5、flink常见函数使用及自定义转换函数
一、flink编程方法
- 获取执行环境(execution environment)
- 加载/创建初始数据集
- 对数据集进行各种转换操作(生成新的数据集)
- 指定将计算的结果放到何处去
- 触发APP执行
flink的计算方式和spark一样都是惰性的
- Flink APP都是延迟执行的
- 只有当execute()被显示调用时才会真正执行
- 本地执行还是在集群上执行取决于执行环境的类型
- 好处:用户可以根据业务构建复杂的应用,Flink可以整体进优化并生成执行计划

二、DataStream
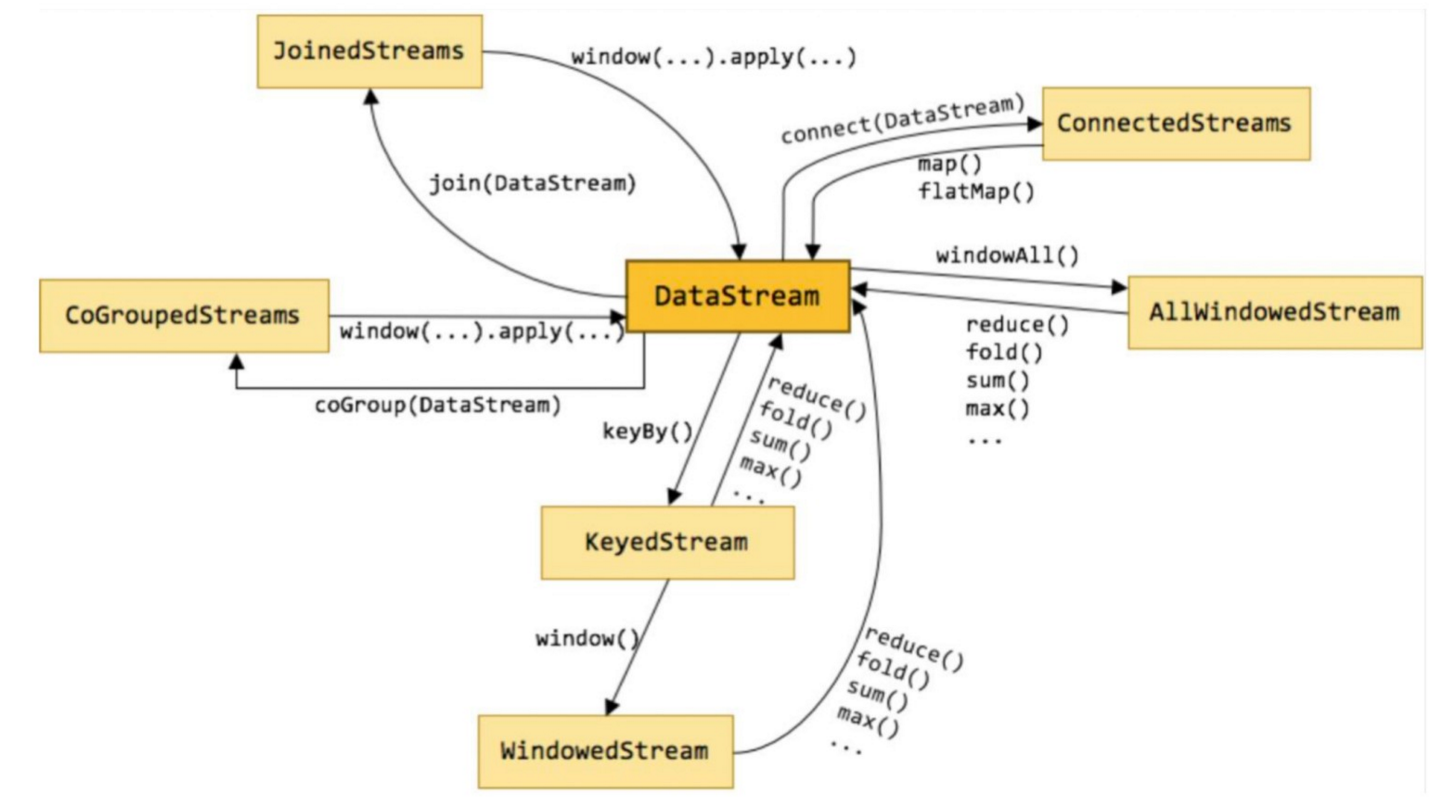
- DataStream 是 Flink 流处理 API 中最核心的数据结构。它代表了一个运行在多个分区上的并行流。一 个 DataStream 可以从 StreamExecutionEnvironment 通过env.addSource(SourceFunction) 获得。 DataStream 上的转换操作都是逐条的,比如 map(),flatMap(),filter()
- 下图展示了Flink 中目前支持的主要几种流的类型,以及它们之间的转换关系。
2.1、自定义转换函数
1、函数
scala函数
data.flatMap(f => f.split(" "))
java的lambda表达式
data.flatMap(f -> f.split(" "));
2、实现接口
data.flatMap(new FlatMapFunction[String,String] {
override def flatMap(value: String, out: Collector[String]) = {
val strings: Array[String] = value.split(" ")
for(s <- strings){
out.collect(s)
}
}
})
3、RichFunctions
RichFunction中有非常有用的四个方法:open,close,getRuntimeContext和setRuntimecontext 这些功能在参数化函数、创建和确定本地状态、获取广播变量、获取运行时信息(例如累加器和计数器)和迭代信息时非常有帮助。
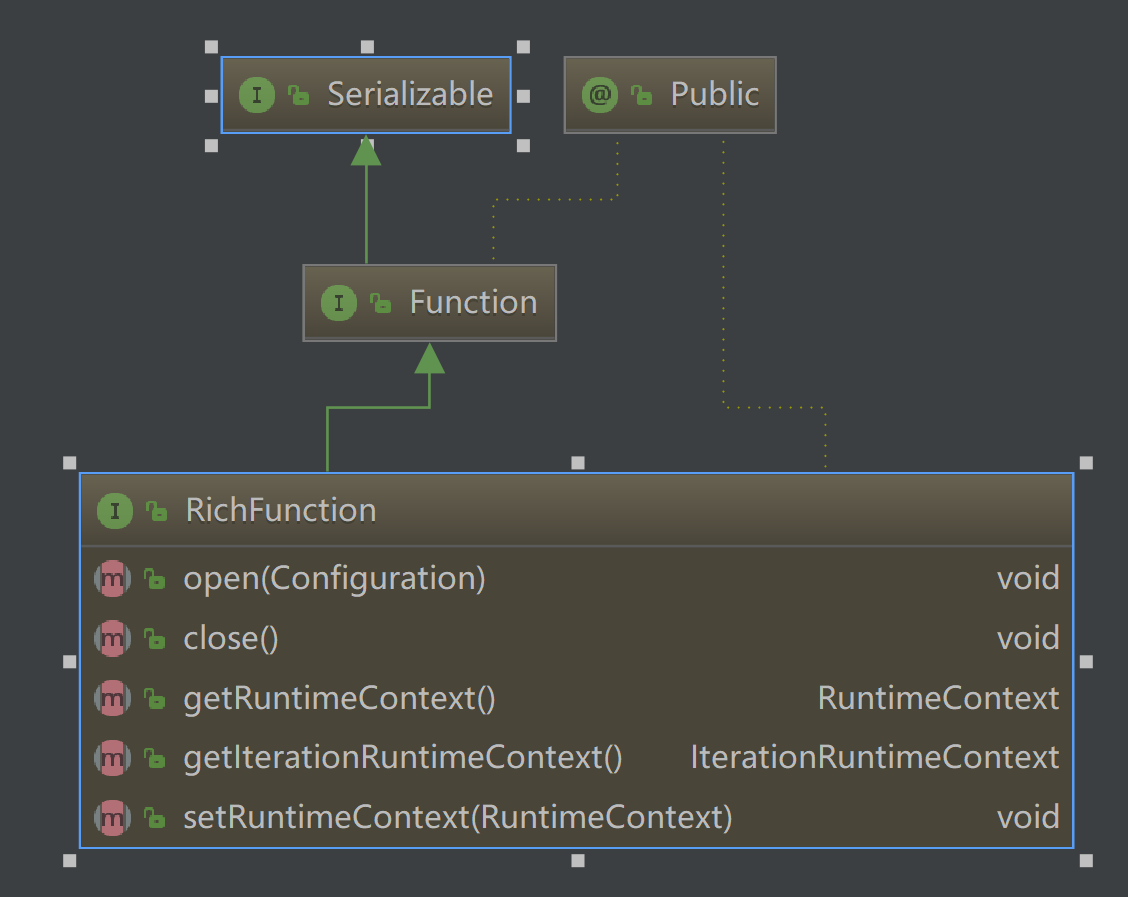
以RichFlatMapFunction为例:
import java.util.Properties
import org.apache.flink.api.common.functions.{IterationRuntimeContext, RichFlatMapFunction, RuntimeContext}
import org.apache.flink.configuration.Configuration
import org.apache.flink.util.Collector
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
/**
* @author xiandongxie
*/
class KafkaRichFlatMapFunction(topic: String,properites: Properties) extends RichFlatMapFunction[String, Collector[Int]]{
var producer: KafkaProducer[String, String] = null
override def open(parameters: Configuration): Unit = {
// 创建kafka生产者
producer = new KafkaProducer[String, String](properites)
}
override def close(): Unit = {
// 关闭kafka生产者
producer.close()
}
override def getRuntimeContext: RuntimeContext = super.getRuntimeContext
override def setRuntimeContext(t: RuntimeContext): Unit = super.setRuntimeContext(t)
override def getIterationRuntimeContext: IterationRuntimeContext = super.getIterationRuntimeContext
override def flatMap(value: String, out: Collector[Collector[Int]]): Unit = {
//使用RuntimeContext得到子线程ID,比如可以用于多线程写文件
println(getRuntimeContext.getIndexOfThisSubtask)
//发送数据到kafka
producer.send(new ProducerRecord[String, String](topic, value))
}
}
2.2、operators
1、map flatMap 与 DataStreamUtils.collect的使用
- map flatMap
- 含义:数据映射(1进1出和1进n出)
- 转换关系:DataStream → DataStream
- DataStreamUtils.collect
- 含义:数据拉回Client
- 转换关系:DataStream → util.Iterator
示例代码:
import java.util import org.apache.flink.api.scala._
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.datastream.DataStreamUtils
import org.apache.flink.streaming.api.functions.source.SocketTextStreamFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} object SocketMap {
