solr7.4创建core,导入MySQL数据,中文分词
#solr版本:7.4.0
一、新建Core
进入安装目录下得server/solr/,创建一个文件夹,如:new_core
拷贝server/solr/configsets/_default/conf/下的solrconfig.xml、protwords.txt、synonyms.txt、stopwords.txt文件和lang文件夹,到刚刚创建的new_core文件夹下
拷贝server/solr/configsets/_default/conf/下的schema.xml文件到刚刚创建的new_core文件夹下,将其重命名为schema.xml
进入solr页面选择Core Admin,设置好名字还有刚才新建的dir,Add Core
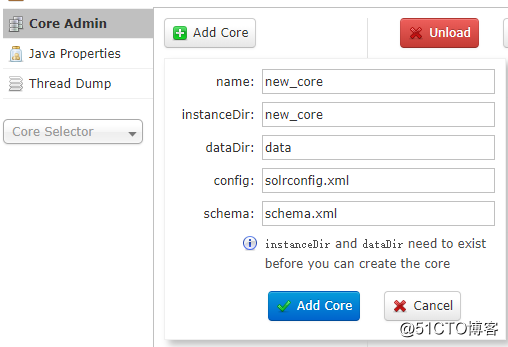
- 然后在core selector 就能看到刚才新建的core 了。
二、导入MySQL数据
- 打开刚添加的solrconfig.xml文件 vi server/solr/new_core/solrconfig.xml,查找一下requestHandler标签,在标签同级下加入导入数据的配置
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">db-data-config.xml</str>
</lst>
</requestHandler> - new_core下新增db-data-config.xml文件(样例在安装目录example/example-DIH/solr/db/conf/下有),并添加如下配置:
<dataConfig>
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/db_name" user="root" password="" />
<document>
<entity name="product"
query="select product_id as id,title from table_name"
