使用node.js进行API自动化回归测试
概述
原理
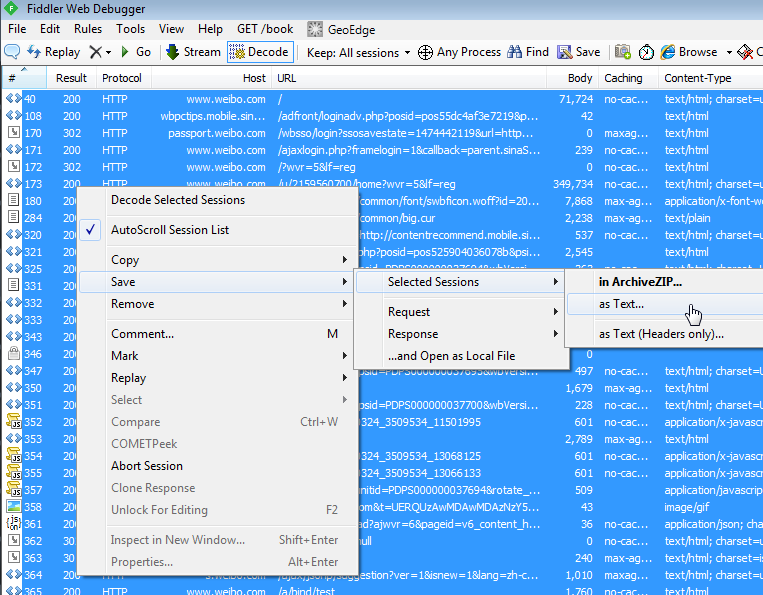
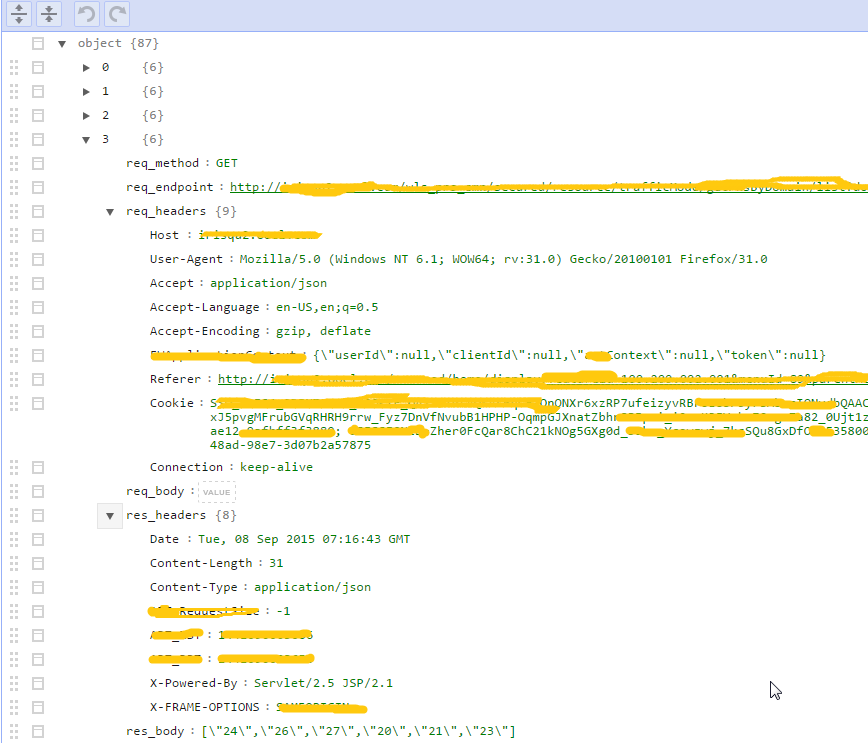
{
req_method: '',
req_endpoint: '',
req_headers: {},
req_body: '',
res_headers: {},
res_body: ''
}
superagent.get(‘www.baidu.com’).redirects(0)
如果要测试的系统都是HTTPS,需要取得信任证书,并导出来(浏览器登录https的时候会要求接受证书,这个过程中可以导出来),以备模拟登录时使用。superagent使用证书简单示例,假设已准备好的证书文件为abc.pem:
process.env.NODE_TLS_REJECT_UNAUTHORIZED = '0';
var cert = fs.readFileSync(__dirname + '/abc.pem');
superagent.get('https://abc.com')
.ca(cert)
.end(function(err, res) {...});
注意node.js里面一定要设置 process.env.NODE_TLS_REJECT_UNAUTHORIZED = '0'; 才能成功。
function request(httpReq, testData) { //httpReq代表一个http; testData主要是设置对http response进行校验的黑白名单等等
return new Promise(function(resolve) {
var assert = require('./assertion.js').assert, //引入自己开发的assertion模块对http reponse进行校验
endpoint = httpReq.req_endpoint,
req_method = httpReq.req_method.toLowerCase(),
req_headers = httpReq.req_headers,
req_body = httpReq.req_body;
superagent[req_method](endpoint)
.set(req_headers)
.send(req_body)
.timeout(10000)
.end(function(err, res) {
var result = assert(httpReq, res, testData);
resolve(result);
});
});
}
var superagent = require('superagent');
function execute(httj, testData) { //httj是所有解析出来的http对象集合; testData是为需要的http设置的黑白名单等校验条件
var failureCount = 0,
logs = [];
if (testData.serial) { //串行
var p = Promise.resolve();
for (var key in httj) {
void function(k) {
p = p.then(function(result) {
log(result);
return request(httj[k], testData); //request函数简单包装了superagent执行HTTP的方法,见上一段示例代码
});
}(key);
}
p.then(function(result) {
log(result);
});
} else { //并行
var allWS = [];
for (key in httj) {
allWS.push(request(httj[key], testData));
}
p = Promise
.all(allWS)
.then(function(arr) {
for (var result of arr) {
log(result);
}
});
}
return p.then(function() {
var isPassed, report;
