scikit-learn 学习笔记-- Generalized Linear Models (二)
Lasso regression
今天介绍另外一种带正则项的线性回归, ridge regression 的正则项是二范数,还有另外一种是一范数的,也就是lasso 回归,lasso 回归的正则项是系数的绝对值之和,这种正则项会让系数最后变得稀疏:
其中,N" role="presentation" style="position: relative;">NN 是样本的个数。
Elastic Net
Elastic Net 这种线性回归将二范数和一范数的正则都考虑进去了,两种正则项以某种权重的方式组合在一起,所以类似一种弹性的模型,这大概也是其名称的由来吧,elastic net 的目标函数为:
elastic net 模型可以让模型像 lasso regression 一样具有一定的稀疏性,同时又保持 ridge regression 的稳定性
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import r2_score
np.random.seed(42)
n_samples, n_features = 100, 100
X = np.random.randn(n_samples, n_features)
coef = 3 * np.random.randn(n_features)
inds = np.arange(n_features)
np.random.shuffle(inds)
coef[inds[10:]] = 0 # sparsify coef
y = np.dot(X, coef)
# add noise
y += 0.01 * np.random.normal(size=n_samples)
# Split data in train set and test set
n_samples = X.shape[0]
X_train, y_train = X[:n_samples // 2], y[:n_samples // 2]
X_test, y_test = X[n_samples // 2:], y[n_samples // 2:]
# #############################################################################
# Lasso
from sklearn.linear_model import Lasso
alpha = 0.1
lasso = Lasso(alpha=alpha)
y_pred_lasso = lasso.fit(X_train, y_train).predict(X_test)
r2_score_lasso = r2_score(y_test, y_pred_lasso)
print(lasso)
print("r^2 on test data : %f" % r2_score_lasso)
# #############################################################################
# ElasticNet
from sklearn.linear_model import ElasticNet
enet = ElasticNet(alpha=alpha, l1_ratio=0.7)
y_pred_enet = enet.fit(X_train, y_train).predict(X_test)
r2_score_enet = r2_score(y_test, y_pred_enet)
print(enet)
print("r^2 on test data : %f" % r2_score_enet)
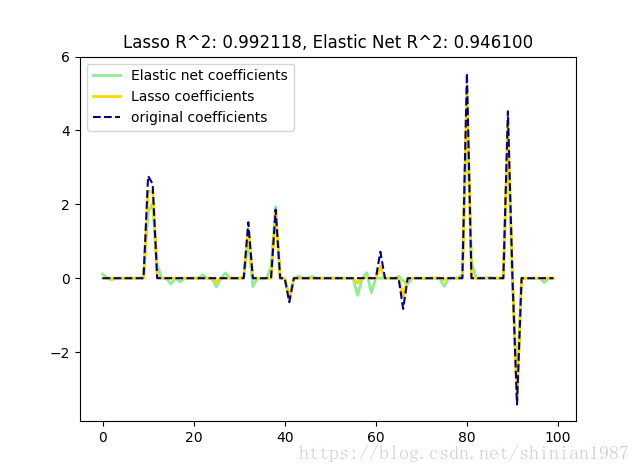
plt.plot(enet.coef_, color='lightgreen', linewidth=2,
label='Elastic net coefficients')
plt.plot(lasso.coef_, color='gold', linewidth=2,
label='Lasso coefficients')
plt.plot(coef, '--', color='navy', label='original coefficients')
plt.legend(loc='best')
plt.title("Lasso R^2: %f, Elastic Net R^2: %f"
% (r2_score_lasso, r2_score_enet))
plt.show()
#########################
**output**:
Lasso(alpha=0.1, copy_X=True, fit_intercept=True, max_iter=1000,
normalize=False, positive=False, precompute=False, random_state=None,
selection='cyclic', tol=0.0001, warm_start=False)
r^2 on test data : 0.992118
ElasticNet(alpha=0.1, copy_X=True, fit_intercept=True, l1_ratio=0.7,
max_iter=1000, normalize=False, positive=False, precompute=False,
random_state=None, selection='cyclic', tol=0.0001, warm_start=False)
r^2 on test data : 0.946100
#########################
scikit-learn 学习笔记-- Generalized Linear Models (二)的更多相关文章
- scikit-learn 学习笔记-- Generalized Linear Models (一)
scikit-learn 是非常优秀的一个有关机器学习的 Python Lib,包含了除深度学习之外的传统机器学习的绝大多数算法,对于了解传统机器学习是一个很不错的平台.每个算法都有相应的例子,既可以 ...
