【分库、分表】MySQL分库分表方案
一、Mysql分库分表方案
1.为什么要分表:
当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。
mysql中有一种机制是表锁定和行锁定,是为了保证数据的完整性。表锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等我对这条数据操作完了,才能对这条数据进行操作。
2. mysql proxy:amoeba
做mysql集群,利用amoeba。
从上层的java程序来讲,不需要知道主服务器和从服务器的来源,即主从数据库服务器对于上层来讲是透明的。可以通过amoeba来配置。
3.大数据量并且访问频繁的表,将其分为若干个表
比如对于某网站平台的数据库表-公司表,数据量很大,这种能预估出来的大数据量表,我们就事先分出个N个表,这个N是多少,根据实际情况而定。
某网站现在的数据量至多是5000万条,可以设计每张表容纳的数据量是500万条,也就是拆分成10张表,
那么如何判断某张表的数据是否容量已满呢?可以在程序段对于要新增数据的表,在插入前先做统计表记录数量的操作,当<500万条数据,就直接插入,当已经到达阀值,可以在程序段新创建数据库表(或者已经事先创建好),再执行插入操作。
4. 利用merge存储引擎来实现分表
如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了。用merge存储引擎来实现分表, 这种方法比较适合.
举例子:
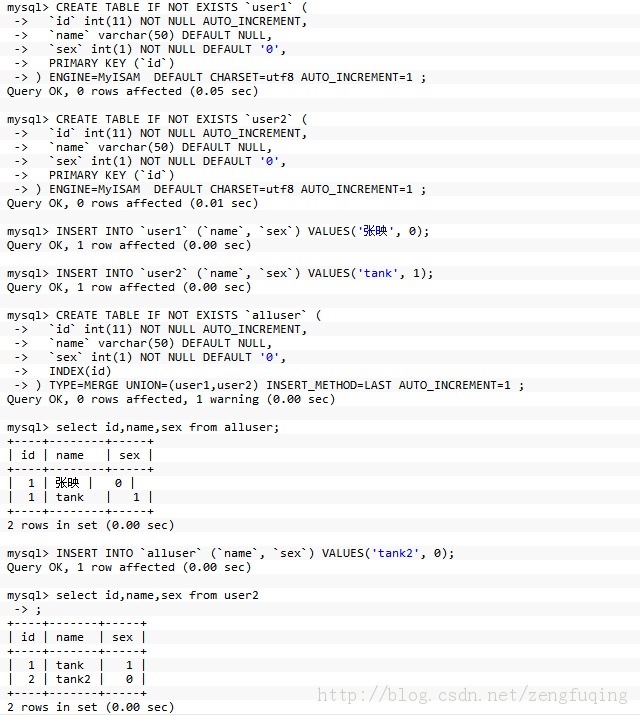
二、数据库架构
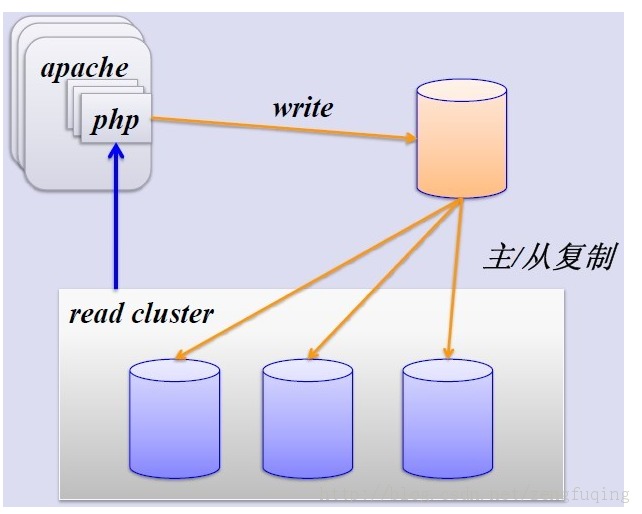
1、简单的MySQL主从复制:
MySQL的主从复制解决了数据库的读写分离,并很好的提升了读的性能,其图如下:
其主从复制的过程如下图所示:
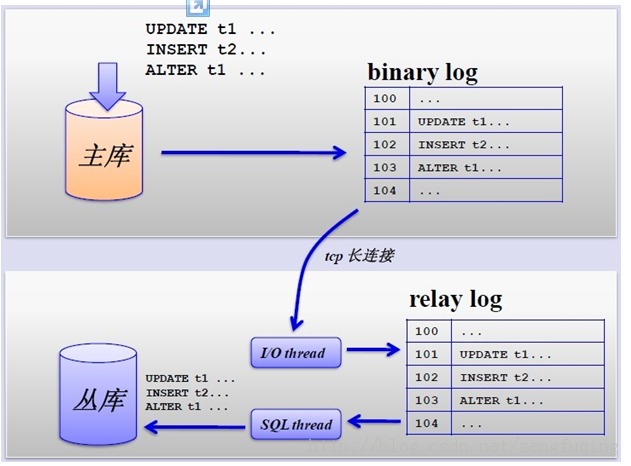
但是,主从复制也带来其他一系列性能瓶颈问题:
- 写入无法扩展
- 写入无法缓存
- 复制延时
- 锁表率上升
- 表变大,缓存率下降
那问题产生总得解决的,这就产生下面的优化方案,一起来看看。
2、MySQL垂直分区
如果把业务切割得足够独立,那把不同业务的数据放到不同的数据库服务器将是一个不错的方案,而且万一其中一个业务崩溃了也不会影响其他业务的正常进行,并且也起到了负载分流的作用,大大提升了数据库的吞吐能力。经过垂直分区后的数据库架构图如下:
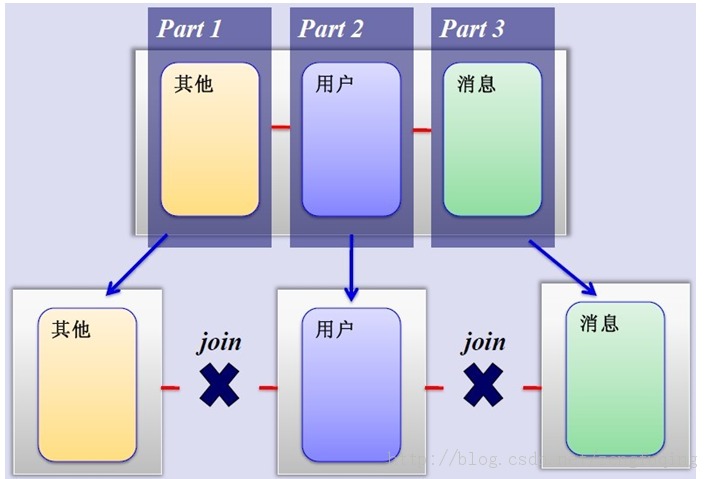
然而,尽管业务之间已经足够独立了,但是有些业务之间或多或少总会有点联系,如用户,基本上都会和每个业务相关联,况且这种分区方式,也不能解决单张表数据量暴涨的问题,因此为何不试试水平分割呢?
3、MySQL水平分片(Sharding)
这是一个非常好的思路,将用户按一定规则(按id哈希)分组,并把该组用户的数据存储到一个数据库分片中,即一个sharding,这样随着用户数量的增加,只要简单地配置一台服务器即可,原理图如下:
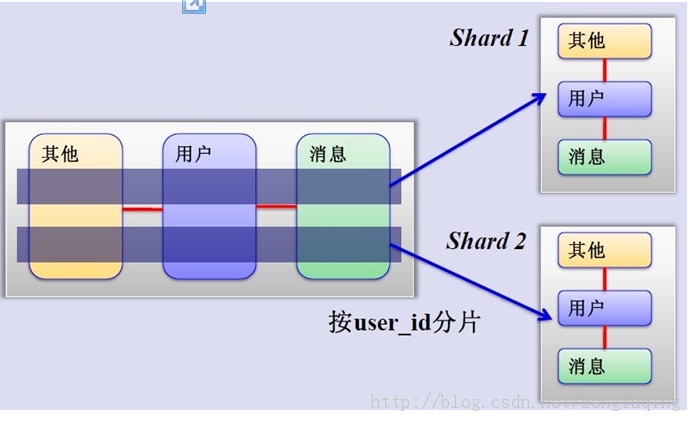
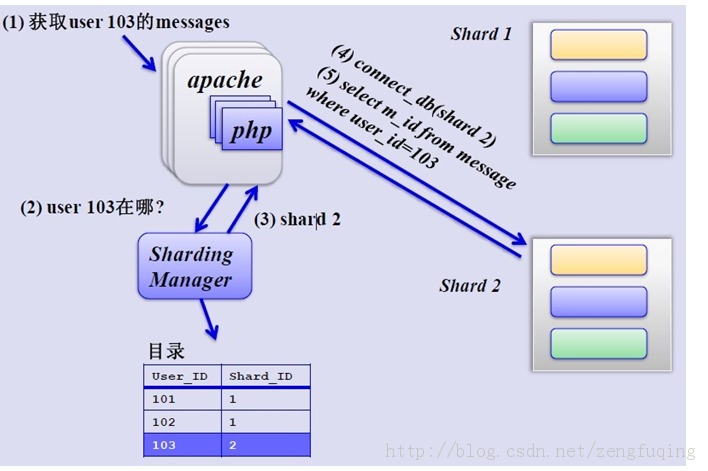
如何来确定某个用户所在的shard呢,可以建一张用户和shard对应的数据表,每次请求先从这张表找用户的shard id,再从对应shard中查询相关数据,如下图所示:
①单库单表
单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到。
②单库多表
随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能。如果使用mysql, 还有一个更严重的问题是,当需要添加一列的时候,mysql会锁表,期间所有的读写操作只能等待。
可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的user_0000,user_0001等表,user_0000 + user_0001 + …的数据刚好是一份完整的数据。
③多库多表
随着数据量增加也许单台DB的存储空间不够,随着查询量的增加单台数据库服务器已经没办法支撑。这个时候可以再对数据库进行水平区分。
四、分库分表规则
设计表的时候需要确定此表按照什么样的规则进行分库分表。例如,当有新用户时,程序得确定将此用户信息添加到哪个表中;同理,当登录的时候我们得通过用户的账号找到数据库中对应的记录,所有的这些都需要按照某一规则进行。
路由
通过分库分表规则查找到对应的表和库的过程。如分库分表的规则是user_id mod 4的方式,当用户新注册了一个账号,账号id的123,我们可以通过id mod 4的方式确定此账号应该保存到User_0003表中。当用户123登录的时候,我们通过123 mod 4后确定记录在User_0003中。