failureCount === 0 ? isPassed = true : isPassed = false;
report = logs.sort().join('');
return { //生成最终测试结果
isPassed,
report
};
});
function log(result) {
if (result !== undefined) {
if (result.status === 'failed') {
++failureCount;
}
logs.push(result.info);
}
}
}
function search(obj, key) {
var arr = [];
for (var i in obj) {
if (!obj.hasOwnProperty(i)) continue; //exclude properties from __proto__
if (i === key) {
var o = new Object;
o[i] = obj[i];
arr.push(o);
}
if (typeof obj[i] === 'object') {
arr = arr.concat(search(obj[i], key));
}
}
return arr;
}
"assertion_criteria": {
"baidu.com/home/display": {
"whitelist": ["<title>Home</title>", "name", "货币"]
},
"baidu.com/search": {
"blacklist": ["pageInfo", "id", "时间戳"]
}
}
function flatten(obj) {
var arr = [];
if(obj instanceof Array) {
obj.forEach(function(element) {
if(typeof element!=='object') {
arr.push('ROOT:' + element);
} else {
arr = arr.concat(flatten(element));
}
});
} else {
for(var key in obj) {
if(!obj.hasOwnProperty(key)) continue;
if(typeof obj[key]!=='object') {
arr.push(key + ':' + obj[key]);
} else {
if(obj[key] instanceof Array) {
obj[key].forEach(function(element) {
if(typeof element==='object') {
arr = arr.concat(flatten(element));
} else {
arr.push(key + ':' + element);
}
});
} else {
arr = arr.concat(flatten(obj[key]));
}
}
}
}
arr.sort();
return arr;
}
把http reponse经过上述黑白名单、扁平化处理后,就可以使用chai库进行字符串或者json对象比较(chai的eql或者contain方法),判断结果是否一致。这里就不贴代码了。
总结
使用node.js进行API自动化回归测试的更多相关文章
- 十个书写Node.js REST API的最佳实践(上)
收录待用,修改转载已取得腾讯云授权 原文:10 Best Practices for Writing Node.js REST APIs 我们会通过本文介绍下书写Node.js REST API的最佳 ...
- AngularJS 授权 + Node.js REST api
作者好屌啊,我不懂的他全都懂. Authentication with AngularJS and a Node.js REST api 几个月前,我开始觉得 AngularJS 好像好牛逼的样子,于 ...
- Node.js RESTful API
什么是REST架构? REST表示代表性状态传输.REST是一种基于Web标准的架构,并使用HTTP协议. 它都是围绕着资源,其中每一个组件是资源和一个资源是由一个共同的接口使用HTTP的标准方法获得 ...
