Sql_索引分析
「索引就像书的目录, 通过书的目录就准确的定位到了书籍具体的内容」,这句话描述的非常正确, 但就像脱了裤子放屁,说了跟没说一样,通过目录查找书的内容自然是要比一页一页的翻书找来的快,同样使用的索引的人难到会不知道,通过索引定位到数据比直接一条一条的查询来的快,不然他们为什么要建索引。
想要理解索引原理必须清楚一种数据结构「平衡树」(非二叉),也就是b tree或者 b+ tree,重要的事情说三遍:“平衡树,平衡树,平衡树”。当然, 有的数据库也使用哈希桶作用索引的数据结构 , 然而, 主流的RDBMS都是把平衡树当做数据表默认的索引数据结构的。
我们平时建表的时候都会为表加上主键, 在某些关系数据库中, 如果建表时不指定主键,数据库会拒绝建表的语句执行。 事实上, 一个加了主键的表,并不能被称之为「表」。一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。

上图就是带有主键的表(聚集索引)的结构图。图画的不是很好, 将就着看。其中树的所有结点(底部除外)的数据都是由主键字段中的数据构成,也就是通常我们指定主键的id字段。最下面部分是真正表中的数据。 假如我们执行一个SQL语句:
select * from table where id = 1256;
首先根据索引定位到1256这个值所在的叶结点,然后再通过叶结点取到id等于1256的数据行。 这里不讲解平衡树的运行细节, 但是从上图能看出,树一共有三层, 从根节点至叶节点只需要经过三次查找就能得到结果。如下图
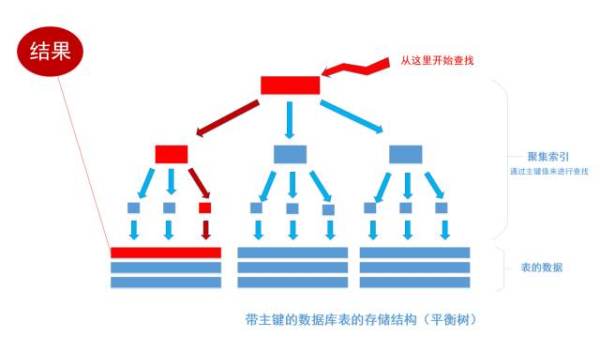
假如一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,用大O标记法就是O(n)最坏时间复杂度,这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用, 因此, 这一亿次匹配在不经缓存优化的情况下就是一亿次IO开销,以现在磁盘的IO能力和CPU的运算能力, 有可能需要几个月才能得出结果 。如果把这张表转换成平衡树结构(一棵非常茂盛和节点非常多的树),假设这棵树有10层,那么只需要10次IO开销就能查找到所需要的数据, 速度以指数级别提升,用大O标记法就是O(log n),n是记录总树,底数是树的分叉数,结果就是树的层次数。换言之,查找次数是以树的分叉数为底,记录总数的对数,用公式来表示就是

用程序来表示就是Math.Log(100000000,10),100000000是记录数,10是树的分叉数(真实环境下分叉数远不止10), 结果就是查找次数,这里的结果从亿降到了个位数。因此,利用索引会使数据库查询有惊人的性能提升。
然而, 事物都是有两面的, 索引能让数据库查询数据的速度上升, 而使写入数据的速度下降,原因很简单的, 因为平衡树这个结构必须一直维持在一个正确的状态, 增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, DBMS必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
讲完聚集索引 , 接下来聊一下非聚集索引, 也就是我们平时经常提起和使用的常规索引。
非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。 如下图

