Cublas矩阵加速运算
前言
编写 CUDA 程序真心不是个简单的事儿,调试也不方便,很费时。那么有没有一些现成的 CUDA 库来调用呢?
答案是有的,如 CUBLAS 就是 CUDA 专门用来解决线性代数运算的库。
本文将大致介绍如何使用 CUBLAS 库,同时演示一个使用 CUBLAS 库进行矩阵乘法的例子。
CUBLAS 内容
CUBLAS 是 CUDA 专门用来解决线性代数运算的库,它分为三个级别:
Lev1. 向量相乘
Lev2. 矩阵乘向量
Lev3. 矩阵乘矩阵
同时该库还包含状态结构和一些功能函数。
CUBLAS 用法
大体分成以下几个步骤:
1. 定义 CUBLAS 库对象
2. 在显存中为待运算的数据以及需要存放结果的变量开辟显存空间。( cudaMalloc 函数实现 )
3. 将待运算的数据传输进显存。( cudaMemcpy,cublasSetVector 等函数实现 )
3. 调用 CUBLAS 库函数 ( 根据 CUBLAS 手册调用需要的函数 )
4. 从显存中获取结果变量。( cudaMemcpy,cublasGetVector 等函数实现 )
5. 释放申请的显存空间以及 CUBLAS 库对象。( cudaFree 及 cublasDestroy 函数实现 )
代码示例
如下程序使用 CUBLAS 库进行矩阵乘法运算,请仔细阅读注释,尤其是 API 的参数说明:

1 // CUDA runtime 库 + CUBLAS 库
2 #include "cuda_runtime.h"
3 #include "cublas_v2.h"
4
5 #include <time.h>
6 #include <iostream>
7
8 using namespace std;
9
10 // 定义测试矩阵的维度
11 int const M = 5;
12 int const N = 10;
13
14 int main()
15 {
16 // 定义状态变量
17 cublasStatus_t status;
18
19 // 在 内存 中为将要计算的矩阵开辟空间
20 float *h_A = (float*)malloc (N*M*sizeof(float));
21 float *h_B = (float*)malloc (N*M*sizeof(float));
22
23 // 在 内存 中为将要存放运算结果的矩阵开辟空间
24 float *h_C = (float*)malloc (M*M*sizeof(float));
25
26 // 为待运算矩阵的元素赋予 0-10 范围内的随机数
27 for (int i=0; i<N*M; i++) {
28 h_A[i] = (float)(rand()%10+1);
29 h_B[i] = (float)(rand()%10+1);
30
31 }
32
33 // 打印待测试的矩阵
34 cout << "矩阵 A :" << endl;
35 for (int i=0; i<N*M; i++){
36 cout << h_A[i] << " ";
37 if ((i+1)%N == 0) cout << endl;
38 }
39 cout << endl;
40 cout << "矩阵 B :" << endl;
41 for (int i=0; i<N*M; i++){
42 cout << h_B[i] << " ";
43 if ((i+1)%M == 0) cout << endl;
44 }
45 cout << endl;
46
47 /*
48 ** GPU 计算矩阵相乘
49 */
50
51 // 创建并初始化 CUBLAS 库对象
52 cublasHandle_t handle;
53 status = cublasCreate(&handle);
54
55 if (status != CUBLAS_STATUS_SUCCESS)
56 {
57 if (status == CUBLAS_STATUS_NOT_INITIALIZED) {
58 cout << "CUBLAS 对象实例化出错" << endl;
59 }
60 getchar ();
61 return EXIT_FAILURE;
62 }
63
64 float *d_A, *d_B, *d_C;
65 // 在 显存 中为将要计算的矩阵开辟空间
66 cudaMalloc (
67 (void**)&d_A, // 指向开辟的空间的指针
68 N*M * sizeof(float) // 需要开辟空间的字节数
69 );
70 cudaMalloc (
71 (void**)&d_B,
72 N*M * sizeof(float)
73 );
74
