Hadoop & Spark
- Hadoop & Spark 概述
Apache Hadoop 是一种通过服务集群并使用MapReduce编程数据模型完成大数据的分布式处理框架,核心模块包括:MapReduce,Hadoop Utilites,YARN(Yet Another Resource Negotiator)和HDFS(Hadoop Distributed File System)。
MapReduce是一种提供平行计算的编程模型,具有位置感知计划(locality-aware scheduling),容错(fault-tolerance),和可扩展性(scalability);
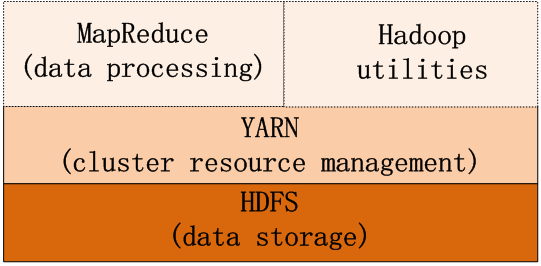
MapReduce把数据处理分为两个阶段:Map阶段和Reduce阶段,处理流程如下:
(1)每一个分割文件对应一个map任务,mapper首先将输入数据转化为中间数据,然后将结果输出到一个循环的内存缓冲中(默认100M);
(2)当这个缓冲中的数据接近阀值(默认80%),mapper开始将缓存中的内容写入本地磁盘的一个文件,但在数据写入之前,mapper将数据分成几个写入区,写入区的数据量对应于reducer的数量(或reduce task数量);同时,在数据分区期间,数据结果默认以key排序。
(3)在数据写入磁盘的同时,当完成在缓存中写入数据时,这个map任务被阻塞,直到缓存中的内容全部被清空。
(4)一旦mapper完成输出,reducer或reduce task(负责将相同key的中间结果收缩到一个更小的结果集)开始从mapper中抓取一个特定分区数据,这种将mapper的输出结果转换为reducer的输入称之为数据洗牌(data shuffling),即all-map-to-all-reduce personalized communication, Hadoop使用自己的算法实现了这种数据洗牌。
(5)洗牌一旦完成,reducer开始融合(merge)这些分区,然后reduce函数被调用处理这些融合的数据;
