执行计划--在存储过程中使用SET对执行计划的影响
--如果在存储过程中定义变量,并为变量SET赋值,该变量的值无法为执行计划提供参考(即执行计划不考虑该变量),将会出现预估行数和实际行数相差过大导致执行计划不优的情况
--如果在存储过程中使用SET为存储过程参数重新赋值,执行计划仍采用执行时传入的值来生成执行计划。
--=======================================
--准备测试数据
DROP TABLE TB1
GO
SELECT IDENTITY(INT,1,1) AS RID,
*INTO TB1
FROM sys.all_columns
GO
INSERT INTO TB1
SELECT *
FROM sys.all_columns
GO 100
ALTER TABLE TB1
ADD PRIMARY KEY(RID)
--测试查询参数使用变量
--例如下列存储过程,由于在生成执行计划时不知道@ID的具体值,因此无法预估满足PID>@ID条件的
CREATE PROCEDURE dbo.USP_GetData
(
@PIDINT
)
AS
BEGIN
DECLARE @ID INT
SET @ID= @PID
SELECT *
FROM TB1
WHERE RID>@ID
END
GO
EXEC dbo.USP_GetData @PID=606808
--由于预估行数有问题,导致生成不使用索引的查询计划
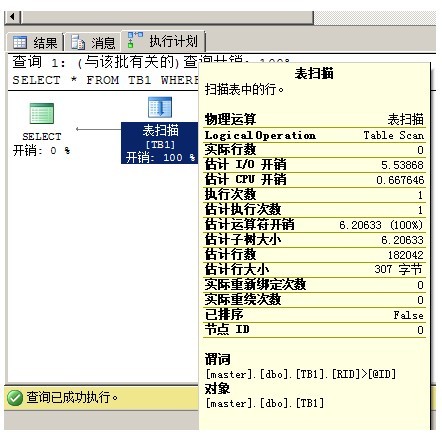
--=================================================
--测试修改传入参数的情况
--虽然传入参数在传入后被修改,但是生成执行计划时仍使用传入时的值
CREATE PROCEDURE dbo.USP_GetData2
(
@PID INT
)
AS
BEGIN
SET @PID=@PID-606800
SELECT*
FROM TB1
WHERE RID>@PID
END
GO
EXEC dbo.USP_GetData2 @PID=606808
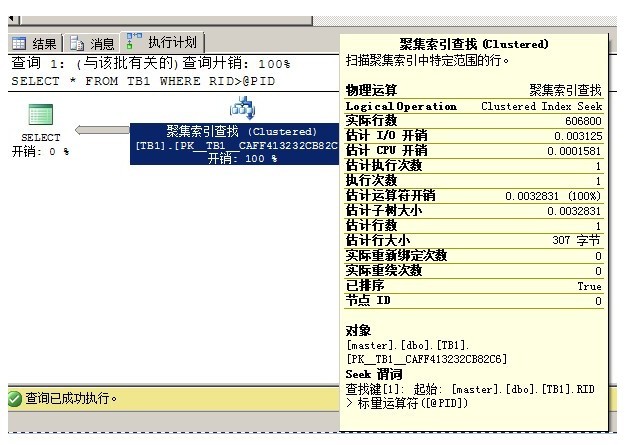
--=================================================
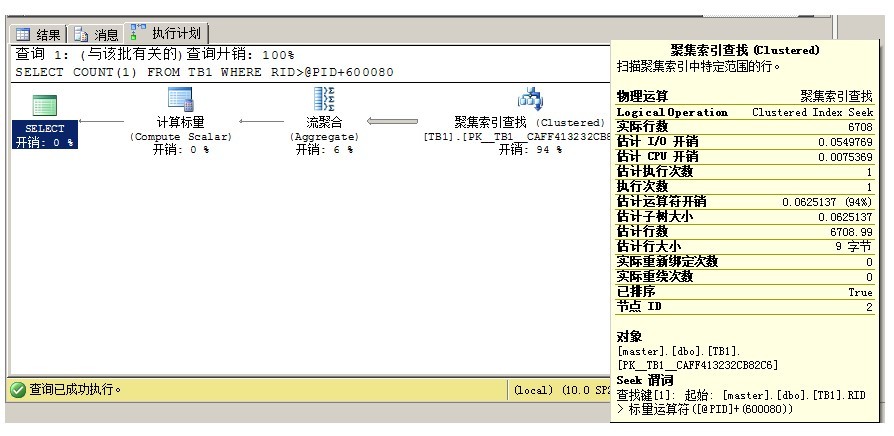
--测试在查询时对传入参数做运算
CREATE PROCEDURE dbo.USP_GetData3
(
@PID INT
)
AS
BEGIN
SELECT COUNT(1)
