mysql系列十三、mysql中replace into和duplicate key的使用区
一、创建测试表
1.创建唯一索引"b"
CREATE TABLE `test2` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`a` varchar(5) DEFAULT NULL,
`b` varchar(5) DEFAULT NULL,
`c` varchar(5) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_b` (`b`)
) ENGINE=InnoDB AUTO_INCREMENT=74 DEFAULT CHARSET=utf
2.插入3条数据
INSERT INTO test1(a,b,c) VALUE (1,2,3),(2,4,4),(2,3,5);
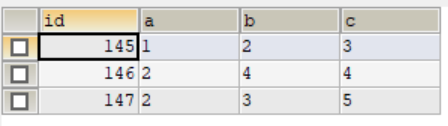
select * from tset2;
二、replace into用法
1.使用replace into插入单条数据
REPLACE INTO test2(b,c) VALUE (3,3);
2 row(s) affected
Execution Time : 00:00:00:047
Transfer Time : 00:00:00:000
Total Time : 00:00:00:047
INSERT INTO test2(a,b,c) VALUE (1,2,3),(2,4,4),(2,3,5);

1.当插入的值和唯一索引重复时,执行更新操作,相当于执行:
delete from where b=3;
inset into test2(b,2) value(3,3);
先删除该记录,再插入指定列,没有指定值的为默认值
注意该数据的id加1了,数据替换之后id加1了,此处有坑,如果此id是其他的表的外键,关联关系就对不上了。
2.当插入的值和唯一索引不重复时,执行插入操作,相当于执行:
inset into test2(b,2) value(3,3);
2.使用replace into批量插入数据
INSERT INTO test2(a,b,c) VALUE (1,2,3),(2,4,4),(2,3,5);
三、DUPLICATE KEY UPDATE用法
1.插入重复单条数据
1.当唯一index重复时,直接更新update 后面的字段
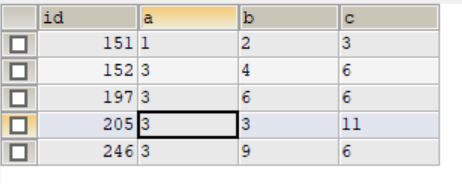
INSERT INTO test2(a,b,c) VALUE (3,3,11) ON DUPLICATE KEY UPDATE a=VALUES(a),c=VALUES(c);
2 row(s) affected
Execution Time : 00:00:01:250
Transfer Time : 00:00:00:000
Total Time : 00:00:01:250
INSERT INTO test2(a,b,c) VALUE (1,3,13) ON DUPLICATE KEY UPDATE c=VALUES(c);
2 row(s) affected
Execution Time : 00:00:00:062
Transfer Time : 00:00:00:000
Total Time : 00:00:00:062

两条sql的区别在于后条语句更新了两个值,而前一条更新了一个值
更新指定值需要在update后面指定。
两条sql分别相当于执行了:
update test2 set a=3,c=13 where b=3; update test2 set c=13 where b=3;
2.插入不重复的值
INSERT INTO test2(a,b,c) VALUE (1,5,13) ON DUPLICATE KEY UPDATE c=VALUES(c);
1 row(s) affected
Execution Time : 00:00:00:031
Transfer Time : 00:00:00:000
Total Time : 00:00:00:031
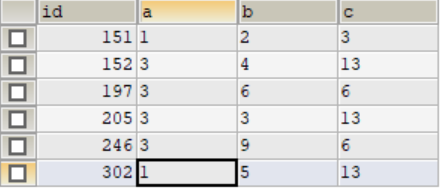
三个值全部插入了,相当于执行了:
insert into test(a,b,c) value (,5,13)
id已经不连续了,说明每次unique index重复时,该表的id也会自增
2.批量插入用法
INSERT INTO test2(a,b,c) VALUE (1,5,14),(1,6,13),(1,7,13) ON DUPLICATE KEY UPDATE a=VALUES(a),c=VALUES(c);
四、两者之间的区别
1.unique index重复插入时
a.单条数据受影响的行都是2;
b.replace 之后原来的数据更新之后会id+1,指定的值会更新,没有指定的,会更新为默认值;
c.uplicate key只会更新指定的值,没有指定的值跟原数据保持一致;
2.unique index不重复时
a.都相当于插入了新记录。
mysql系列十三、mysql中replace into和duplicate key的使用区的更多相关文章
- mysql插入数据时 insert IGNORE、ON DUPLICATE KEY UPDATE、replace into
转: mysql insert时几个操作DELAYED .IGNORE.ON DUPLICATE KEY UPDATE的区别 博客分类: mysql基础应用 mysql insert时几个操作DE ...