分库分表产生的问题,及注意事项
1. 分库分表维度的问题
假如用户购买了商品,需要将交易记录保存取来,如果按照用户的纬度分表,则每个用户的交易记录都保存在同一表中,所以很快很方便的查找到某用户的 购买情况,但是某商品被购买的情况则很有可能分布在多张表中,查找起来比较麻烦。反之,按照商品维度分表,可以很方便的查找到此商品的购买情况,但要查找 到买人的交易记录比较麻烦。
所以常见的解决方式有:
- 通过扫表的方式解决,此方法基本不可能,效率太低了。
- 记录两份数据,一份按照用户纬度分表,一份按照商品维度分表。
- 通过搜索引擎解决,但如果实时性要求很高,又得关系到实时搜索。
2. 联合查询的问题
联合查询基本不可能,因为关联的表有可能不在同一数据库中。
3. 避免跨库事务
避免在一个事务中修改db0中的表的时候同时修改db1中的表,一个是操作起来更复杂,效率也会有一定影响。
4. 尽量把同一组数据放到同一DB服务器上
例如将卖家a的商品和交易信息都放到db0中,当db1挂了的时候,卖家a相关的东西可以正常使用。也就是说避免数据库中的数据依赖另一数据库中的数据。
5.一主多备
在实际的应用中,绝大部分情况都是读远大于写。Mysql提供了读写分离的机制,所有的写操作都必须对应到Master,读操作可以在 Master和Slave机器上进行,Slave与Master的结构完全一样,一个Master可以有多个Slave,甚至Slave下还可以挂 Slave,通过此方式可以有效的提高DB集群的 QPS.
所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
此外,可以看出Master是集群的瓶颈,当写操作过多,会严重影响到Master的稳定性,如果Master挂掉,整个集群都将不能正常工作。
所以
- 当读压力很大的时候,可以考虑添加Slave机器的分式解决,但是当Slave机器达到一定的数量就得考虑分库了。
- 当写压力很大的时候,就必须得进行分库操作。
五、MySQL使用为什么要分库分表
可以用说用到MySQL的地方,只要数据量一大, 马上就会遇到一个问题,要分库分表. 这里引用一个问题为什么要分库分表呢?MySQL处理不了大的表吗? 其实是可以处理的大表的.我所经历的项目中单表物理上文件大小在80G多,单表记录数在5亿以上,而且这个表 属于一个非常核用的表:朋友关系表.