def main(args: Array[String]): Unit = {
val logPath: String = "/tmp/logs/flink_log"
var conf: Configuration = new Configuration()
// 开启spark-webui
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
//配置webui的日志文件
conf.setString("web.log.path", logPath)
// 配置 taskManager 的日志文件,否则打印日志到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY,logPath)
// 配置有多少个solor
conf.setString("taskmanager.numberOfTaskSlots","8")
// 获取本地运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
// 定义数据源
// val dataSource: DataStream[String] = env.socketTextStream("*********",666)
val unit: DataStream[String] = env.addSource(new SocketTextStreamFunction("******",6666,"\n",2)) val mapData: DataStream[(String, Int)] = unit.flatMap(f => f.split(" ")).map((_,1))
//把数据拉回到client端进行操作,比如发起一次数据连接把数据统一插入
//使用了DataStreamUtils.collect就可以省略env.execute
import scala.collection.convert.wrapAll._
val value: util.Iterator[(String, Int)] = DataStreamUtils.collect(mapData.javaStream)
for(v <- value){
println(v)
}
// env.execute("SocketMap")
}
}
2、filter 与 循环迭代流
- 含义:数据筛选(满足条件event的被筛选出来进行后续处理),根据FliterFunction返回的布尔值来判断是否 保留元素,true为保留,false则丢弃
- 转换关系:DataStream → DataStream
示例代码:
import org.apache.flink.api.scala._
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} //输入一组数据,我们对他们分别进行减1运算,直到等于0为止
object IterativeFilter {
def main(args: Array[String]): Unit = {
val logPath: String = "/tmp/logs/flink_log"
var conf: Configuration = new Configuration()
// 开启spark-webui
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
//配置webui的日志文件
conf.setString("web.log.path", logPath)
// 配置 taskManager 的日志文件,否则打印日志到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY,logPath)
// 配置有多少个solor
conf.setString("taskmanager.numberOfTaskSlots","8")
// 获取本地运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
//设置全局并行度为1
env.setParallelism(1)
// 生成包含一个0到10的DStream
val input: DataStream[Long] = env.generateSequence(0, 10)
//流中的元素每个减1,并过滤出大于0的,然后生成新的流
// input.filter(f => {
// f > 5
// }).print()
val value: DataStream[Long] = input.iterate(
d => (d.map(f => {
println("map\t"+ f)
f - 1
}),
d.filter(f => {
println("filter \t" + f)
f > 0
})))
value.print()
env.execute("IterativeFilter")
}
}
3、keyBy
- 含义: 根据指定的key进行分组(逻辑上把DataStream分成若干不相交的分区,key一样的event会 被划分到相同的partition,内部采用hash分区来实现)
- 转换关系: DataStream → KeyedStream
- 限制:
- 可能会出现数据倾斜,可根据实际情况结合物理分区来解决
KeyedStream
- KeyedStream用来表示根据指定的key进行分组的数据流。
- 一个KeyedStream可以通过调用DataStream.keyBy()来获得。
- 在KeyedStream上进行任何transformation都将转变回DataStream。
- 在实现中,KeyedStream会把key的信息传入到算子的函数中。
- 每个event只能访问所属key的状态,其上的聚合函数可以方便地操作和保存对应key的状态
import org.apache.flink.api.java.functions.KeySelector