- scikit-learn 学习笔记-- Generalized Linear Models (三)
Bayesian regression 前面介绍的线性模型都是从最小二乘,均方误差的角度去建立的,从最简单的最小二乘到带正则项的 lasso,ridge 等.而 Bayesian regression ...
- Andrew Ng机器学习公开课笔记 -- Generalized Linear Models
网易公开课,第4课 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 前面介绍一个线性回归问题,符合高斯分布 一个分类问题,logstic回 ...
- 机器学习-scikit learn学习笔记
scikit-learn官网:http://scikit-learn.org/stable/ 通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测. 学习 ...
- [Scikit-learn] 1.1 Generalized Linear Models - from Linear Regression to L1&L2
Introduction 一.Scikit-learning 广义线性模型 From: http://sklearn.lzjqsdd.com/modules/linear_model.html#ord ...
- [Scikit-learn] 1.5 Generalized Linear Models - SGD for Regression
梯度下降 一.亲手实现“梯度下降” 以下内容其实就是<手动实现简单的梯度下降>. 神经网络的实践笔记,主要包括: Logistic分类函数 反向传播相关内容 Link: http://pe ...
- [Scikit-learn] 1.5 Generalized Linear Models - SGD for Classification
NB: 因为softmax,NN看上去是分类,其实是拟合(回归),拟合最大似然. 多分类参见:[Scikit-learn] 1.1 Generalized Linear Models - Logist ...
- [Scikit-learn] 1.1 Generalized Linear Models - Logistic regression & Softmax
二分类:Logistic regression 多分类:Softmax分类函数 对于损失函数,我们求其最小值, 对于似然函数,我们求其最大值. Logistic是loss function,即: 在逻 ...
- 广义线性模型(Generalized Linear Models)
前面的文章已经介绍了一个回归和一个分类的例子.在逻辑回归模型中我们假设: 在分类问题中我们假设: 他们都是广义线性模型中的一个例子,在理解广义线性模型之前需要先理解指数分布族. 指数分布族(The E ...
随机推荐
- POJ2891:Strange Way to Express Integers(解一元线性同余方程组)
写一下自己的理解,下面附上转载的:若a==b(modk);//这里的==指的是同余,我用=表示相等(a%k=b)a-b=kt(t为整数)以前理解的错误思想:以前认为上面的形式+(a-tb=k)也是成立 ...
- Ubuntu下navicat过期解决办法
Ubuntu下使用navicat过期.试用期是15天. 可以删除.navicat64/解决.不好的一点就是.需要重新连接数据库,以前的连接记录会被删除 rm -rf ~/.navicat64/
- SQL group by的使用
①定义 "group by" 从字面上理解是根据“by"指定的规则对数据进行分组 ②简单示例 ③group by 中的select字段是受限制的 select指定的字段要 ...
- 浅谈location对象
简介 Location 对象存储在 Window 对象的 Location 属性中,表示那个窗口中当前显示的文档的 Web 地址.通过Location对象,可以获取URL中的各项信息,调用对象方法也可 ...
- P1131 [ZJOI2007]时态同步(树形dp)
P1131 [ZJOI2007]时态同步 设$f[i]$为与$i$与最远的点的距离 在dfs时每次更新的时候顺便统计一下长度,不同的话就改成最长的那条并更新答案 #include<iostrea ...
- table中checkbox选择多行
页面代码 <table id="addressTable" class="ui-jqgrid-htable ui-common-table table table- ...
- MySQL "Zero date value prohibited" 问题解析
问题起因 之前一直使用Oracle数据,对MySQL数据库使用不多,因此搞不懂MySQL的日期“0000-00-00 00:00:00”对程序会产生怎样的影响.费了我一下午的时间 -_-^^. 首先: ...
- ajax post data 获取不到数据,注意 content-type的设置 、post/get
ajax post data 获取不到数据,注意 content-type的设置 .post/get 关于 jQuery data 传递数据.网上各种获取不到数据,乱码之类的. 好吧今天我也遇到了 ...
- SprigBoot核心技术
启动原理 运行流程 自动配置原理 一.启动原理 SpringApplication.run(主程序类)– new SpringApplication(主程序类)• 判断是否web应用• 加载并保存所有 ...
- Redis之Set 集合
Redis Set 集合 Set 就是一个集合,集合的概念就是一堆不重复值的组合.利用 Redis 提供的 Set 数据结构,可以存储一些集合性的数据. 比如在 微博应用中,可以将一个用户所有的关注人 ...