07、RDD持久化

|
持久化级别 |
|
|
MEMORY_ONLY |
以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下一次需要使用它的时候,重新被计算 |
|
MEMORY_AND_DISK |
同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘上读取 |
|
MEMORY_ONLY_SER |
同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销 |
|
MEMORY_AND_DSK_SER |
同MEMORY_AND_DSK。但是使用序列化方式持久化Java对象 |
|
DISK_ONLY |
使用非序列化Java对象的方式持久化,完全存储到磁盘上 |
|
MEMORY_ONLY_2 MEMORY_AND_DISK_2 等等 |
如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可 |
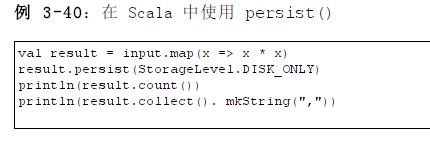
}
07、RDD持久化的更多相关文章
- Spark RDD概念学习系列之rdd持久化、广播、累加器(十八)
1.rdd持久化 2.广播 3.累加器 1.rdd持久化 通过spark-shell,可以快速的验证我们的想法和操作! 启动hdfs集群 spark@SparkSingleNode:/usr/loca ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- 【Spark调优】:RDD持久化策略
[场景] Spark对RDD执行一系列算子操作时,都会重新从头到尾计算一遍.如果中间结果RDD后续需要被被调用多次,可以显式调用 cache()和 persist(),以告知 Spark,临时保存之前 ...
- spark rdd持久化的简单对比
未使用rdd持久化 使用后 通过对比可以发现,未使用RDD持久化时,第一次计算比使用RDD持久化要快,但之后的计算显然要慢的多,差不多10倍的样子 代码 public class PersistRDD ...
- 8、RDD持久化
一.RDD持久化 1.不使用RDD持久化的问题 2.RDD持久化原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的par ...
- Spark练习之创建RDD(集合、本地文件),RDD持久化及RDD持久化策略
Spark练习之创建RDD(集合.本地文件) 一.创建RDD 二.并行化集合创建RDD 2.1 Java并行创建RDD--计算1-10的累加和 2.2 Scala并行创建RDD--计算1-10的累加和 ...
- 五、RDD持久化
Spark最重要的一个功能是它可以通过各种操作(operations)持久化(或者缓存)一个集合到内存中.当你持久化一个RDD的时候,每一个节点都将参与计算的所有分区数据存储到内存中,并且这些数据可以 ...
- spark复习笔记(6):RDD持久化
在spark中最重要的功能之一是跨操作在内存中持久化数据集.当你持久化一个RDD的时候,每个节点都存放了一个它在内存中计算的一个分区,并在该数据集的其他操作中进行重用,持久化一个RDD的时候,节点上的 ...
- Spark性能调优篇二之重构RDD架构及RDD持久化
如果一个RDD在两个地方用到,就持久化他.不然第二次用到他时,会再次计算. 直接调用cache()或者presist()方法对指定的RDD进行缓存(持久化)操作,同时在方法中指定缓存的策略. 原文:h ...
随机推荐
- 伪分布式hbase从0.94.11版本升级stable的1.4.9版本
Hbase从0.94.11升级到stable的1.4.9版本: 升级思路: hadoop1.1.2 hbase 0.94.11 ↓ had ...
- web前端中navigator
<script> if(navigator.cookieEnabled){ document.write("浏览器已启用cookie,请妥善保存个人信息"); }els ...
- List接口相对于Collection接口的特有方法
[添加功能] 1 void add(int index,Object element); // 在指定位置添加一个元素. [获取功能] 1 Object get(int index); // 获取指定 ...
- 设计模式之单例模式及应用demo
单例模式是创建型模式之一. 单例模式顾名思义是单例的,也就是只有一个实例化对象,这都来源于它的私有化构造函数. 单例模式特点: 1.单例类只能有一个实例. 2.单例类必须自己创建自己的唯一实例. 3. ...
- Create-react-app+Antd-mobile+Less配置(学习中的记录)
(参考别人结合自己的整理得出,若有错误请大神指出) Facebook 官方推出Create-React-App脚手架,基本可以零配置搭建基于webpack的React开发环境,内置了热更新等功能. 详 ...
- JavaEE 之 文件上传
1.文件上传 a.配置mySpring-servlet.xml <bean id="multipartResolver" class="org.springfram ...
- Django之ORM操作总结
Django之ORM总结 表结构 from django.db import models # 一对多:班级与学生 # 多对多:班级与老师 # Create your models here. #创建 ...
- mybatis查询语句的背后之封装数据
转载请注明出处... 一.前言 继上一篇mybatis查询语句的背后,这一篇主要围绕着mybatis查询的后期操作,即跟数据库交互的时候.由于本人也是一边学习源码一边记录,内容难免有错误或不足之处,还 ...
- webstorm离线装载Material Theme UI
首先说说需求,由于直接用webstorm听说VS挺火的,但是初恋的感觉是其他任何编辑器无法替代的 瞎说了一些话,新公司内网开发,用的是vscode,但是我还是喜欢用webstorm,连不上网,所以不能 ...
- Linux 默认目录
/etc 存放系统管理所需要的配置文件和子目录 /home 一般用户的主目录 /usr 用户使用的系统目录和应用程序等信息 /bin 存放使用者经常使用的命令 如cp ls cat 等 /proc ...