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.api.scala._
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment} object KeyBy {
def main(args: Array[String]): Unit = {
//生成配置对象
val config = new Configuration()
//开启spark-webui
config.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
//配置webui的日志文件,否则打印日志到控制台
config.setString("web.log.path", "/tmp/flink_log")
//配置taskManager的日志文件,否则打印日志到控制台
config.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, "/tmp/flink_log")
//配置tm有多少个slot
config.setString("taskmanager.numberOfTaskSlots", "8")
// 获取local运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(config)
val tuple = List(
("xxd", "class12", "小李", 55),
("xxd", "class12", "小王", 50),
("xxd", "class11", "小张", 50),
("xxd", "class11", "小强", 45))
// 定义数据源,使用集合生成
val input = env.fromCollection(tuple) //对于元组类型来说数据的选择可以使用数字(从0开始),keyBy(0,1)这种写法代表组合key
val keyBey: KeyedStream[(String, String, String, Int), Tuple] = input.keyBy(1)
// val unit: KeyedStream[(String, String, String, Int), String] = input.keyBy(_._1) //对于key选择来说还可以使用keySelector
val keyBy: KeyedStream[(String, String, String, Int), String] = input.keyBy(new KeySelector[(String, String, String, Int), String] {
override def getKey(value: (String, String, String, Int)): String = {
value._2
}
}) //对于scala的元组可以使用"_1"、对于java的元组可以使用"f0",其实也是类中属性的名字
val max: DataStream[(String, String, String, Int)] = keyBy.maxBy("_4")
// max.print() val myList = List(
new MyEventKey("xxd", "class12", "小李", 55),
new MyEventKey("xxd", "class12", "小王", 50),
new MyEventKey("xxd", "class11", "小张", 50),
new MyEventKey("xxd", "class11", "小强", 45))
// 定义数据源,使用集合生成
val myInput = env.fromCollection(myList)
//对于自定义类型来说也可以用类中的字段名称,记住这个自定义类型必须得是样例类
val myKeyBy: KeyedStream[MyEventKey, Tuple] = myInput.keyBy("b")
myKeyBy.maxBy("d").print()
// myKeyBy.map(f => new MyEventValue(f.a,f.b,f.c,f.d)).print()
env.execute("keyby") }
} //样例类,可以用于key,因为其默认实现了hashCode方法,可用于对象比较,当然也可用于value
case class MyEventKey(a:String,b:String,c:String,d:Int){
override def toString: String = a + "\t" + b + "\t" + c + "\t" + d
}
//普通类可以用于非key,只能用于value
class MyEventValue(a:String,b:String,c:String,d:Int){
override def toString: String = a + "\t" + b + "\t" + c + "\t" + d
}
4、reduce 与 fold
- 分组之后当然要对分组之后的数据也就是KeyedStream进行各种聚合操作啦
- KeyedStream → DataStream
- 对于KeyedStream的聚合操作都是滚动的(rolling,在前面的状态基础上继续聚合),千万不要理解为批处理 时的聚合操作(DataSet,其实也是滚动聚合,只不过他只把最后的结果给了我们)
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment}
object ReduceFoldAggregation {
def main(args: Array[String]): Unit = {
val logPath: String = "/tmp/logs/flink_log"
// 生成对象
var conf: Configuration = new Configuration()
// 开启flink web UI
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