每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,如下图

不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。
然而, 有一种例外可以不使用聚集索引就能查询出所需要的数据, 这种非主流的方法 称之为「覆盖索引」查询, 也就是平时所说的复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
先看下面这个SQL语句
//建立索引
create index index_birthday on user_info(birthday);
//查询生日在1991年11月1日出生用户的用户名
select user_name from user_info where birthday = '1991-11-1'
这句SQL语句的执行过程如下
首先,通过非聚集索引index_birthday查找birthday等于1991-11-1的所有记录的主键ID值
然后,通过得到的主键ID值执行聚集索引查找,找到主键ID值对就的真实数据(数据行)存储的位置
最后, 从得到的真实数据中取得user_name字段的值返回, 也就是取得最终的结果
我们把birthday字段上的索引改成双字段的覆盖索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
这句SQL语句的执行过程就会变为
通过非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的叶节点的内容,然而, 叶节点中除了有user_name表主键ID的值以外, user_name字段的值也在里面, 因此不需要通过主键ID值的查找数据行的真实所在, 直接取得叶节点中user_name的值返回即可。 通过这种覆盖索引直接查找的方式, 可以省略不使用覆盖索引查找的后面两个步骤, 大大的提高了查询性能,如下图
Sql_索引分析的更多相关文章
- MySQL索引分析
索引的出现解决数据量上升导致查询越来越慢的问题,优化数据的查询,提高查询的速度. 索引 定义: 通过各种数据结构实现的值到行位置的映射.快速定位与访问特定的数据. 作用: 提高访问速度 实现主键.唯一 ...
- Elasticsearch的索引模块(正排索引、倒排索引、索引分析模块Analyzer、索引和搜索、停用词、中文分词器)
正向索引的结构如下: “文档1”的ID > 单词1:出现次数,出现位置列表:单词2:出现次数,出现位置列表:…………. “文档2”的ID > 此文档出现的关键词列表. 一般是通过key,去 ...
- MySQL 索引分析
MySQL复合唯一索引分析 关于复合唯一索引(unique key 或 unique index),网上搜索不少人说:"这种索引起到的关键作用是约束,查询时性能上没有得到提高或者查询时根本没 ...
- B+Tree和MySQL索引分析
首先区分两组概念: 稠密索引,稀疏索引: 聚簇索引,非聚簇索引: btree和mysql的分析: 参见 http://blog.csdn.net/hguisu/article/details/7786 ...
- sphinx索引分析——文件格式和字典是double array trie 检索树,索引存储 – 多路归并排序,文档id压缩 – Variable Byte Coding
1 概述 这是基于开源的sphinx全文检索引擎的架构代码分析,本篇主要描述index索引服务的分析.当前分析的版本 sphinx-2.0.4 2 index 功能 3 文件表 4 索引文件结构 4. ...
- SQL Server 2012 列存储索引分析(翻译)
一.概述 列存储索引是SQL Server 2012中为提高数据查询的性能而引入的一个新特性,顾名思义,数据以列的方式存储在页中,不同于聚集索引.非聚集索引及堆表等以行为单位的方式存储.因为它并不要求 ...
- PLSQL_性能优化系列12_Oracle Index Anaylsis索引分析
2014-10-04 Created By BaoXinjian
- Mysql索引分析:适合建索引?不适合建索引?【转】
数据库建立索引常用的规则如下: 1.表的主键.外键必须有索引: 2.数据量超过300的表应该有索引: 3.经常与其他表进行连接的表,在连接字段上应该建立索引: 4.经常出现在Where子句中的字段,特 ...
- MySQL高级知识(五)——索引分析
前言:前面已经学习了explain(执行计划)的相关知识,这里利用explain对索引进行优化分析. 0.准备 首先创建三张表:tb_emp(职工表).tb_dept(部门表)和tb_desc(描述表 ...
随机推荐
- 给 Linux 系统“减肥”,系统垃圾清理_系统安装与配置管理_Linux Today - Google Chrome
给 Linux 系统"减肥",系统垃圾清理 2013/10/16 linux 系统安装与配置管理 评论 15,555 Linux 计算机安装后,在我们不断的使用过程中,因 ...
- 两个列表lst1和lst2,计算两个列表的公共元素和非公共元素
方法1: 列表推导式 lst1 = [1, 3, 7] lst2 = [3, 5, 4] a = [x for x in lst1 if x in lst2] b = [y for y in (lst ...
- java调用Linux执行Python爬虫,并将数据存储到elasticsearch中--(java后台代码)
该篇博客主要是java代码,如需相应脚本及java连接elasticsearch工具类代码,请移步到上一篇博客(https://www.cnblogs.com/chenyuanbo/p/9973685 ...
- <20180929>任性的甲方
今天参观了朋友在监督的新项目, 这个项目周期大概在6到9个月,预计本年度11月竣工. 总共大楼有五层, 施工面积在一万平米左右. 位于三楼的机房使用的设备有点高大上,发上来鉴赏一下. 双专线, 第二条 ...
- centos7下安装docker(9.3容器对资源的使用限制-Block IO))
Block IO:指的是磁盘的读写,docker 可以通过设置权重,限制bps和iops的方式控制容器读写磁盘的带宽 注:目前block IO限额只对direct IO(不使用文件缓存)有效. 1.B ...
- 项目Alpha冲刺 5
作业描述 课程: 软件工程1916|W(福州大学) 作业要求: 项目Alpha冲刺(团队) 团队名称: 火鸡堂 作业目标: 介绍第五天冲刺的项目进展.问题困难和心得体会 1.团队信息 队名:火鸡堂 队 ...
- MySql常用命令集Mysql常用命令showdatabases;显示数据库createdatab
MySql 常用命令集 Mysql常用命令 show databases; 显示数据库 create database name; 创建数据库 use databasename; 选择数据库 drop ...
- 用OpenSCAD設計特製的遊戲骰子
一開始先製作一個簡單的立方體.定義一個變量「cube_size」,然後使用下圖的立方體程式.center=true的設定可讓立方體位於起始模型的正中央. 為你在OpenSCAD創造的物體加上不同顏色是 ...
- zookeeper入门之Curator的使用之几种监听器的使用
package com.git.zookeeper.passwordmanager.listener; import java.util.ArrayList; import java.util.Lis ...
- Mongodb数据库连接
Mongodb数据库连接 1. 首先我们需要 在包中安装 mongodb, 使用命令: npm install mongodb; 在安装包后,我们需要引用该包:如下: var mongo = requ ...