但这种方式可以说不是一个最佳方式. 因为面临文件系统如Ext3文件系统对大于大文件处理上也有许多问题. 这个层面可以用xfs文件系统进行替换.但MySQL单表太大后有一个问题是不好解决: 表结构调整相关的操作基
本不在可能.所以大项在使用中都会面监着分库分表的应用.
从Innodb本身来讲数据文件的Btree上只有两个锁, 叶子节点锁和子节点锁,可以想而知道,当发生页拆分或是添加新叶时都会造成表里不能写入数据.所以分库分表还就是一个比较好的选择了.
那么分库分表多少合适呢?
经测试在单表1000万条记录一下,写入读取性能是比较好的. 这样在留点buffer,那么单表全是数据字型的保持在800万条记录以下, 有字符型的单表保持在500万以下.
如果按 100库100表来规划,如用户业务: 500万*100*100 = 50000000万 = 5000亿记录.
心里有一个数了,按业务做规划还是比较容易的.
分布式数据库架构--排序、分页、分组、实现
六、最近研究分布式数据库架构,发现排序、分组及分页让着实人有点头疼。现把问题及解决思路整理如下。
1.多分片(水平切分)返回结果合并(排序)
①Select + None Aggregate Function的有序记录合并排序
解决思路:对各分片返回的有序记录,进行排序去重合并。此处主要是编写排序去重合并算法。
②Select + None Aggregate Function的无序记录合并
解决思路:对各分片返回的无序记录,进行去重合并。
- 优点:实现比较简单。
- 缺点:数据量越大,字段越多,去重处理就会越耗时。
③Select + Aggregate Function的记录合并(排序)Oracle常用聚合函数:Count、Max、Min、Avg、Sum。
- AF:Max、Min
- 思路:通过算法对各分片返回结果再求max、min值。
- AF:Avg、Sum、Count
- 思路:分片间无重复记录或字段时,通过算法对各分片返回结果再求avg、sum、count值。分片间有重复记录或字段时,先对各分片记录去重合并,再通过算法求avg、sum、count值。
比如:
select count(*) from user select count(deptno) from user; select count(distinct deptno) from user;
2.多分片(水平切分)返回结果分页
解决思路:合并各分片返回结果,逻辑分页。
优点: 实现简单。
缺点: 数据量越大,缓存压力就越大。
分片数据量越大,查询也会越慢。
3.多分片(水平切分)查询有分组语法的合并
①Group By Having + None Aggregate Function时
- Select + None Aggregate Function
- 比如:select job user group by job;
- 思路:直接去重(排序)合并。
- Select + Aggregate Function
- 比如:select max(sal),job user group by job;
- 思路:同Select + Aggregate Function的记录合并(排序)。
②Group By Having + Aggregate Function时
解决思路:去掉having AF条件查询各分片,然后把数据放到一张表里。再用group by having 聚合函数查询。
4.分布式数据库架构--排序分组分页参考解决方案
- 解决方案1:Hadoop + Hive。
- 思路:使用Hadoop HDFS来存储数据,通过Hdoop MapReduce完成数据计算,通过Hive HQL语言使用部分与RDBBS一样的表格查询特性和分布式存储计算特性。
- 优点:
- 可以解决问题
- 具有并发处理能力
- 可以离线处理
- 缺点:
- 实时性不能保证
- 网络延迟会增加
- 异常捕获难度增加
- Web应用起来比较复杂
- 解决方案2:总库集中查询。
- 优点:
- 可以解决问题
- 实现简单
- 缺点:
- 总库数据不能太大
- 并发压力大
5.小结
对 于分布式数据库架构来说,排序、分页、分组一直就是一个比较复杂的问题。避免此问题需要好好地设计分库、分表策略。同时根据特定的场景来解决问题。也可以 充分利用海量数据存储(Hadoop-HDFS|Hive|HBse)、搜索引擎(Lucene|Solr)及分布式计算(MapReduce)等技术来 解决问题。
别外,也可以用NoSQL技术替代关系性数据库来解决问题,比如MogonDB\redis。
【分库、分表】MySQL分库分表方案的更多相关文章
- Mysql复制一条或多条记录并插入表|mysql从某表复制一条记录到另一张表
Mysql复制一条或多条记录并插入表|mysql从某表复制一条记录到另一张表 一.复制表里面的一条记录并插入表里面 ① insert into article(title,keywords,de ...