// 配置web UI的日志文件,否则打印日志到控制台
conf.setString("web.log.path", logPath)
// 配置taskManager的日志文件,否则打印到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, logPath)
// 获取local运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
// 定义socket 源
//scala开发需要加一行隐式转换,否则在调用operator的时候会报错
import org.apache.flink.api.scala._
val tuple = List(
("xxd", "class12", "小王", 50),
("xxd", "class12", "小李", 55),
("xxd", "class11", "小张", 50),
("xxd", "class11", "小强", 45))
val text = env.fromCollection(tuple)
val map: DataStream[(String, Int)] = text.map(f => (f._2, 1))
val keyBy: KeyedStream[(String, Int), String] = map.keyBy(_._1)
//相同的key的数据聚合在一起使用reduce求合,使用的时候注意与spark不同的地方是key也参与运算
val reduce: DataStream[(String, Int)] = keyBy.reduce((a,b) => (a._1,a._2 + b._2))
reduce.print()
//使用fold完成和reduce一样的功能,不同的是这里的返回值类型由fold的第一个参数决定
// val fold: DataStream[(String, Int)] = keyBy.fold(("",0))((a,b) => (b._1,a._2 + b._2))
// fold.print()
env.execute("ReduceFoldAggregation")
}
}
5、connect 与 union (合并流)
- connect之后生成ConnectedStreams,会对两个流的数据应用不同的处理方法,并且双流之间可以共享状态 (比如计数)。
- union 合并多个流,新的流包含所有流的数据。
- union是DataStream → DataStream
- connect只能连接两个流,而union可以连接多于两个流
- connect连接的两个流类型可以不一致,而union连接的流的类型必须一致
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.scala.{ConnectedStreams, DataStream, StreamExecutionEnvironment}
object ConnectUnion {
def main(args: Array[String]): Unit = {
val logPath: String = "/tmp/logs/flink_log"
// 生成对象
var conf: Configuration = new Configuration()
// 开启flink web UI
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
// 配置web UI的日志文件,否则打印日志到控制台
conf.setString("web.log.path", logPath)
// 配置taskManager的日志文件,否则打印到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, logPath)
// 获取local运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
//scala开发需要加一行隐式转换,否则在调用operator的时候会报错
import org.apache.flink.api.scala._
val input1: DataStream[Long] = env.generateSequence(0, 10)
val input2: DataStream[String] = env.fromCollection(List("xxd it dashuju"))
//连接两个流
val connectInput: ConnectedStreams[Long, String] = input1.connect(input2)
//使用connect连接两个流,类型可以不一致
val connect: DataStream[String] = connectInput.map[String](
//处理第一个流的数据,需要返回String类型
(a: Long) => (a + 100).toString,
//处理第二个流的数据,需要返回String类型
(b: String) => b + "_input2")
connect.print()
val input3: DataStream[Long] = env.generateSequence(11, 20)
val input4: DataStream[Long] = env.generateSequence(21, 30)
//使用union连接多个流,要求数据类型必须一致,且返回结果是DataStream
val unionData: DataStream[Long] = input1.union(input3).union(input4)
unionData.print()
env.execute()
}
}
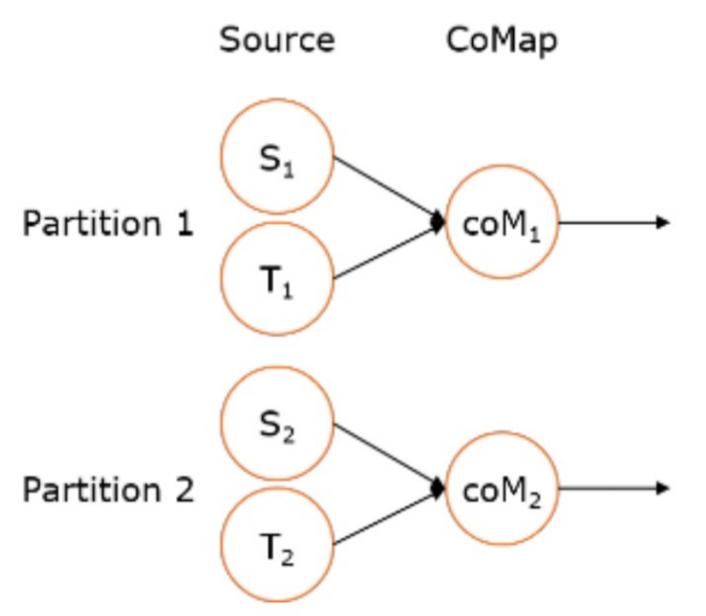
6、CoMap, CoFlatMap
- 跟map and flatMap类似,只不过作用在ConnectedStreams上
