07、RDD持久化

|
持久化级别 |
|
|
MEMORY_ONLY |
以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下一次需要使用它的时候,重新被计算 |
|
MEMORY_AND_DISK |
同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘上读取 |
|
MEMORY_ONLY_SER |
同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销 |
|
MEMORY_AND_DSK_SER |
同MEMORY_AND_DSK。但是使用序列化方式持久化Java对象 |
|
DISK_ONLY |
使用非序列化Java对象的方式持久化,完全存储到磁盘上 |
|
MEMORY_ONLY_2 MEMORY_AND_DISK_2 等等 |
如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可 |
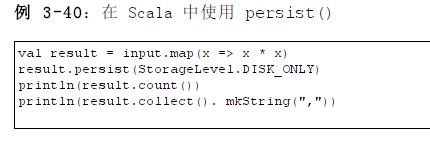
}
07、RDD持久化的更多相关文章
- Spark RDD概念学习系列之rdd持久化、广播、累加器(十八)
1.rdd持久化 2.广播 3.累加器 1.rdd持久化 通过spark-shell,可以快速的验证我们的想法和操作! 启动hdfs集群 spark@SparkSingleNode:/usr/loca ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- 【Spark调优】:RDD持久化策略
[场景] Spark对RDD执行一系列算子操作时,都会重新从头到尾计算一遍.如果中间结果RDD后续需要被被调用多次,可以显式调用 cache()和 persist(),以告知 Spark,临时保存之前 ...
- spark rdd持久化的简单对比
未使用rdd持久化 使用后 通过对比可以发现,未使用RDD持久化时,第一次计算比使用RDD持久化要快,但之后的计算显然要慢的多,差不多10倍的样子 代码 public class PersistRDD ...
- 8、RDD持久化
一.RDD持久化 1.不使用RDD持久化的问题 2.RDD持久化原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的par ...
- Spark练习之创建RDD(集合、本地文件),RDD持久化及RDD持久化策略
Spark练习之创建RDD(集合.本地文件) 一.创建RDD 二.并行化集合创建RDD 2.1 Java并行创建RDD--计算1-10的累加和 2.2 Scala并行创建RDD--计算1-10的累加和 ...
- 五、RDD持久化
Spark最重要的一个功能是它可以通过各种操作(operations)持久化(或者缓存)一个集合到内存中.当你持久化一个RDD的时候,每一个节点都将参与计算的所有分区数据存储到内存中,并且这些数据可以 ...
- spark复习笔记(6):RDD持久化
在spark中最重要的功能之一是跨操作在内存中持久化数据集.当你持久化一个RDD的时候,每个节点都存放了一个它在内存中计算的一个分区,并在该数据集的其他操作中进行重用,持久化一个RDD的时候,节点上的 ...
- Spark性能调优篇二之重构RDD架构及RDD持久化
如果一个RDD在两个地方用到,就持久化他.不然第二次用到他时,会再次计算. 直接调用cache()或者presist()方法对指定的RDD进行缓存(持久化)操作,同时在方法中指定缓存的策略. 原文:h ...
随机推荐
- Python的_文件操作
打开文件:file_obj=open("文件路径","模式",“编码”’) 其中模式有: r,以只读方式打开文件(默认) w,打开一个文件只用于写入(不存在则创 ...
- Mysql 锁库与锁表
一.全局锁表 1.FLUSH TABLES WITH READ LOCK 这个命令是全局读锁定,执行了命令之后所有库所有表都被锁定只读.一般都是用在数据库联机备份,这个时候数据库的写操作将被阻塞,读操 ...
- BZOJ1066 [SCOI2007]蜥蜴 网络流 最大流 SAP
由于本题和HDU2732几乎相同,所以读者可以看-> HDU2732题解传送门: http://www.cnblogs.com/zhouzhendong/p/8362002.html
- orleans exception序列化
options.FallbackSerializationProvider = typeof(ILBasedSerializer).GetTypeInfo();
- day16 函数的用法:内置函数,匿名函数
思维导图需要补全 : 一共有68个内置函数: #内置:python自带 # def func(): # a = 1 # b = 2 # print(locals()) # print(globals( ...
- 线程有gil锁
gil锁作用: 遇到阻塞( 比如 recv() , accept() )就切换
- Java实现简单记事本
代码实现: import java.awt.BorderLayout; import java.awt.Container; import java.awt.event.ActionEvent; im ...
- 最短路(bellman)-hdu1217
Dijkstra算法是处理单源最短路径的有效算法,但它局限于边的权值非负的情况,若图中出现权值为负的边,Dijkstra算法就会失效,求出的最短路径就可能是错的. 这时候,就需要使用其他的算法来求解最 ...
- LYOI 2016 Summer 函数 【线段树】
<题目链接> 题目大意: fqk 退役后开始补习文化课啦,于是他打开了数学必修一开始复习函数,他回想起了一次函数都是 f(x)=kx+b的形式,现在他给了你n个一次函数 fi(x)=kix ...
- Linux开源监控平台归总
Linux开源监控平台归总 Cacti 偏向于基础监控.成图非常漂亮,需要php环境支持,并且需要mysql作为数据存储 Cacti是一个性能广泛的图表和趋势分析工具,可以用来跟踪并几乎可以绘制出任何 ...