3.K均值算法
一、概念
K-means中心思想:事先确定常数K,常数K意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,接着,重新计算每个类的质心(即为类中心),重复这样的过程,直到质心不再改变,最终就确定了每个样本所属的类别以及每个类的质心。由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢。
二、特点:
常用距离
a.欧式距离
b.曼哈顿距离
三、算法流程
K-means是一个反复迭代的过程,算法分为四个步骤:
(x,k,y)
(1) 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心;
def initcenter(x, k): kc
(2) 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
def nearest(kc, x[i]): j
def xclassify(x, y, kc):y[i]=j
(3) 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值;
def kcmean(x, y, kc, k):
(4) 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)。
while flag:
y = xclassify(x, y, kc)
kc, flag = kcmean(x, y, kc, k)
四、实践
(1).扑克牌手动演练k均值聚类过程:>30张牌,3类
①本次模拟k均值用到的扑克牌,初始中心为(2,9,12)

②经过一轮计算(选出中心:3,8,12)
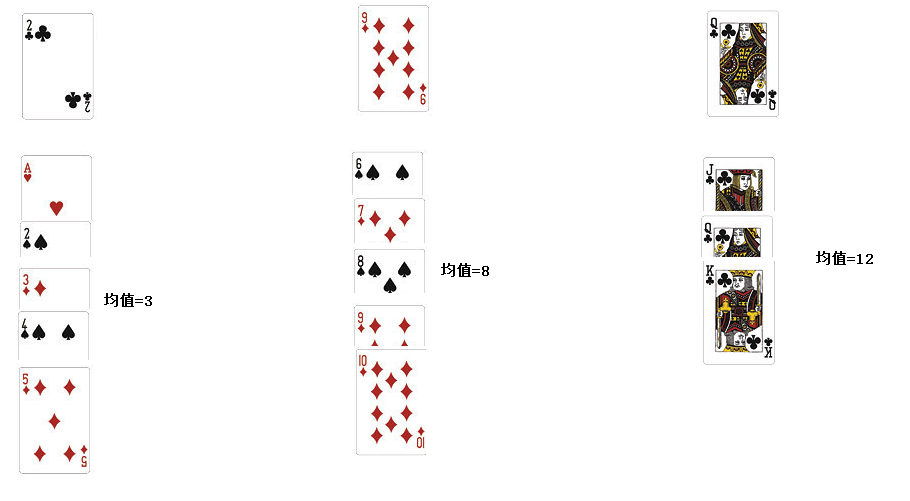
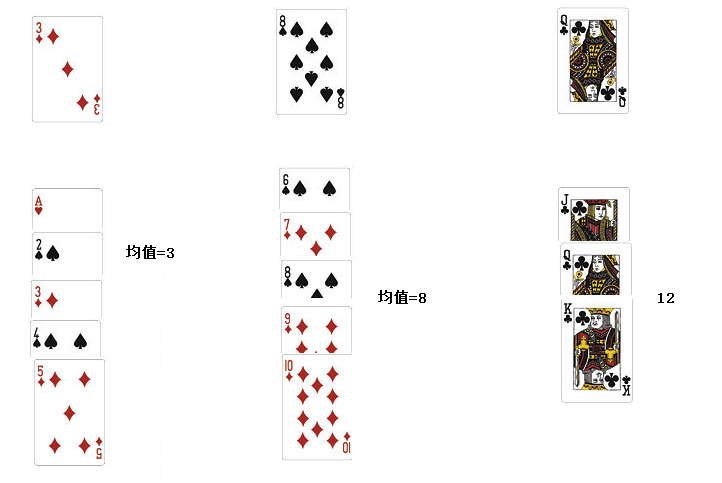
③一直算到最后
(2).*自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。
### 1、导入鸢尾花数据
from sklearn.datasets import load_iris
import numpy as np ### 2、鸢尾花数据
iris = load_iris()
data=iris['data'] #样本属性个数
m=data.shape[1]
#样本个数
n=len(data)
#类中心个数,即最终分类
k=3 ### 3、数据初始化
#距离矩阵
dist=np.zeros([n,k+1])
#初始类中心
center=np.zeros([k,m])
#新的类中心
new_center=np.zeros([k,m])
### 4、选中心
#选择前三个样本作为初始类中心
center=data[:k, :] while True:
#求距离
for i in range(n):
for j in range(k):
dist[i,j]=np.sqrt(sum((data[i,:]-center[j,:])**2))
#归类
dist[i,k]=np.argmin(dist[i,:k])
#求新类中心
for i in range(k):
index=dist[:,k]==i
new_center[i,:]=np.mean(data[index, :])
#判断结束
if(np.all(center==new_center)):
break
else:
center=new_center
print('聚类结果:',dist[:,k])