- ConnectedStreams → DataStream
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.scala.{ConnectedStreams, DataStream, StreamExecutionEnvironment}
import org.apache.flink.util.Collector
object ConnectCoFlatMap {
def main(args: Array[String]): Unit = {
val logPath: String = "/tmp/logs/flink_log"
// 生成对象
var conf: Configuration = new Configuration()
// 开启flink web UI
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
// 配置web UI的日志文件,否则打印日志到控制台
conf.setString("web.log.path", logPath)
// 配置taskManager的日志文件,否则打印到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, logPath)
// 获取local运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
//scala开发需要加一行隐式转换,否则在调用operator的时候会报错
import org.apache.flink.api.scala._
val input1: DataStream[Long] = env.generateSequence(0,10)
val input2: DataStream[String] = env.fromCollection(List("xxd it dashuju"))
//连接两个流
val connectInput: ConnectedStreams[Long, String] = input1.connect(input2)
//flatMap之后的泛型确定了两个流合并之后的返回类型
val value: DataStream[String] = connectInput.flatMap[String](
//处理第一个流的数据,需要返回String类型
(data:Long, out:Collector[String]) => {
out.collect(data.toString)
},
//处理第二个流的数据,需要返回String类型
(data:String, out:Collector[String]) => {
val strings: Array[String] = data.split(" ")
for (s <- strings) {
out.collect(s)
}
}
)
value.print()
env.execute()
}
}
7、split 与 select(拆分流)& SideOutPut
- split
- DataStream → SplitStream
- 按照指定标准将指定的DataStream拆分成多个流用SplitStream来表示
- select
- SplitStream → DataStream
- 跟split搭配使用,从SplitStream中选择一个或多个流
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.scala.{DataStream, SplitStream, StreamExecutionEnvironment}
import scala.collection.mutable.ListBuffer
object SplitAndSelect {
def main(args: Array[String]): Unit = {
val logPath: String = "/tmp/logs/flink_log"
// 生成对象
var conf: Configuration = new Configuration()
// 开启flink web UI
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
// 配置web UI的日志文件,否则打印日志到控制台
conf.setString("web.log.path", logPath)
// 配置taskManager的日志文件,否则打印到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, logPath)
// 获取local运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
val input: DataStream[Long] = env.generateSequence(0, 10)
val splitStream: SplitStream[Long] = input.split(f => {
val out = new ListBuffer[String]
//返回数据的拆分标记
if (f % 2 == 0) {
out += "xxd"
} else {
out += "it"
}
out
})
//根据拆分标记选择数据
// splitStream.select("xxd").print()
// splitStream.select("it").print()
splitStream.select("xxd", "it").print()
env.execute("SplitAndSelect")
}
}
但是需要注意的是经过 split 拆分后的流,是不能二次拆分的,否则会报错:
Exception in thread "main" java.lang.IllegalStateException: Consecutive multiple splits are not supported. Splits are deprecated. Please use side-outputs.