75 // 在 显存 中为将要存放运算结果的矩阵开辟空间
76 cudaMalloc (
77 (void**)&d_C,
78 M*M * sizeof(float)
79 );
80
81 // 将矩阵数据传递进 显存 中已经开辟好了的空间
82 cublasSetVector (
83 N*M, // 要存入显存的元素个数
84 sizeof(float), // 每个元素大小
85 h_A, // 主机端起始地址
86 1, // 连续元素之间的存储间隔
87 d_A, // GPU 端起始地址
88 1 // 连续元素之间的存储间隔
89 );
90 cublasSetVector (
91 N*M,
92 sizeof(float),
93 h_B,
94 1,
95 d_B,
96 1
97 );
98
99 // 同步函数
100 cudaThreadSynchronize();
101
102 // 传递进矩阵相乘函数中的参数,具体含义请参考函数手册。
103 float a=1; float b=0;
104 // 矩阵相乘。该函数必然将数组解析成列优先数组
105 cublasSgemm (
106 handle, // blas 库对象
107 CUBLAS_OP_T, // 矩阵 A 属性参数
108 CUBLAS_OP_T, // 矩阵 B 属性参数
109 M, // A, C 的行数
110 M, // B, C 的列数
111 N, // A 的列数和 B 的行数
112 &a, // 运算式的 α 值
113 d_A, // A 在显存中的地址
114 N, // lda
115 d_B, // B 在显存中的地址
116 M, // ldb
117 &b, // 运算式的 β 值
118 d_C, // C 在显存中的地址(结果矩阵)
119 M // ldc
120 );
121
122 // 同步函数
123 cudaThreadSynchronize();
124
125 // 从 显存 中取出运算结果至 内存中去
126 cublasGetVector (
127 M*M, // 要取出元素的个数
128 sizeof(float), // 每个元素大小
129 d_C, // GPU 端起始地址
130 1, // 连续元素之间的存储间隔
131 h_C, // 主机端起始地址
132 1 // 连续元素之间的存储间隔
133 );
134
135 // 打印运算结果
136 cout << "计算结果的转置 ( (A*B)的转置 ):" << endl;
137
138 for (int i=0;i<M*M; i++){
139 cout << h_C[i] << " ";
140 if ((i+1)%M == 0) cout << endl;
141 }
142
143 // 清理掉使用过的内存
144 free (h_A);
145 free (h_B);
146 free (h_C);
147 cudaFree (d_A);
148 cudaFree (d_B);
149 cudaFree (d_C);
150
151 // 释放 CUBLAS 库对象
152 cublasDestroy (handle);
153
154 getchar();
155
156 return 0;
157 }
运行测试
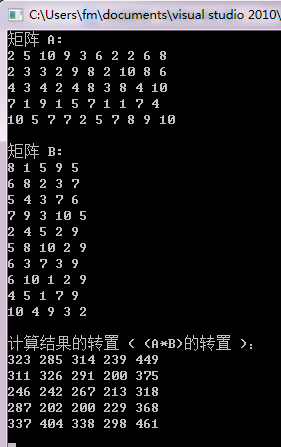
PS:矩阵元素是随机生成的
小结
1. 使用 CUDA 库固然方便,但也要仔细的参阅函数手册,其中每个参数的含义都要很清晰才不容易出错。
2. 如果程序仅使用 CUDA 库的话,用 .cpp 源码文件即可 (不用 .cu)
Cublas矩阵加速运算的更多相关文章
- 斐波那契数列F(n)【n超大时的(矩阵加速运算) 模板】
hihocoder #1143 : 骨牌覆盖问题·一 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 骨牌,一种古老的玩具.今天我们要研究的是骨牌的覆盖问题: 我们有一个 ...
- Luogu P3390 【模板】矩阵快速幂&&P1939 【模板】矩阵加速(数列)
补一补之前的坑 因为上次关于矩阵的那篇blog写的内容太多太宽泛了,所以这次把一些板子和基本思路理一理 先看这道模板题:P3390 [模板]矩阵快速幂 首先我们知道矩阵乘法满足结合律而不满足交换律的一 ...
- matlab 中使用 GPU 加速运算
为了提高大规模数据处理的能力,matlab 的 GPU 并行计算,本质上是在 cuda 的基础上开发的 wrapper,也就是说 matlab 目前只支持 NVIDIA 的显卡. 1. GPU 硬件支 ...