- 重重封锁,让你一条数据都拿不到《死磕MySQL系列 十三》
在开发中有遇到很简单的SQL却执行的非常慢,甚至只查询一行数据. 咔咔遇到的只有两种情况,一种是MySQL服务器CPU占用率很高,所有的SQL都执行的很慢直到超时,程序也直接502,另一种情况是行锁造 ...
- MYSQL的REPLACE和ON DUPLICATE KEY UPDATE使用
REPLACE 我们在使用数据库时可能会经常遇到这种情况.如果一个表在一个字段上建立了唯一索引,当我们再向这个表中使用已经存在的键值插入一条记录,那将会抛出一个主键冲突的错误.当然,我们可能想用新记录 ...
- Mysql系列二:Mysql 开发标准规范
原文链接:http://www.cnblogs.com/liulei-LL/p/7729983.html 一.表设计 1. 库名.表名.字段名使用小写字母,“_”分割. 2. 库名.表名.字段名不超过 ...
- mysql使用replace和on duplicate key update区别
实际业务使用中,有时候会遇到插入数据库,但是如果某个属性(比如:主键)存在,就做更新.通常有两种方式:1.replace into 2.on duplicate key update 但是在使用过程 ...
- 关于mysql中unique的插入Duplicate key
MySQL数据库中 如果在后台中不做判断是否unique的column是否存在的话,直接把数据操作给dao层再传给DB的话,就会报重复的唯一值.如果确实是不希望先取出判断unique的column是否 ...
- MySQL系列(二)--MySQL存储引擎
影响数据库性能的因素: 1.硬件环境:CPU.内存.存盘IO.网卡流量等 2.存储引擎的选择 3.数据库参数配置(影响最大) 4.数据库结构设计和SQL语句 MySQL采用插件式存储引擎,可以自行选择 ...
- MySQL系列:MySQL的基本使用
数据库的基本操作 在MySQL数据库中,对于一个MySQL示例,是可以包含多个数据库的. 在连接MySQL后,我们可以通过 show databases; 来进行查看有那么数据库.这里已经存在一些库了 ...
- 【MySql系列】MySql踩坑系列
问题一:远程登录报错Host '192.168.181.201' is not allowed to connect to this MySQL server 解决: 问题二:MySql access ...
随机推荐
- ThinkPHP5 隐藏index.php问题
隐藏index.php 可以去掉URL地址里面的入口文件index.php,但是需要额外配置WEB服务器的重写规则. 以Apache为例,需要在入口文件的同级添加.htaccess文件(官方默认自带了 ...
- C# 随机四位数验证码
string str ="abcdefghigklmnopqrstuvwxyzABCDEFJHIGKLMNOPQRSTUVWXYZ1234567890"; while(true){ ...
- Spring的后置处理器BeanFactoryPostProcessor
新建一个JavaBean UserBeanFactoryPostProcessor 实现了BeanFactoryPostProcessor接口 Spring配置文件如下: 编写测试用例 从结果可以看出 ...
- A1039. Course List for Student
Zhejiang University has 40000 students and provides 2500 courses. Now given the student name lists o ...
- springboot集成mybatis-generator时候遇到的问题
今天在集成mybatis自动生成内容的时候,出现了几个问题,解决了一个小时才搞完,都怪之前没有好好研究研究: 1.mysql-connector-java新驱动带来的问题? 当用比较新的sql驱动的时 ...
- 51job_selenium测试2
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- 虚拟化技术之KVM
虚拟化技术之KVM 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.什么是虚拟化 其实虚拟化技术已经不是一个新技术了,上个世纪六十年代IBM公司已经在使用,只不过后来(上个世纪八 ...
- kafka channle的应用案例
kafka channle的应用案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 最近在新公司负责大数据平台的建设,平台搭建完毕后,需要将云平台(我们公司使用的Ucloud的 ...
- 网络地址转换-NAT
网络地址转换-NAT 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NAT组网和常用术语 私网:局域网内IP 公网:因特网的公网ip地址 NAT设备:就是讲私网地址转换为公网的 ...
- spring web.xml 难点配置总结【转】
web.xml web.xml是所有web项目的根源,没有它,任何web项目都启动不了,所以有必要了解相关的配置. ContextLoderListener,ContextLoaderServlet, ...