在源码中可以看到注释,该方式已经废弃并且建议使用最新的 SideOutPut 进行分流操作
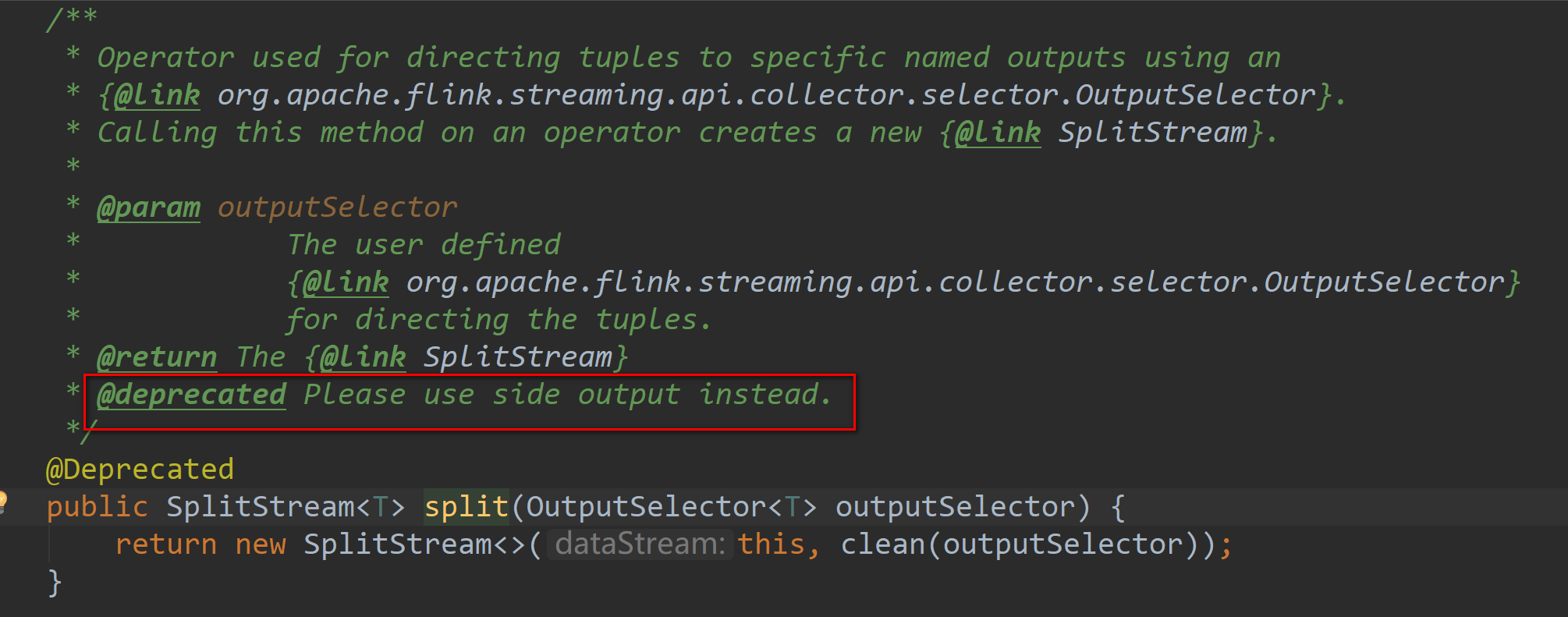
- SideOutPut 拆分:
- 定义 OutputTag
- 调用特定函数进行数据拆分
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
package com.xxd.flink.operator
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala.{DataStream, OutputTag, StreamExecutionEnvironment}
import org.apache.flink.util.Collector
import org.apache.flink.api.scala._
/**
* SideOutPut 可以多次分流
*
* @author xiandongxie
*/
object SideOutPutDemo {
def main(args: Array[String]): Unit = {
val logPath: String = "/tmp/logs/flink_log"
// 生成对象
var conf: Configuration = new Configuration()
// 开启flink web UI
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
// 配置web UI的日志文件,否则打印日志到控制台
conf.setString("web.log.path", logPath)
// 配置taskManager的日志文件,否则打印到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, logPath)
// 获取local运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
val input: DataStream[Long] = env.generateSequence(0, 10)
/**
* 根据奇数偶数拆分
*/
// 定义 OutputTag
val evenOutPutTag: OutputTag[Long] = new OutputTag[Long]("even")
val oddOutPutTag: OutputTag[Long] = new OutputTag[Long]("odd")
// 调用特定函数进行数据拆分
val processStream: DataStream[Long] = input.process(new ProcessFunction[Long, Long] {
override def processElement(value: Long, ctx: ProcessFunction[Long, Long]#Context, out: Collector[Long]): Unit = {
if (value % 2 == 0) {
ctx.output(evenOutPutTag, value)
} else {
ctx.output(oddOutPutTag, value)
}
}
})
// processStream.getSideOutput(oddOutPutTag).printToErr()
val eventStream: DataStream[Long] = processStream.getSideOutput(evenOutPutTag)
// 偶数的基础上根据是否为2拆分
val twoOutPutTag: OutputTag[Long] = new OutputTag[Long]("two")
val otherOutPutTag: OutputTag[Long] = new OutputTag[Long]("other")
val processStream2: DataStream[Long] = eventStream.process(new ProcessFunction[Long, Long] {
override def processElement(value: Long, ctx: ProcessFunction[Long, Long]#Context, out: Collector[Long]): Unit = {
if (value == 2) {
ctx.output(twoOutPutTag, value)
} else {
ctx.output(otherOutPutTag, value)
}
}
})
processStream2.getSideOutput(twoOutPutTag).printToErr()
processStream2.getSideOutput(otherOutPutTag).print()
env.execute("SideOutPutDemo")
}
}
8、物理分区
- 算子间数据传递模式
- One-to-one streams 保持元素的分区和顺序
- Redistributing streams
- 改变流的分区策略取决于使用的算子
- keyBy()(re-partitions by hashing the key)
- broadcast()
- rebalance()(which re-partitions randomly)
- 都是Transformation,只是改变了分区
- 都是DataStream → DataStream
rebalance
- 含义:再平衡,用来减轻数据倾斜
- 转换关系: DataStream → DataStream
- 使用场景:处理数据倾斜,比如某个kafka的partition的数据比较多
示例代码:
val stream: DataStream[MyType] = env.addSource(new FlinkKafkaConsumer[String](...))
