RDD(一)——概述
什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象(其实是计算抽象)。代码中是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
不可变:数据一旦写入,不可更改;联想到java 中的String类型,执行replace方法,它会返回一个新的字符串,但是原来的字符串不发生变化。RDD也是类似的;
可分区:每个RDD拥有多个分区(Partition),数据在多个分区同时计算。
RDD的属性
1) 一组分区(Partition),分区是数据集的基本组成单位;
2) 对每个分区数据进行处理的函数;
3) RDD与RDD之间的依赖关系;
4) 一个Partitioner,即RDD的分区函数,决定分区的形成;
5) 一个列表,存储 存取每个Partition的优先位置(preferred location),就是距离原则,即哪个partition应该被调用
RDD特点
1)分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。
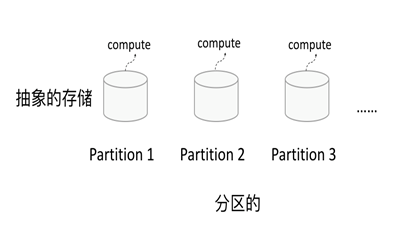
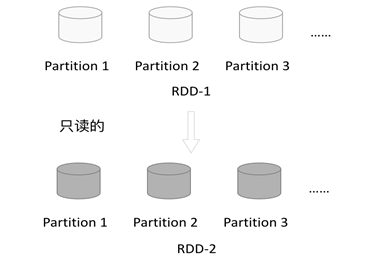
2)只读
如下图所示,RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
由一个RDD转换到另一个RDD,可以通过丰富的操作算子实现,不再像MapReduce那样只能写map和reduce了,如下图所示。
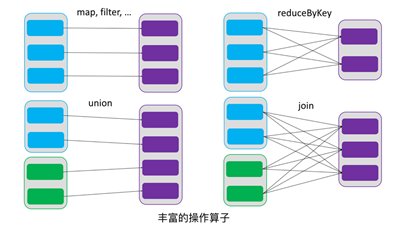
RDD的操作算子包括两类,一类叫做transformations,它是用来将RDD进行转化,构建RDD的血缘关系;另一类叫做actions,它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。
3) 依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系,也称之为依赖。如下图所示,依赖包括两种,一种是窄依赖,RDDs之间分区是一一对应的,另一种是宽依赖,下游RDD的每个分区与上游RDD(也称之为父RDD)的每个分区都有关,是多对多的关系。

4)缓存
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。如下图所示,RDD-1经过一系列的转换后得到RDD-n并保存到hdfs,RDD-1在这一过程中会有个中间结果,如果将其缓存到内存,那么在随后的RDD-1转换到RDD-m这一过程中,就不会计算其之前的RDD-0了。
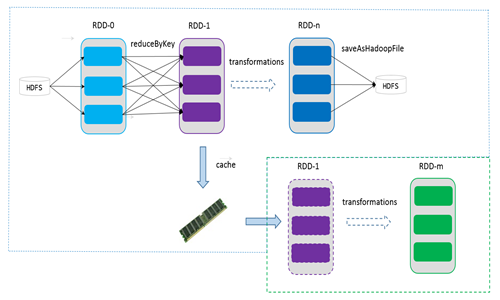
5)checkpoint
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处拿到数据。
编程模型
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
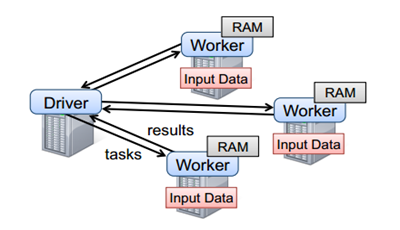
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。
RDD(一)——概述的更多相关文章
- Spark里边:到底是什么RDD
RDD它是Spark基,它是最根本的数据抽象.http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf 它开着RDD文件.假设英语阅读太 ...
- Spark技术内幕:究竟什么是RDD
RDD是Spark最基本,也是最根本的数据抽象.http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf 是关于RDD的论文.如果觉得英 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark(三)RDD与广播变量、累加器
一.RDD的概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可 ...
- Spark之RDD
Spark学习之路Spark之RDD 目录 一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数 ...
- Spark RDD :Spark API--Spark RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark学习之路 (三)Spark之RDD[转]
RDD的概述 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- 【Spark】RDD的依赖关系和缓存相关知识点
文章目录 RDD的依赖关系 宽依赖 窄依赖 血统 RDD缓存 概述 缓存方式 RDD的依赖关系 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency) 和宽依赖 ...
随机推荐
- python:批量修改文件名批量修改图片尺寸
批量修改文件名 参考博客:https://www.cnblogs.com/zf-blog/p/7880126.html 功能:批量修改文件名 1 2 3 4 5 6 7 8 9 10 11 12 1 ...
- Win10下 Java环境变量配置
安装java的JDK 下载地址 此电脑->属性->高级设置 "系统变量"新建 变量名:Java_Home 变量值:D:\Program Files\Java ...
- Adobe PhotoShop CS6中文破解版下载
在网上找了好多个PhotoShop破解版,但安装过程中都出现一些问题,用不了.现在找到一个比较小的PhotoShop CS6安装包,大小200M左右,下载解压,点击安装就可以使用了,安装过程十分简单. ...
- MySQL硬核干货:从磁盘读取数据页到缓冲池时,免费链表有什么用?
1.数据库启动的时候,是如何初始化Buffer Pool的? 现在我们已经搞明白一件事儿了,那就是数据库的Buffer Pool到底长成个什么样,大家想必都是理解了 其实说白了,里面就是会包含很多个缓 ...
- CSS(3)之 less 和rem
less 预编译脚本语言. LESS 语法 less语法2 LESS中文 rem rem的适配原理 rem 是相对于页面根源素html的字体大小的一个尺寸单位 页面内容可以使用rem为单位,那么htm ...
- idea 使用技巧 - [copy reference]
选择项目中某个函数名, 右键可以看到 copy reference, 点击完成复制symbol, 分享给别人. shift + shift 打开打开一个对话框, 把分享的symbol粘贴上去, 可以跳 ...
- 72)MFC测试动态共享库
动态共享库: 首先我建立一个新的动态库: 然后不选择空项目了,因为我们普通的cpp文件 入口是main win32入口是winmain 那么这个动态库的入口在哪里 我们就是为了看一看: 出来这样 ...
- 吴裕雄--天生自然MySQL学习笔记:MySQL 元数据
你可能想知道MySQL以下三种信息: 查询结果信息: SELECT, UPDATE 或 DELETE语句影响的记录数. 数据库和数据表的信息: 包含了数据库及数据表的结构信息. MySQL服务器信息: ...
- 批量导出数据库表(oracle)
批量导出数据库表(oracle) 要求:导出sql文件,包含表结构和数据. 方案一 1:用cmd进入命令行输入:tnsping cmstar就是测试172.18.13.200是否连接成功2:导入与导出 ...
- qt使用了qstackedwidget里面放置了widget后对该子widget设置的样式无效
关键字:子窗口样式无效 QStackedwidget 问题: 我有一个对话框,里面放了一个qstackedwidget,qstackedwidget放了N个子窗口,使用addwidget添加上去了: ...