deltaImportQuery="select product_id as id,title from table_name where PRODUCT_ID='${dih.delta.id}'"
deltaQuery="select product_id as id from table_name where add_time > '${dataimporter.last_index_time}'">
</entity>
</document>
</dataConfig> - 下载mysql-connector-java驱动 https://dev.mysql.com/downloads/connector/j/
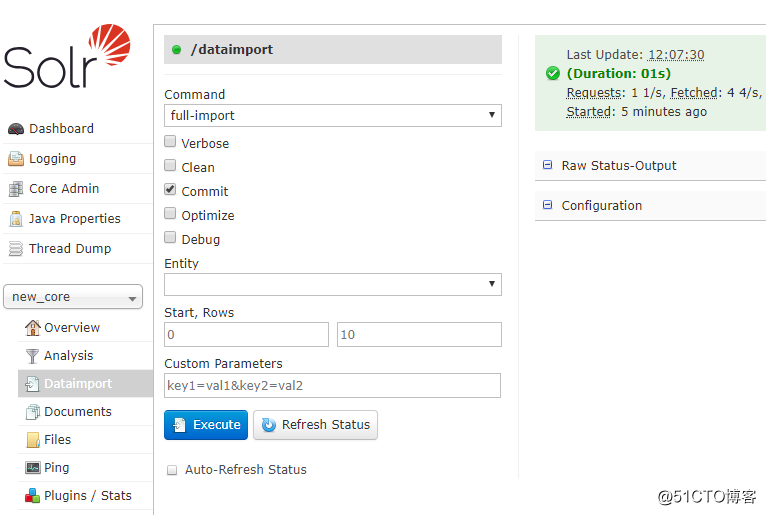
解压mysql-connector-java-(xxx).jar到安装目录下的server/solr-webapp/webapp/WEB-INF/lib - 在页面上选择Dataimport应该有了
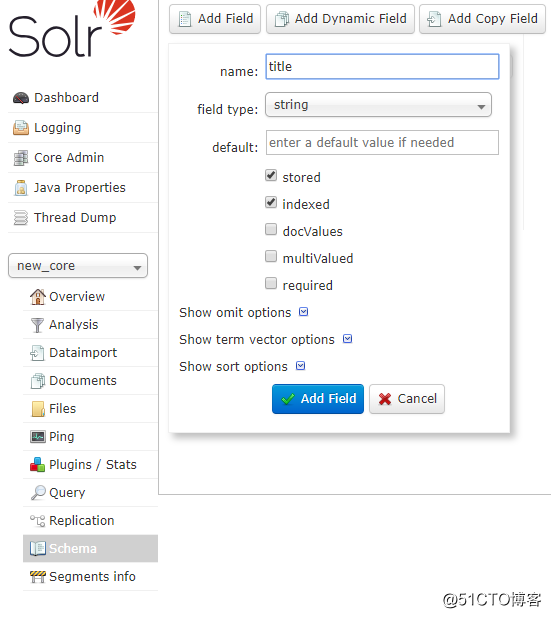
- 在Schema上添加字段,如title(要存在query属性的sql语句能查出来的那些字段当中)

- 在Dataimport 上执行导入,可以看到已经新增了4条记录了
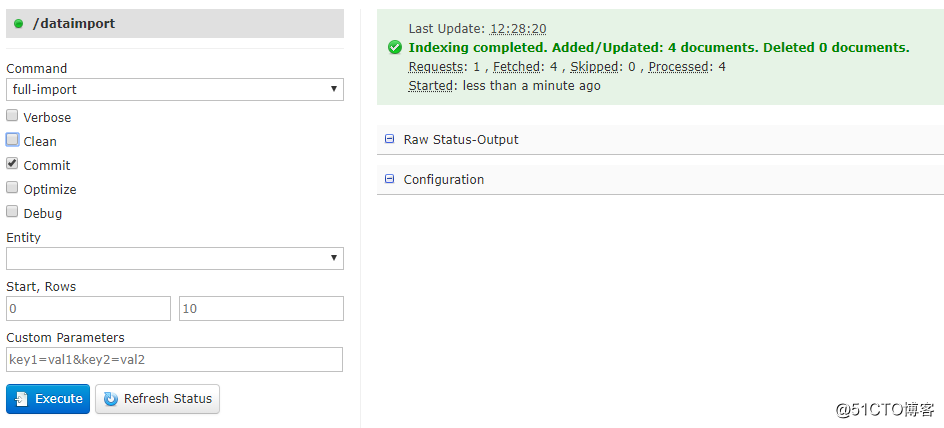
然后在query上查看导入结果
三、增量导入MySQL数据
- 导入数据不可能每次全量导入,新增的数据只要增量导入就好,检查db-data-config.xml配置,确保有deltaImportQuery, deltaQuery两项
last_index_time会保存在这个core的Instance目录下的conf/dataimport.properties文件
- 现在我在数据表中再插入几条数据
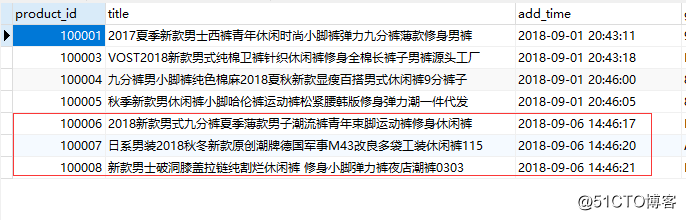
- 这次我们在页面选择delta-import执行一下看看
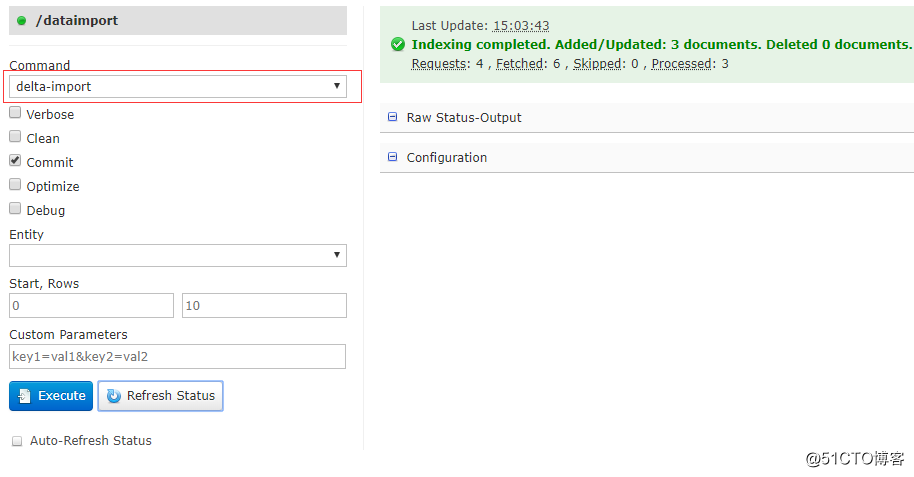
- 再去看下结果,也成功导入

5.这是细心的人会发现dataimport.properties记录的是UTC时间,而数据表中用的是中国时间,要怎么让它们一致呢?