- 洛谷P3502 [POI2010]CHO-Hamsters感想及题解(图论+字符串+矩阵加速$dp\&Floyd$)
洛谷P3502 [POI2010]CHO-Hamsters感想及题解(图论+字符串+矩阵加速\(dp\&Floyd\)) 标签:题解 阅读体验:https://zybuluo.com/Junl ...
- 快速电路仿真器(FastSPICE)中的高性能矩阵向量运算实现
今年10-11月份参加了EDA2020(第二届)集成电路EDA设计精英挑战赛,通过了初赛,并参加了总决赛,最后拿了一个三等奖,虽然成绩不是很好,但是想把自己做的分享一下,我所做的题目是概伦电子出的F题 ...
- 3D Cube计算引擎加速运算
3D Cube计算引擎加速运算 华为达芬奇架构的AI芯片Ascend910,同时与之配套的新一代AI开源计算框架MindSpore. 为什么要做达芬奇架构? AI将作为一项通用技术极大地提高生产力,改 ...
- C#的winform矩阵简单运算
C#的winform矩阵简单运算 程序截图 关键代码 using System; using System.Collections.Generic; using System.ComponentMod ...
- HDU 5564 Clarke and digits 状压dp+矩阵加速
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=5564 题意: 求长度在[L,R]范围,并且能整除7的整数的总数. 题解: 考虑最原始的想法: dp[ ...
- 【 CodeForces - 392C】 Yet Another Number Sequence (二项式展开+矩阵加速)
Yet Another Number Sequence Description Everyone knows what the Fibonacci sequence is. This sequence ...
随机推荐
- Ucinet6 + Netdraw 根据excel文件绘制网络拓扑图
条件: 具备Ucinet6 和 Netdraw 两款软件的Windows excel文件格式(.xlsx .xls .csv):必须是数字,如果现有的文件不是数字,可以采用某种编码的方式将其映射成 ...
- Windows10下安装Maven以及Eclipse安装Maven插件 + 创建Maven项目
在官网下载Maven http://maven.apache.org/download.cgi 下载下来后加压缩,将apache-maven-3.5.4文件夹复制到想要存放它的位置,我放在了 ...
- 算法进阶面试题02——BFPRT算法、找出最大/小的K个数、双向队列、生成窗口最大值数组、最大值减最小值小于或等于num的子数组数量、介绍单调栈结构(找出临近的最大数)
第二课主要介绍第一课余下的BFPRT算法和第二课部分内容 1.BFPRT算法详解与应用 找到第K小或者第K大的数. 普通做法:先通过堆排序然后取,是n*logn的代价. // O(N*logK) pu ...
- go语言学习-安装和配置
go的安装方式主要有两种,一种直接使用系统自带的软件源来安装,比如 ubuntu 可以直接使用 apt 安装,但通常这种方式安装的都不会是最新的.所以通常直接下载最新的安装包,可以到GoCN下载.下面 ...
- update date and keep time
select TO_CHAR((date '2010-01-02' + (sysdate-trunc(sysdate))),'YYYY-MM-DD HH:mi:ss') from dual;
- webpack的版本进化史
一.概述2015,webpack1支持CMD和AMD,同时拥有丰富的plugin和loader,webpack逐渐得到广泛应用. 2016.12,webpack2相对于webpack1最大的改进就是支 ...
- go协程使用陷阱(转)
协程中使用全局变量.局部变量.指针.map.切片等作为参数时需要注意,此变量的值变化问题. 与for 循环,搭配使用更需谨慎. 1,内置函数时直接使用局部变量,未进行参数传递 package main ...
- android sdk 汉化
作者:韩梦飞沙 Author:han_meng_fei_sha 邮箱:313134555@qq.com E-mail: 313134555 @qq.com === ===== ==== ==== == ...
- codeforces1027F. Session in BSU
题目链接 codeforces1027F. Session in BSU 题解 二分图匹配就fst了....显然是过去的,不过tle test87估计也pp了,好坑 那么对于上面做匹配的这个二分图分情 ...
- APIO2018 铜滚记
「一旦闭上双眼,就昏昏欲睡」「仿佛与这个世界的联系,被瞬间切断」「可是,负罪感与背德感又会在黑暗中将我吞噬」「即使这样,却也无法与身体的疲惫抗衡」 「如果,这些东西也无法让意识的存在稳定下来的话」「那 ...