- Mycat(4):消息表mysql数据库分表实践
本文的原文连接是: http://blog.csdn.net/freewebsys/article/details/46882777 未经博主同意不得转载. 1,业务需求 比方一个社交软件,比方像腾讯 ...
- 写给 Poppy 的 MySQL 速查表
昨天 Poppy 问我是不是应该学一些网页开发的东西, 我的回答是这样的: 今天花了点时间汇总了一些 MySQL 简单的命令. ======== 正文分割线 ======== 有哪些常见的数据库: O ...
- MySQL常用系统表汇总
在这篇文章中: MySQL5.7 默认模式 Information_schema performance_schema mysql sys MYSQL SHOW 命令 致谢 概述 本篇文章虽大部分内容 ...
- Mysql分库分表方案
Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. m ...
- mysql 分库分表 ~ 方案选择浅谈
一 简介:分库分表的理解二 具体: 1 当由于单台DB业务增长导致的服务器压力时,就必须横向进行扩展 2 本文仅从中间层观点进行分析三 现有方案 方案1 sharding家 ...
- MySQL创建表,更新表,删除表,重命名表
创建表 mysql> create table 表名( -> 列名 数据类型 是否为空 auto_increment, -> 列名 数据类型 是否为空... -> ... -& ...
- MySQL 分库分表方案,总结的非常好!
前言 公司最近在搞服务分离,数据切分方面的东西,因为单张包裹表的数据量实在是太大,并且还在以每天60W的量增长. 之前了解过数据库的分库分表,读过几篇博文,但就只知道个模糊概念, 而且现在回想起来什么 ...
- Mysql 分库分表方案
0 引言 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. mysql中有一种机制是表锁定和行锁 ...
随机推荐
- anacoda 安装默认源中没有的包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 1 安装失败 conda install pygame 2 搜索 anaconda se ...
- Metasploit渗透技巧:后渗透Meterpreter代理
Metasploit是一个免费的.可下载的渗透测试框架,通过它可以很容易地获取.开发并对计算机软件漏洞实施攻击测试.它本身附带数百个已知软件漏洞的专业级漏洞攻击测试工具. 当H.D. Moore在20 ...
- github常见错误提示之一
如果输入$ Git remote add origin git@github.com:Jomsou(github帐号名)/gitdemo(项目名).git 提示出错信息:fatal: remote o ...
- pycharm python3.5 神奇的导入问题
说明:pycharm目录中没有同名.py文件,则可以直接用import util导入: 若有同名.py文件,则导入的时候需要加入所在文件夹名称
- Windows10上安装Keras 和 TensorFlow-GPU
安装环境: Windows 10 64bit GPU: GeForce gt 720 Python: 3.5.3 CUDA: 8 首先下载Anaconda3的Win10 64bit版,安装Python ...
- 设计模式之Memento(备忘机制)(转)
Memento定义: memento是一个保存另外一个对象内部状态拷贝的对象.这样以后就可以将该对象恢复到原先保存的状态. Memento模式相对也比较好理解,我们看下列代码: public clas ...
- Ant打包可运行的Jar包(加入第三方jar包)
本章介绍使用ant打包可运行的Jar包. 打包jar包最大的问题在于如何加入第三方jar包使得jar文件可以直接运行.以下用一个实例程序进行说明. 程序结构: 关键代码: package com.al ...
- ClassOne__HomeWork
1,static类型 static类型定义有两类,一类是静态数据,另一类是静态函数. 静态数据跟成员变量不同,它可以通过类名直接访问,而不需要通过定义对象来访问.它的的生成也和成员变量不一样,它只生成 ...
- 自学Java第七周的总结
这一周里我将看过的知识点又复习了一遍,下个星期打算将题做一遍
- 怎样从外网访问内网MongoDB数据库?
本地安装了一个MongoDB数据库,只能在局域网内访问到,怎样从外网也能访问到本地的MongoDB数据库呢?本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动MongoDB数据库 默认安装 ...