val str1: DataStream[(String, MyType)] = stream.flatMap { ... }
val str2: DataStream[(String, MyType)] = str1.rebalance()
val str3: DataStream[AnotherType] = str2.map { ... }
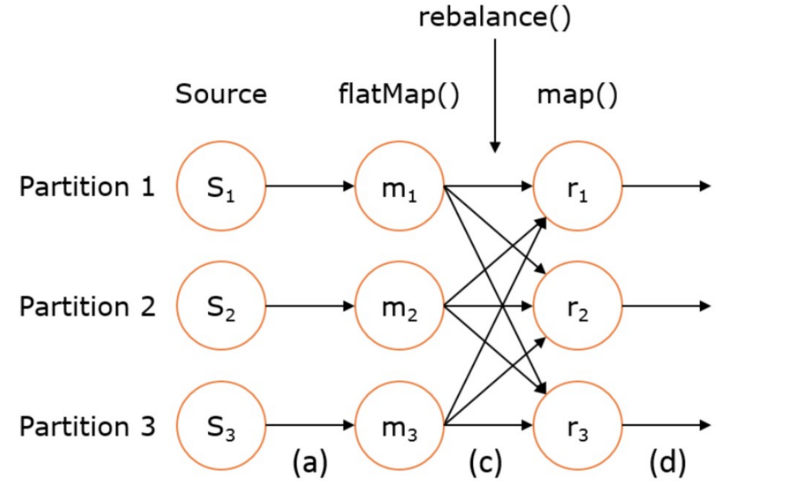
如上图的执行图所示,DataStream 各个算子会并行运行,算子之间是数据流分区。如 Source 的第一个并行实例 (S1)和 flatMap() 的第一个并行实例(m1)之间就是一个数据流分区。而在 flatMap() 和 map() 之间由于加了 rebalance(),它们之间的数据流分区就有3个子分区(m1的数据流向3个map()实例)。
rescale
- 原理:通过轮询调度将元素从上游的task一个子集发送到下游task的一个子集
- 转换关系:DataStream → DataStream
- 使用场景:数据传输都在一个TaskManager内,不需要通过网络。
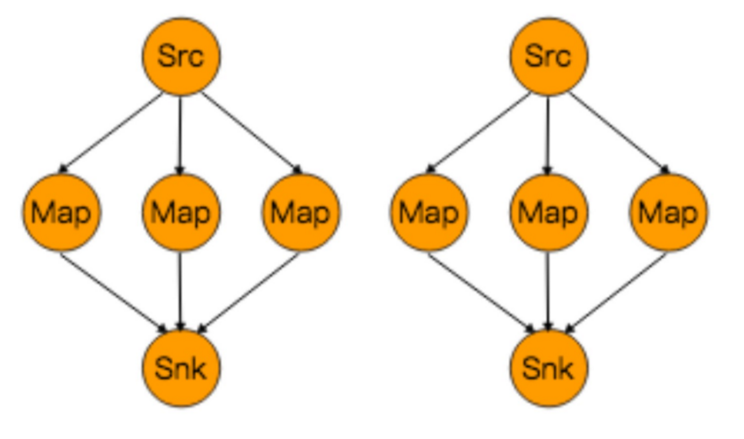
如下图所示:第一个task并行度为2,第二个task并行度为6,第三个task并行度为2。从第一个task到第二个task,Src的 子集 Src1 和 Map的子集Map1,2,3对应起来,Src1会以轮询调度的方式分别向Map1,2,3发送记录。 从第二个 task到第三个task,Map的子集1,2,3对应Sink的子集1,这三个流的元素只会发送到Sink1。 假设我们每个 TaskManager有三个Slot,并且我们开了 SlotSharingGroup,那么通过rescale,所有的数据传输都在一个 TaskManager内,不需要通过网络。
自定义partitioner
- 转换关系:DataStream → DataStream
- 使用场景:自定义数据处理负载
- 实现方法:
- 实现org.apache.flink.api.common.functions.Partitioner接口
- 覆盖partition方法
- 设计算法返回partitionId
import org.apache.flink.api.common.functions.Partitioner
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment object CustomPartitioner {
def main(args: Array[String]): Unit = {
val logPath: String = "/tmp/logs/flink_log"
// 生成对象
var conf: Configuration = new Configuration()
// 开启flink web UI
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
// 配置web UI的日志文件,否则打印日志到控制台
conf.setString("web.log.path", logPath)
// 配置taskManager的日志文件,否则打印到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, logPath)
// 获取local运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
//scala开发需要加一行隐式转换,否则在调用operator的时候会报错
import org.apache.flink.api.scala._
val tuple = List(
("xxd", "class12", "小王", 50),
("xxd", "class12", "小李", 55),
("xxd", "class11", "小张", 50),
("xxd", "class11", "小强", 45))
// 定义数据源,使用集合生成
val input = env.fromCollection(tuple)
//第二个参数 _._2 是指定partitioner的key是数据中的那个字段
input.partitionCustom(new MyFlinkPartitioner, _._2).print()
env.execute()
}
} //由于返回的永远是1,所以所有的数据都跑到第2个分区
class MyFlinkPartitioner extends Partitioner[String] {
override def partition(key: String, numPartitions: Int): Int = {
println(key)
1
}
}
5、flink常见函数使用及自定义转换函数的更多相关文章
- ORACLE常用数值函数、转换函数、字符串函数
本文更多将会介绍三思在日常中经常会用到的,或者虽然很少用到,但是感觉挺有意思的一些函数.分二类介绍,分别是: 著名函数篇 -经常用到的函数 非著名函数篇-即虽然很少用到,但某些情况下却很实用 注:N表 ...