FROM TB1
WHERE RID>@PID+600080
END
GO
EXEC dbo.USP_GetData3 @PID=20
--=================================================
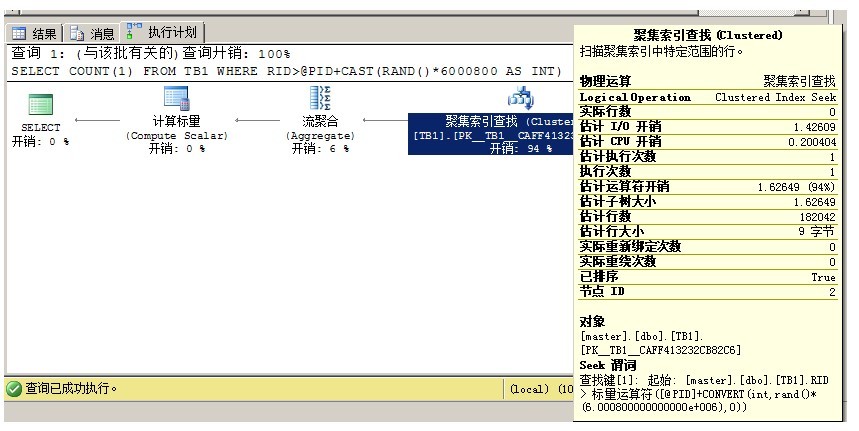
--测试在查询时对传入参数做运算(复杂运算)
----对应复杂运算,无法获得准确的值,因此不能准确地预估行数,也不能生成合理的执行计划
CREATE PROCEDURE dbo.USP_GetData4
(
@PID INT
)
AS
BEGIN
SELECT COUNT(1)
FROM TB1
WHERE RID>@PID+CAST(RAND()*6000800 AS INT)
END
GO
EXEC dbo.USP_GetData4 @PID=20
GO
总结:
在存储过程中使用到的变量可以分为内部变量和外部变量
1>对于外部变量,存储过程编译时会使用该变量的真实值依据统计来生成执行计划,无论该外部变量是否在存储过程中发生修改
2>对于内部变量,存储过程编译时无法获取该变量的真实值,因此无法使用统计,从而只能生成"最通用"的执行计划(可能是比较差的执行计划)
补充:
可以使用OPTION(optimize for(@PID=75124))方式来解决因变量值导致的执行计划不优的问题
执行计划--在存储过程中使用SET对执行计划的影响的更多相关文章
- oracle存储过程中使用execute immediate执行sql报ora-01031权限不足的问题
oracle存储过程中使用execute immediate执行sql报ora-01031权限不足的问题 学习了:http://blog.csdn.net/royzhang7/article/deta ...
- 存储过程中拼写sql并执行
直接上代码吧,根据不同的条件拼写sql后并执行 ALTER PROCEDURE [dbo].[usp_Statistic_WJB_DZSK_ZT] ( @year int, @half int,--0 ...
- 【oracle】存储过程中获取delete语句执行后删除的记录数
dbms_output.put_line(to_char(sql%rowcount));
- 存储过程中使用事务,sql server 事务,sql事务
一.存储过程中使用事务的简单语法 在存储过程中使用事务时非常重要的,使用数据可以保持数据的关联完整性,在Sql server存储过程中使用事务也很简单,用一个例子来说明它的语法格式: 代码 ...