这里提供一个解决办法,利用sql语句来转换时区:
修改deltaQuerySELECT product_id AS id FROM table_name WHERE add_time > '${dataimporter.last_index_time}'改为
SELECT product_id AS id FROM table_name WHERE add_time > CONVERT_TZ('${dataimporter.last_index_time}', '+00:00', '+08:00')
四、中文分词
- 拷贝分词jar到指定目录server/solr-webapp/webapp/WEB-INF/lib/
cp contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-7.4.0.jar server/solr-webapp/webapp/WEB-INF/lib/ - 编辑schema文件 vi server/solr/new_core/conf/managed-schema
添加:<fieldType name="text_cn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>把title改为text_cn类型
- 重启solr,title已经改为text_cn,但是还没分词效果
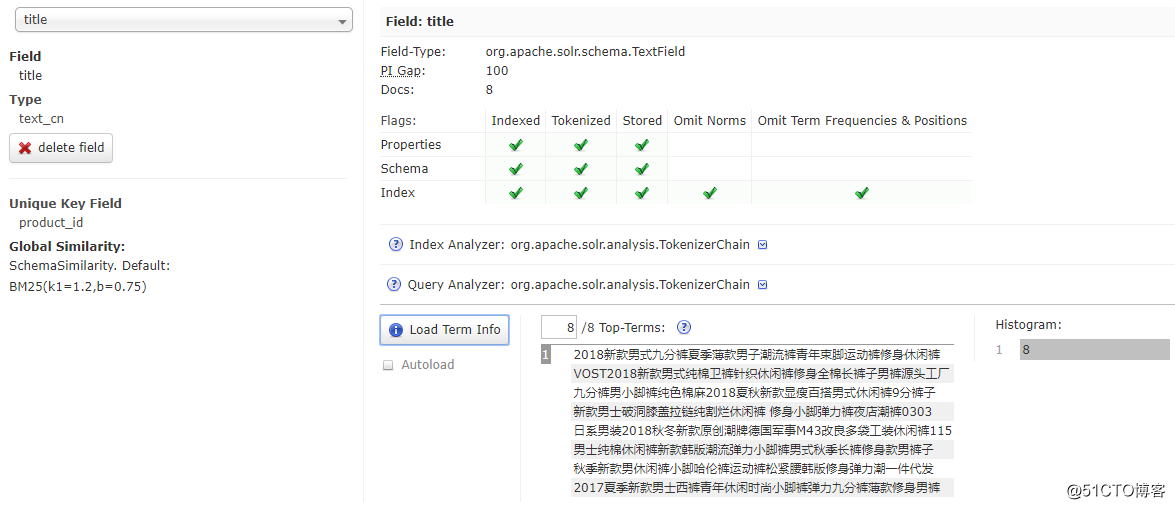
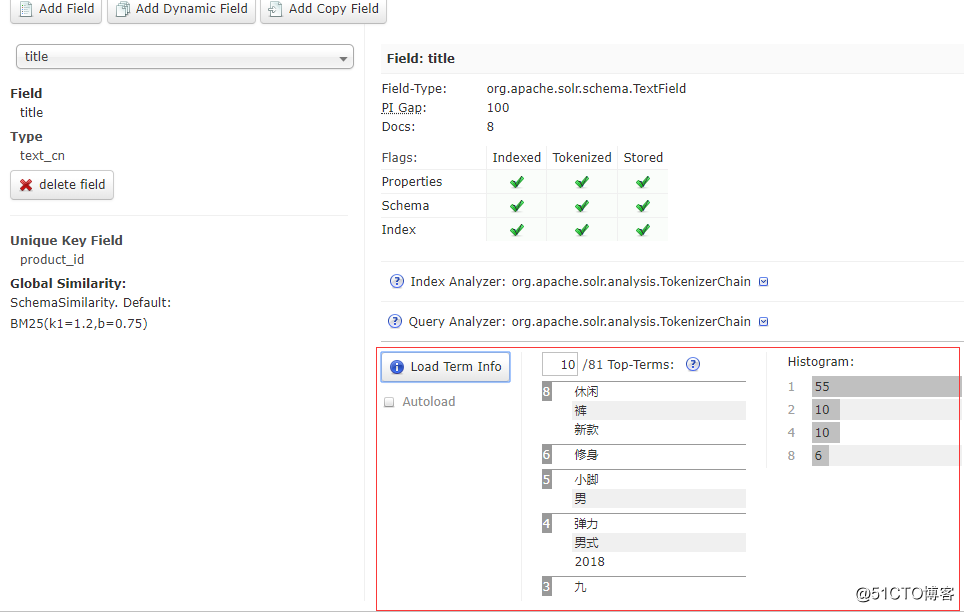
- 在dataimport选择clean再full-import一次,重新导入数据,再回到字段查看一下Term Info ,这次分词成功了
转载于:https://blog.51cto.com/13956067/2170843
solr7.4创建core,导入MySQL数据,中文分词的更多相关文章
- 在eclipse中构建solr项目+添加core+整合mysql+添加中文分词器
最近在研究solr,这里只记录一下eclipse中构建solr项目,添加core,整合mysql,添加中文分词器的过程. 版本信息:solr版本6.2.0+tomcat8+jdk1.8 推荐阅读:so ...
