
- 【Vue】状态管理
页面应用需要Vuex管理全局/模块的状态,大型单页面组件如果靠事件(events)/属性(props)通讯传值会把各个组件耦合在一起.因 此需要Vuex统一管理,当然如是小型单页面应用,引用Vuex反 ...
- HTTPie:替代 Curl 和 Wget 的现代 HTTP 命令行客户端
HTTPie 工具是现代的 HTTP 命令行客户端,它能通过命令行界面与 Web 服务进行交互. -- Magesh Maruthamuthu 大多数时间我们会使用 curl 命令或是 wget 命令 ...
- pytorch 中模型的保存与加载,增量训练
让模型接着上次保存好的模型训练,模型加载 #实例化模型.优化器.损失函数 model = MnistModel().to(config.device) optimizer = optim.Adam( ...
- 【认证与授权】2、基于session的认证方式
这一篇将通过一个简单的web项目实现基于Session的认证授权方式,也是以往传统项目的做法. 先来复习一下流程 用户认证通过以后,在服务端生成用户相关的数据保存在当前会话(Session)中,发给客 ...
- 在Thinkphp中微信公众号JsApi支付
由于网站使用的微信Native扫码支付,现在公众号需要接入功能,怎么办呢,看这官方文档,参考着demo进行写吧.直接进入正题 进入公众号(服务号)设置--->功能设置--->网页授权域名配 ...
- 使用JAVA API编程实现简易Habse操作
使用JAVA API编程实现下面内容: 1.创建<王者荣耀>游戏玩家信息表gamer,包含列族personalInfo(个人信息).recordInfo(战绩信息).assetsInfo( ...
- HDFS一些基本操作方法
启动hadoop cd /usr/local/hadoop ./sbin/start-dfs.sh 在浏览器中打开localhost:50070 找到 进入 操作 1)新建文件夹 在根目录 ...