- Practical Node.js (2018版) 第8章:Building Node.js REST API Servers
Building Node.js REST API Servers with Express.js and Hapi Modern-day web developers use an architec ...
- Node.js 常用 API
Node.js v6.11.2 Documentation(官方文档) Buffer Prior to the introduction of TypedArray in ECMAScript 20 ...
- 十个书写Node.js REST API的最佳实践(下)
收录待用,修改转载已取得腾讯云授权 5. 对你的Node.js REST API进行黑盒测试 测试你的REST API最好的方法之一就是把它们当成黑盒对待. 黑盒测试是一种测试方法,通过这种方法无需知 ...
- 编写 Node.js Rest API 的 10 个最佳实践
Node.js 除了用来编写 WEB 应用之外,还可以用来编写 API 服务,我们在本文中会介绍编写 Node.js Rest API 的最佳实践,包括如何命名路由.进行认证和测试等话题,内容摘要如下 ...
- 基于 Node.js 的服务器自动化部署搭建实录
基于 Node.js 的服务器自动化部署搭建实录 在服务器上安装 Node.js 编写拉取仓库.重启服务器脚本 配置 Github 仓库的 Webhook 设置 配置 Node.js 脚本 其他问题 ...
- 使用Node.js原生API写一个web服务器
Node.js是JavaScript基础上发展起来的语言,所以前端开发者应该天生就会一点.一般我们会用它来做CLI工具或者Web服务器,做Web服务器也有很多成熟的框架,比如Express和Koa.但 ...
随机推荐
- 深圳scala-meetup-20180902(3)- Using heterogeneous Monads in for-comprehension with Monad Transformer
scala中的Option类型是个很好用的数据结构,用None来替代java的null可以大大降低代码的复杂性,它还是一个更容易解释的状态表达形式,比如在读取数据时我们用Some(Row)来代表读取的 ...
- virtual box 下安装centos 7
1: 在virtual box下导入 镜像的时候报错: Failed to open/create the internal network 'HostInterfaceNetworking-Virt ...
- 阿里开源项目arthas安装使用
文档地址 https://alibaba.github.io/arthas/install-detail.html 开始安装 我本地就装window版本了,下载zip包 按照快速入门,编译demo程序 ...
- IDEA搭建SSM实现登录、注册,数据增删改查功能
本博文的源代码:百度云盘/java/java实例/SSM实例/SSM实现登录注册,增删改查/IDEA搭建SSM实现登录,注册,增删改查功能.zip 搭建空的Maven项目 使用Intellij id ...
- 请求报错:“应以Content-Type: application/x-www-form-urlencoded为请求类型,在form表单中提交登录信息。"
竟然是post 方法少了参数 // // 摘要: // 以异步操作将 POST 请求发送给指定 URI. // // 参数: // requestUri: // 请求发送到的 URI. // // c ...
- Java 项目UML反向工程转化工具
今天在看一个模拟器的源码,一个包里有多个类,一个类里又有多个属性和方法,如果按顺序看下来,不仅不能对整个模拟器的框架形成一个大致的认识,而且只会越看越混乱,所以,想到有没有什么工具可以将这些个类以及它 ...
- OC学习4——OC新特性之块(Block)
文章主要参考 关于OC中的block自己的一些理解(一) 对块的深入理解 浅析ios开发中Block块语法的妙用 1.关于block block的作用:保存一段代码. 苹果官方推荐的一种语法,类似 ...
- 【xsy2304】哈 最短路
题目大意:有一个$n$个点,$m$条有向边的图,有$q$组询问. 每次询问:从$a$到$b$,经过不超过$c$条边,且依次经过的边边权递增,问最短路为多少,无解输出-1. 数据范围:$n≤150$,$ ...
- 微服务开发有道之把项目迁移到Kubernetes上的5个小技巧
我们将在本文中提供5个诀窍帮你将项目迁移到Kubernetes上,这些诀窍来源于过去12个月中OpenFaas社区的经验.下文的内容与Kubernetes 1.8兼容,并且已经应用于OpenFaaS ...
- 详解C#异常处理
一.程序运行时产生的错误通过使用一种称为异常(Exception)的机制在程序中传递,通过异常处理(Exception Handling)有助于处理程序运行过程中发生的意外或异常情况:异常可由CLR和 ...