(3)用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示。
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt # 获取鸢尾花数据集
iris = load_iris()
data = iris.data[:, 1]
# 鸢尾特征值
x = data.reshape(-1, 1)
# 构建模型
model = KMeans(n_clusters=3)
# 训练
model.fit(x)
# 预测样本的聚类索引
y = model.predict(x)
print("预测结果:", y)
#画图
plt.scatter(x[:, 0], x[:, 0], c=y, s=50, cmap='rainbow')
plt.show()
预测结果:

散点图可视化:

(4)鸢尾花完整数据做聚类并用散点图显示。
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt # 导入鸢尾花数据集
iris = load_iris()
# 鸢尾花花瓣长度数据
x = iris.data
# 构建模型
model = KMeans(n_clusters=3)
# 训练
model.fit(x)
# 预测
y = model.predict(x)
print("预测结果:", y)
#画图
plt.scatter(x[:, 2], x[:, 3], c=y, s=50, cmap='rainbow')
plt.show()
预测结果:

散点图可视化:

(5)想想k均值算法中以用来做什么?
- 文本分析和归类
- K均值算法实现图像压缩
- 像素处理
- K均值算法处理图像
3.K均值算法的更多相关文章
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- K均值算法
为了便于可视化,样本数据为随机生成的二维样本点. from matplotlib import pyplot as plt import numpy as np import random def k ...
- K均值算法-python实现
测试数据展示: #coding:utf-8__author__ = 'similarface''''实现K均值算法 算法摘要:-----------------------------输入:所有数据点 ...
- spark Bisecting k-means(二分K均值算法)
Bisecting k-means(二分K均值算法) 二分k均值(bisecting k-means)是一种层次聚类方法,算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二.之后选择能最大程 ...
随机推荐
- c strncpy 容易出错的地方
使用strncpy的是注意两点,目的是数组和目的是指针 .目的是数组: ] = "abcde"; // ] = "; strncpy(dest,src,N); dest[ ...
- python对接elasticsearch的基本操作
基本操作 #!/usr/bin/env python # -*- coding: utf-8 -*- # author tom from elasticsearch import Elasticsea ...
- CentOS系统python默认版本由python2改为python3
一.了解 CentOS中如果安装有yum,一般会有python2的某个版本.命令行键入python,出现的python2的环境: [root@instance-hrnebyqu src]# pytho ...
- py123第一次作业
绘制五角星<br>import turtle turtle.setup(600,350,200,200) turtle.pensize(2) turtle.pencolor(" ...
- django 和 七牛云 交互
django 和 七牛云 交互 七牛开发文档 安装 pip install qiniu 初始化 # access_key 个人中心的 ak # secret_key 个人中心的 sk from qin ...
- 什么是yarn,如何使用yarn安装项目依赖
一.yarn的简介: Yarn是facebook发布的一款取代npm的包管理工具. 二.yarn的特点: 1.速度超快. Yarn 缓存了每个下载过的包,所以再次使用时无需重复下载. 同时利用并行下载 ...
- vscode 的tab空格设置设置为4的方法
1.点击“文件>首选项>设置” 进入设置页面,设置如下几个选项 2.在“文件>首选项>设置” 的“用户设置”里添加 "editor.detectIndentation ...
- 靓仔,整合SpringBoot还在百度搜配置吗?老司机教你一招!!!
导读 最近陈某公司有些忙,为了保证文章的高质量可能要两天一更了,在这里陈某先说声不好意思了!!! 昨天有朋友问我SpringBoot如何整合Redis,他说百度谷歌搜索了一遍感觉不太靠谱.我顿时惊呆了 ...
- Android UI性能测试——使用 Systrace 查找问题
一 官方文档翻译 官文地址:https://developer.android.com/studio/command-line/systrace systrace命令允许您在系统级别上收集和检查所有运 ...
- angularJS表达式和指令
主要是描述angularJS如何扩展html的:(模型后面会涉及) 例子1:通过指令来扩展html <body ng-app="myapp"> <!-- ng ...