- mysql-存储过程案例-存储过程中创建表和修改表数据
-- 本存储过程有特殊执行循环数量的要求,是对security_market_history表进行修正 -- 判断存储过程是否存在 drop PROCEDURE if exists proc_secu ...
- MySQL存储过程中的3种循环
在MySQL存储过程的语句中有三个标准的循环方式:WHILE循环,LOOP循环以及REPEAT循环.还有一种非标准的循环方式:GOTO,不过这种循环方式最好别用,很容易引起程序的混乱,在这里就不错具体 ...
- 存储过程中使用事务与try catch
一.存储过程中使用事务的简单语法 在存储过程中使用事务时非常重要的,使用数据可以保持数据的关联完整性,在Sql server存储过程中使用事务也很简单,用一个例子来说明它的语法格式: 代码 : ) ) ...
- MySQL存储过程中的3种循环【转载】
在MySQL存储过程的语句中有三个标准的循环方式:WHILE循环,LOOP循环以及REPEAT循环.还有一种非标准的循环方式:GOTO,不过这种循环方式最好别用,很容易引起程序的混乱,在这里就不错具体 ...
- 存储过程中使用事务和try catch
一.存储过程中使用事务的简单语法 在存储过程中使用事务时非常重要的,使用数据可以保持数据的关联完整性,在Sql server存储过程中使用事务也很简单,用一个例子来说明它的语法格式: 代码 : Cre ...
随机推荐
- 给iOS开发新手送点福利,简述UITextField的属性和用法
UITextField属性 0. enablesReturnKeyAutomatically 默认为No,如果设置为Yes,文本框中没有输入任何字符的话,右下角的返回按钮是disabled的. ...
- 常见的JS和CSS问题
事件冒泡 DOM的事件冒泡机制和WPF很相似,DOM事件机制包含冒泡和捕获两种,按照topmost element->innermost element方向传递事件被称为捕获方式,而从inner ...
- fadora24安装settools,pip包出错解决方法
1.fadora24安装Python2.7 [root@dev ~]# python bash: python: 未找到命令... 安装软件包“python”以提供命令“python”? [N/y] ...
- jquery的html代码中a的onclick的正确显示的代码
jquery的html代码中a的onclick的正确显示的代码 需要转义一下,试了好久才试出来 img_delete.html('<a onclick="deleteImg(\''+s ...
- 二维码名片的格式 - vcard(非常好,可直接添加到手机通讯录)
分享到 一键分享 QQ空间 新浪微博 百度云收藏 人人网 腾讯微博 百度相册 开心网 腾讯朋友 百度贴吧 豆瓣网 搜狐微博 百度新首页 QQ好友 和讯微博 更多... 百度分享 登录|注册 ...
- 33.使用默认的execAndWait拦截器
转自:https://wenku.baidu.com/view/84fa86ae360cba1aa911da02.html 当我们进行数据库查询等相关的操作时,如果服务器负荷过重可能不能及时把数据查询 ...
- JAXB--@XmlElementWrapper注解(二)
在JAXB标准中,@XmlElementWrapper注解表示生成一个包装 XML 表示形式的包装器元素. 此元素主要用于生成一个包装集合的包装器 XML 元素.因此,该注释支持以下两种形式的序列化. ...
- 为什么数组没有实现Iterable接口,但可以使用foreach语句遍历
在Java中,对于数组为什么能够使用foreach语句一直感觉很困惑. 对于能够使用foreach语句进行遍历的对象,只有两种情况,其中一种是遍历对象必须实现Iterable接口,实现ierator( ...
- C#中释放数据库连接资源
1.确保释放数据库连接资源的两种方式如下: a.使用try...catch...finally语句块,在finally块中关闭连接: b.使用using语句块,无论如何退出,都会自动关闭连接: ...
- 第七章 资源在Windows编程中的应用 P157 7-8
资源在基于SDK的程序设计中的应用实验 一.实验目的 1.掌握各种资源的应用及资源应用的程序设计方法. 二.实验内容及步骤 实验任务 1.熟悉菜单资源的创建过程: 2.熟悉位图资源的创建: 3.熟 ...