- Solr7.1---数据库导入并建立中文分词器
这里只是告诉你如何导入,生产环境不要这样部署你的solr服务. 首先修改solrConfig.xml文件 备份_default文件夹 修改solrconfig.xml 加入如下内容 官方示例:< ...
- [转]mysql导入导出数据中文乱码解决方法小结
本文章总结了mysql导入导出数据中文乱码解决方法,出现中文乱码一般情况是导入导入时编码的设置问题,我们只要把编码调整一致即可解决此方法,下面是搜索到的一些方法总结,方便需要的朋友. linux系统中 ...
- Asp.Net Core 导入Excel数据到Sqlite数据库并重新导出到Excel
Asp.Net Core 导入Excel数据到Sqlite数据库并重新导出到Excel 在博文"在Asp.Net Core 使用 Sqlite 数据库"中创建了ASP.NET Co ...
- Sqoop导入mysql数据到Hbase
sqoop import --driver com.mysql.jdbc.Driver --connect "jdbc:mysql://11.143.18.29:3306/db_1" ...
- Solr 创建core 从MySql数据库中导入数据
一.创建数据表和数据 在MySql数据中创建mysolrInfo表, 创建字段 id 主键,自动增加 pname :姓名 age :年龄 addtime :增加时间 增加几条数据 二.创建core 当 ...
- mysql导入导出数据中文乱码解决方法小结
linux系统中 linux默认的是utf8编码,而windows是gbk编码,所以会出现上面的乱码问题. 解决mysql导入导出数据乱码问题 首先要做的是要确定你导出数据的编码格式,使用mysqld ...
- Solr-5.3.1 dataimport 导入mysql数据
最近需要计算制造业领域大词表每个词的idf,词表里一共九十多万个词,语料一共三百七十多万篇分词后文献.最开始尝试用程序词表循环套语料循环得到每个词的idf,后来又尝试把语料存入mysql然后建立全文索 ...
- HeidiSQL工具导出导入MySQL数据
有时候,为了数据方便导出导入SQL,我们可以借助一定的工具,方便我们队数据库的移植,可以达到事半功倍的效果.在这里,就给大家简单的介绍一款能方便导出或者导入MySQL的数据. ①首先,选择你要导出的数 ...
随机推荐
- PTA数据结构与算法题目集(中文) 7-16
PTA数据结构与算法题目集(中文) 7-16 7-16 一元多项式求导 (20 分) 设计函数求一元多项式的导数. 输入格式: 以指数递降方式输入多项式非零项系数和指数(绝对值均为不超过1000 ...
- Linux系统安装Dos系统(虚拟机里装)
结合以下两篇优秀的文章就能完成任务. 1.https://www.jb51.net/os/609411.html 2.http://blog.51cto.com/6241809/1687361 所需要 ...
- 中阶 d04 xml 概念及使用
idea新建xml文件https://www.jianshu.com/p/b8aeadae39b0 或https://blog.csdn.net/Hi_Boy_/article/details/804 ...
- tf.train.MomentumOptimizer 优化器
tf.train.MomentumOptimizer( learning_rate, momentum, use_locking=False, use_nesterov=False, name='Mo ...
- EL表达式---自定义函数(转)
EL表达式---自定义函数(转) 有看到一个有趣的应用了,转下来,呵呵!! 1.定义类MyFunction(注意:方法必须为 public static) package com.tgb.jstl; ...
- Odoo 查看 模块app 对应的 源码 相关依赖模块信息
安装好app后再路径上 加上debug ,在查看 app 信息 如下 http://127.0.0.1:8069/web?debug#id=138&view_type=form&mod ...
- FJUT2019暑假第二次周赛题解
A 服务器维护 题目大意: 给出时间段[S,E],这段时间需要人维护服务器,给出n个小时间段[ai,bi],代表每个人会维护的时间段,每个人维护这段时间有一个花费,现在问题就是维护服务器[S,E]这段 ...
- 深入理解JS原型与原型链
函数的prototype 1.函数的prototype属性 *每个函数都有一个prototype属性,它默认指向一个Object空对象(即称为原型对 象) * 原型对象中都有一个属性construct ...
- A - Free DIY Tour HDU - 1224
题目大意:每一个城市都有一定的魅力值,然后有一个有向图,根据这个有向图从1到n+1所获得的魅力的最大值,并输出路径(要求只能从编号娇小的城市到编号较大的城市). 题解:很容易想到最短路+路径纪录.但是 ...
- B - Raising Modulo Numbers
People are different. Some secretly read magazines full of interesting girls' pictures, others creat ...