8、RDD持久化
一、RDD持久化
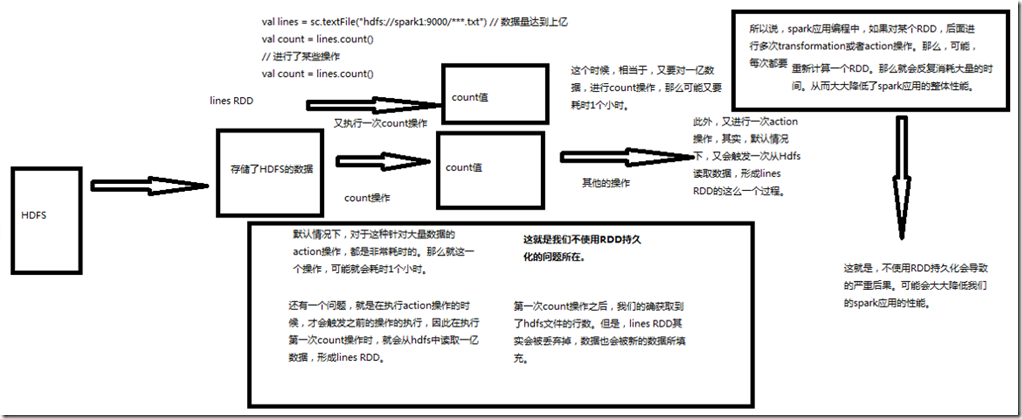
1、不使用RDD持久化的问题
2、RDD持久化原理
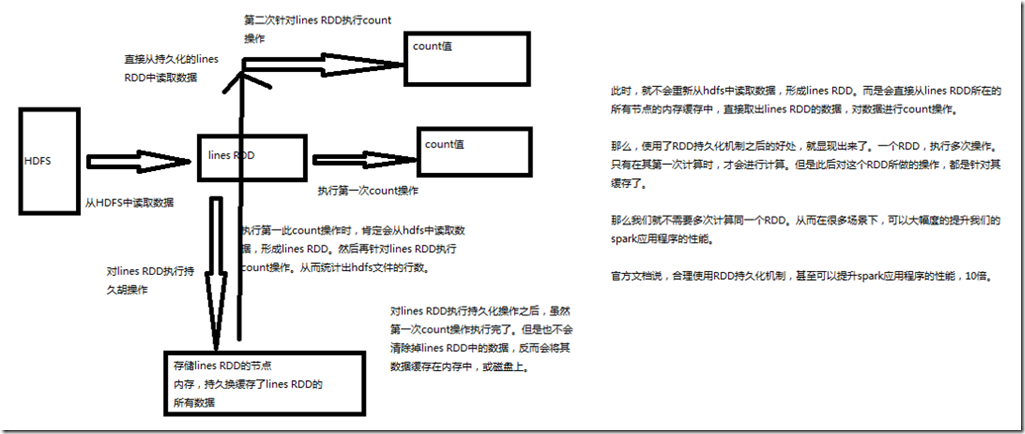
Spark非常重要的一个功能特性就是可以将RDD持久化在内存中。当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内存中,并且在之后对
该RDD的反复使用中,直接使用内存缓存的partition。这样的话,对于针对一个RDD反复执行多个操作的场景,就只要对RDD计算一次即可,后面直接使用该RDD,而不
需要反复计算多次该RDD。 巧妙使用RDD持久化,甚至在某些场景下,可以将spark应用程序的性能提升10倍。对于迭代式算法和快速交互式应用来说,RDD持久化,是非常重要的。 要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接缓存在每个节点中。而且Spark的持久化机制还是自动容错的,
如果持久化的RDD的任何partition丢失了,那么Spark会自动通过其源RDD,使用transformation操作重新计算该partition。 cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,同时就是调用persist(MEMORY_ONLY),将数据持久化到内存
中。如果需要从内存中清楚缓存,那么可以使用unpersist()方法。 Spark自己也会在shuffle操作时,进行数据的持久化,比如写入磁盘,主要是为了在节点失败时,避免需要重新计算整个过程。
3、RDD持久化
------java实现-------- package cn.spark.study.core; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext; /**
* RDD持久化
* @author Administrator
*
*/
public class Persist { public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("Persist")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf); // cache()或者persist()的使用,是有规则的
// 必须在transformation或者textFile等创建了一个RDD之后,直接连续调用cache()或persist()才可以
// 如果你先创建一个RDD,然后单独另起一行执行cache()或persist()方法,是没有用的
// 而且,会报错,大量的文件会丢失
JavaRDD<String> lines = sc.textFile("D://test-file//spark.txt").cache(); long beginTime = System.currentTimeMillis(); long count = lines.count();
System.out.println(count); long endTime = System.currentTimeMillis();
System.out.println("cost " + (endTime - beginTime) + " milliseconds."); beginTime = System.currentTimeMillis(); count = lines.count();
System.out.println(count); endTime = System.currentTimeMillis();
System.out.println("cost " + (endTime - beginTime) + " milliseconds."); sc.close();
} }
4、RDD持久化策略
RDD持久化是可以手动选择不同的策略的。比如可以将RDD持久化在内存中、持久化到磁盘上、使用序列化的方式持久化,多持久化的数据进行多路复用。
只要在调用persist()时传入对应的StorageLevel即可。

5、如何选择RDD持久化策略?