- 关于jqGrig如何写自定义格式化函数将JSON数据的字符串转换为表格各个列的值
首先介绍一下jqGrid是一个jQuery的一个表格框架,现在有一个需求就是将数据库表的数据拿出来显示出来,分别有id,name,details三个字段,其中难点就是details字段,它的数据是这样 ...
- SQL Fundamentals || Single-Row Functions || 转换函数 Conversion function
SQL Fundamentals || Oracle SQL语言 SQL Fundamentals: Using Single-Row Functions to Customize Output使 ...
- javascript 自定义动画函数
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xht ...
- C++ 构造转换函数和强制转换函数
http://blog.csdn.net/chenyiming_1990/article/details/8862497 1.对于系统的预定义基本类型数据,C++提供了两种类型转换方式:隐式类型转换和 ...
- C++的转换函数
听侯捷老师的讲课笔记: 所谓转换函数指的是类型之间的转换,比如把自定义的类类型转换成内建类型(比如double),后者向相反的方向转. 直接上代码: 头文件conversion_function.h: ...
- Spark基于自定义聚合函数实现【列转行、行转列】
一.分析 Spark提供了非常丰富的算子,可以实现大部分的逻辑处理,例如,要实现行转列,可以用hiveContext中支持的concat_ws(',', collect_set('字段'))实现.但是 ...
- 【翻译】Flink Table Api & SQL — Hive —— Hive 函数
本文翻译自官网:Hive Functions https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/hive/h ...
- Python:Base4(map,reduce,filter,自定义排序函数(sorted),返回函数,闭包,匿名函数(lambda) )
1.python把函数作为参数: 在2.1小节中,我们讲了高阶函数的概念,并编写了一个简单的高阶函数: def add(x, y, f): return f(x) + f(y) 如果传入abs作为参数 ...
随机推荐
- [POI2014][树形DP]FarmCraft
题目 In a village called Byteville, there are houses connected with N-1 roads. For each pair of houses ...
- el-table分页展示数据
<el-table :data="tableData.slice((currentPage-1)*pageSize,currentPage*pageSize)" :show- ...
- MyBatis整合Spring原理分析
目录 MyBatis整合Spring原理分析 MapperScan的秘密 简单总结 假如不结合Spring框架,我们使用MyBatis时的一个典型使用方式如下: public class UserDa ...
- NKOJ 7.7练习题A IP地址
问题描述 可以用一个网络地址和一个子网掩码描述一个子网(即连续的 IP 地址范围).其中子网掩码包含 32 个二进制位,前 32-n 位为 1,后 n 位为 0,网络地址的前 32-n 位任意,后 n ...
- 在markdown中怎么划线?-[markdown]
使用html标签:<hr/> 示例: 百灵鸟,飞过蓝天. <hr/> 我爱你,我亲爱的祖国. <hr/> 生为华夏傲骨,死是华夏精魂. 效果: ![](https: ...
- 对Web语义化的思考。
很有意思的HTML语义化 在昨天和做SEO的同学聊了一会儿,当然我没有学会搜索引擎优化的技巧和知识,但在此之前一直对HTML5中header.footer.sidebar.article等标签嗤之以鼻 ...
- VAuditDemo代码审计
简介 先提一嘴,代码审计流程大概可以归结为:把握大局,定向功能,敏感函数参数回溯. 本文也是按照此思路进行,还在最后增加了漏洞修补方法. 本人平时打打CTF也有接触过代码审计,但都是零零散散的知识点. ...
- Golang微信支付跳过X509验证
游戏支付提交到微信的post: 微信: https://pay.weixin.qq.com/wiki/doc/api/micropay.php?chapter=23_4 错误信息: err:Post ...
- docker-compose 部分错误
Get https://hub.17kxkx.com/v2/: dial tcp 39.106.209.67:443: connect: connection refused vim /etc/doc ...
- <E> 泛型
/* * 使用集合存储自定义对象并遍历 * 由于集合可以存储任意类型的对象,当我们存储了不同类型的对象,就有可能在转换的时候出现类型转换异常, * 所以java为了解决这个问题,给我们提供了一种机制, ...