聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法
import numpy as np
x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数
y = np.zeros(20)
k = 3
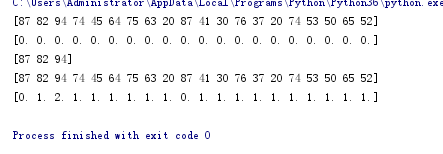
print(x)
print(y) def initcenter(x,k):#初始化聚类中心数组
return x[0:k].reshape(k)
kc = initcenter(x,k)
print(kc) def nearest(kc, i):#定义函数求出kc与i之差最小的数的坐标
d = (abs(kc - i))
w = np.where(d == np.min(d))
return w[0][0] # print(nearest(kc,66)) # for i in range(x.shape[0]):
# y[i] = nearest(kc,x[i])
# print(y) def xclassify(x, y, kc):#按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类
for i in range(x.shape[0]):
y[i] = nearest(kc,x[i])
return y y = xclassify(x,y,kc)
print(x)
print(y)
#.用sklearn.cluster.KMeans,鸢尾花完整数据做聚类并用散点图显示.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris
iris=load_iris()
print(iris)
X=iris.data
print(X)
from sklearn.cluster import KMeans
est = KMeans(n_clusters=3)
est.fit(X)
kc = est.cluster_centers_
y_kmeans = est.predict(X) #预测每个样本的聚类索引
print(y_kmeans,kc)
print(kc.shape,y_kmeans.shape)
plt.scatter(X[:,0],X[:,1],c=y_kmeans,s=50,cmap='rainbow')
plt.show()
# 鸢尾花完整数据做聚类并用散点图显示.
from sklearn.cluster import KMeans
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
data = load_iris()
iris = data.data
petal_len = iris
print(petal_len)
k_means = KMeans(n_clusters=3) #三个聚类中心
result = k_means.fit(petal_len) #Kmeans自动分类
kc = result.cluster_centers_ #自动分类后的聚类中心
y_means = k_means.predict(petal_len) #预测Y值
plt.scatter(petal_len[:,0],petal_len[:,2],c=y_means, marker='p',cmap='rainbow')
plt.show()
聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用的更多相关文章
- 第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np x = np.random.randint(1,100,[20,1]) y = np.zeros(20) k = 3 def initcenter(x,k): r ...
- 聚类--K均值算法
import numpy as np from sklearn.datasets import load_iris iris = load_iris() x = iris.data[:,1] y = ...
- K 均值算法-如何让数据自动分组
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍到的一些机器学习算法都是监督学习算法.所谓监督学习,就是既有特征数据,又有目标数据. 而本篇文章要介绍 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 3.K均值算法
一.概念 K-means中心思想:事先确定常数K,常数K意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,接着,重新 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
随机推荐
- laravel(lumen)配置读写分离后,强制读主(写)库数据库,解决主从延迟问题
在Model里面加上下面这句,强制读主(写)库数据库,解决主从延迟问题. public static function boot() { //清空从连接,会自动使用主连接 DB::connection ...
- 【基于微信小程序的社区电商平台】需求分析心得——小豆芽
一.项目内容 基于微信小程序,做一个社区电商平台,抓住社区电商的特点,做出特色,与微信集成,实现商品的个性化发布,以及个性化营销. 个性化发布:用户可以在应用上直接发布自己的商品,通过搜索心愿单可以查 ...
- webpack - minipack 打包原理
code:https://github.com/ronami/minipack 看了https://www.youtube.com/watch?v=Gc9-7PBqOC8总结一下 工具和环境: nod ...
- spring cloud + spring boot + springmvc+mybatis分布式微服务云架构
做一个微服务架构需要的技术整理: View: H5.Vue.js.Spring Tag.React.angularJs Spring Boot/Spring Cloud:Zuul.Ribbon.Fei ...
- 自己动手写CPU——寄存器堆、数据存储器(基于FPGA与Verilog)
上一篇写的是基本的设计方案,由于考研复习很忙,不知道下一次什么时候才能打开博客,今天就再写一篇.写一写CPU中涉及到RAM的部件,如寄存器堆.数据存储器等. 大家应该在大一刚接触到计算机的时候就知道R ...
- python模块和包(模块、包、发布模块)
模块和包 目标 模块 包 发布模块 01. 模块 1.1 模块的概念 模块是 Python 程序架构的一个核心概念 每一个以扩展名 py 结尾的 Python 源代码文件都是一个 模块 模块名 同样也 ...
- Python 习题一
1.使用while循环输入 1 2 3 4 5 6 8 9 10 # Author:Tony.lou i = 1 while i < 11: if i == 7: pass else: prin ...
- Flutter 卡在 package get 的解决办法
今天在尝试使用Flutter 的时候,需要使用一个第三方库 修改了 pubspec 文件之后,AS 像往常一样提示 需要 package get. 之前都挺正常,不知道今天怎么了. 一直处在 Runn ...
- 配置Nim的默认编译参数 release build并运行
配置Nim的默认编译参数 release build并运行 默认情况下nim编译是debug build,如果需要release build, 需要加上-d:release , release编译的命 ...
- bom与dom的区别
文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展标志语言的标准编程接口.Document Object Model的历史可以追溯至1990年代后期微 ...