- 默认情况下,性能最高的当然是MEMORY_ONLY,但前提是内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
- 如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
- 如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
- 通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
8、RDD持久化的更多相关文章
- Spark RDD概念学习系列之rdd持久化、广播、累加器(十八)
1.rdd持久化 2.广播 3.累加器 1.rdd持久化 通过spark-shell,可以快速的验证我们的想法和操作! 启动hdfs集群 spark@SparkSingleNode:/usr/loca ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- 07、RDD持久化
为了避免多次计算同一个RDD(如上面的同一result RDD就调用了两次Action操作),可以让Spark对数据进行持久化.当我们让Spark持久化存储一个RDD时,计算出RDD的节点会分别保存它 ...
- 【Spark调优】:RDD持久化策略
[场景] Spark对RDD执行一系列算子操作时,都会重新从头到尾计算一遍.如果中间结果RDD后续需要被被调用多次,可以显式调用 cache()和 persist(),以告知 Spark,临时保存之前 ...
- spark rdd持久化的简单对比
未使用rdd持久化 使用后 通过对比可以发现,未使用RDD持久化时,第一次计算比使用RDD持久化要快,但之后的计算显然要慢的多,差不多10倍的样子 代码 public class PersistRDD ...
- Spark练习之创建RDD(集合、本地文件),RDD持久化及RDD持久化策略
Spark练习之创建RDD(集合.本地文件) 一.创建RDD 二.并行化集合创建RDD 2.1 Java并行创建RDD--计算1-10的累加和 2.2 Scala并行创建RDD--计算1-10的累加和 ...
- 五、RDD持久化
Spark最重要的一个功能是它可以通过各种操作(operations)持久化(或者缓存)一个集合到内存中.当你持久化一个RDD的时候,每一个节点都将参与计算的所有分区数据存储到内存中,并且这些数据可以 ...
- spark复习笔记(6):RDD持久化
在spark中最重要的功能之一是跨操作在内存中持久化数据集.当你持久化一个RDD的时候,每个节点都存放了一个它在内存中计算的一个分区,并在该数据集的其他操作中进行重用,持久化一个RDD的时候,节点上的 ...
- Spark性能调优篇二之重构RDD架构及RDD持久化
如果一个RDD在两个地方用到,就持久化他.不然第二次用到他时,会再次计算. 直接调用cache()或者presist()方法对指定的RDD进行缓存(持久化)操作,同时在方法中指定缓存的策略. 原文:h ...
随机推荐
- ALV报表——表头实现
ABAP实现ALV表头的DEMO: 运行效果: 代码: *********************************************************************** ...
- Vector、ArrayList异同和HTTP请求异同的概括和区别
今天我所记录的是两个异同的概括: HTTP: 同步请求:提交请求->等待服务器处理->处理完毕返回给客户端 这个期间客户端浏览器只能处于等待状态,得到回应才可以执行下一步操作. 异步请求 ...
- javascript基本类型和对象
JS 中分为七种内置类型,七种内置类型又分为两大类型:基本类型和对象(Object). 基本类型 null undefined boolean number string symbol 其中 JS 的 ...
- truncate删除一个分区,测试全局索引是否失效
目的,有一个清理数据的需求,需要删除历史的一个分区所有记录信息,但是存在主键global索引,如何更好的维护. 如下测试流程一 提前创建好一个已时间created 字段作为分区键的范围分区表 SQL& ...
- J.U.C之重入锁:ReentrantLock
此篇博客所有源码均来自JDK 1.8 ReentrantLock,可重入锁,是一种递归无阻塞的同步机制.它可以等同于synchronized的使用,但是ReentrantLock提供了比synchro ...
- java线程的五种状态
五种状态 开始状态(new) 就绪状态(runnable) 运行状态(running) 阻塞状态(blocked) 结束状态(dead) 状态变化 1.线程刚创建时,是new状态 2.线程调用了sta ...
- jquery input file 多图上传,单张删除,查看
<div class="form-group"> <label for="imgs" class="col-md-3 col-sm- ...
- Java 之 字符输出流[writer]
一.字符输出流 java.io.Writer 抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地. 它定义了字节输出流的基本共性功能方法. void write(int c) ...
- English-培训6-Do you like rap?
- stm32 引脚映射 和 ADC
老是弄不明白ADC的输入到底在哪,看了stm32F103Ve的datasheet,将引脚和通道的映射关系贴在下面: 好了,写到这,我已经看了中文手册一上午了,可是啥都没看懂,下午接着看,写代码不重要, ...