(6)最后,reduce函数将结果输出到HDFS上。
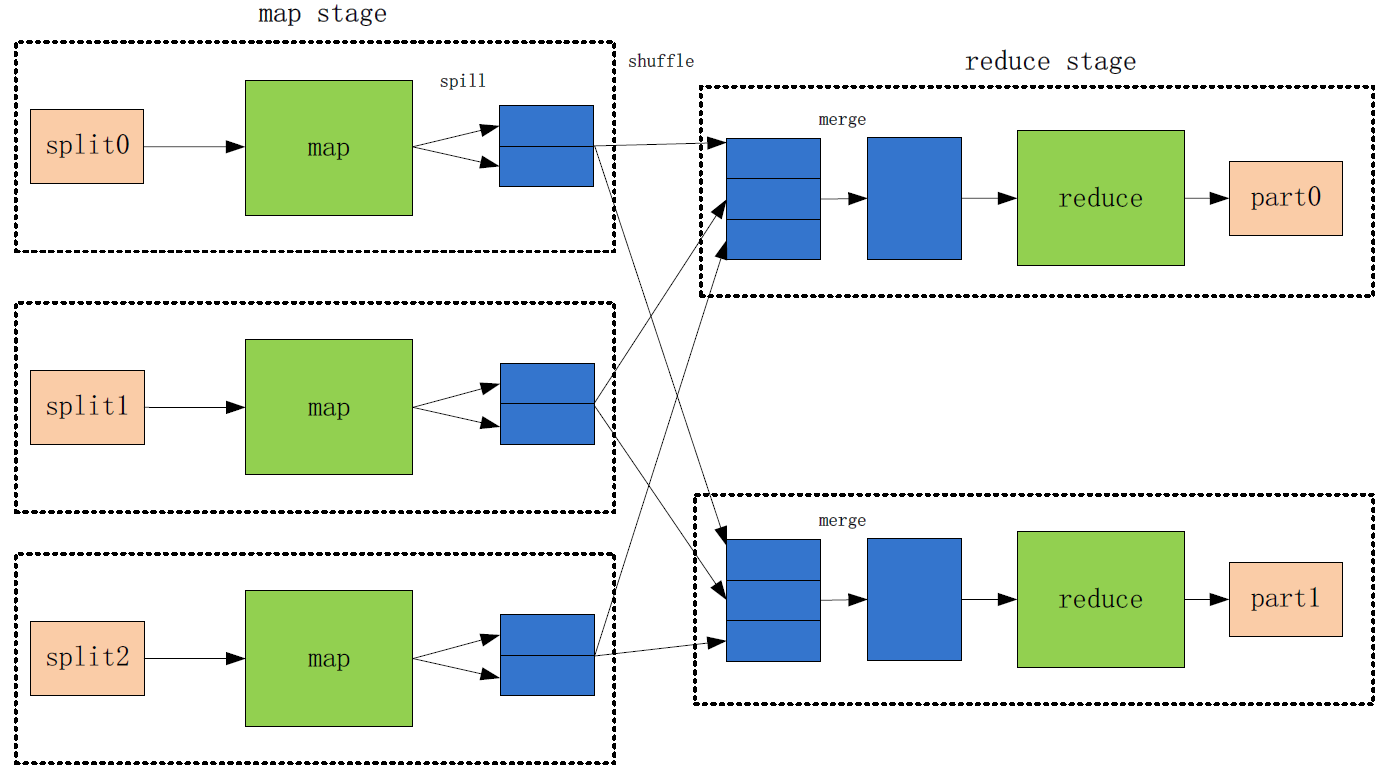
YARN在Hadoop里是一个集群资源管理框架,它包括两个主要的守护线程:一个计划job和task的管理器,即在集群之间分配资源;启动和监视容器的节点管理器;一个容器对应一个JVM实例,每个JVM实例为应用或tasks分配一定CPU、内存和其它资源;
HDFS是一个存储大数据的分布式文件系统,在分布式的数据块之间建立逻辑关系;它从应用数据中分离出文件系统元数据,将元数据存储在主节点(Name Node),应用数据存储在数据节点上(Data Node),并且HDFS在集群的节点上相互复制一定重复数量的数据块以提高系统的可靠性(以防节点的失败而导致应用不可用)。
Hadoop被认为是可靠的、可扩展的、可容错的,MapReduce虽然适合于处理大数据的应用,但对于不合适与迭代算法和低延迟的应用,因为MapReduce为了提供容错而依赖于持久化的数据,在运行分析查询之前,需将整个数据集加载到系统,这就是为什么Spark诞生的原因。
Spark也是一种处理大数据应用的集群计算框架和引擎,它在内存里构建了一个分布式的对象集合,即Resilent Distrubted Dataset(RDD),然后对这些数据集执行各类平行计算。Spark在迭代机器学习任务中的性能是MapReduce的10倍以上,甚至在某些迭代应用超过20倍。
Spark主要适用于实时数据流处理和迭代算法应用,RDDs是一种分布式内存抽象;每一个RDD是跨集群并可进行平行计算的、只读的、被分区的元素集合, 这种RDD的不可变性以为着修改任何一个RDD将创建一个新的RDD,且容易进行缓存和共享。当对RDD进行操作时,分区的数量决定了平行计算的层级;
RDDs可通过两种方式创建,从外部资源加载数据集,如HDFS,或在一个驱动程序(drive program)里对数据集进行并行分割(parallizing)。
RDDs的操作有两种类型:转换(transformations)和动作(actions), 转换即将一个RDD转化为另个一个RDD,但动作是基于RDD计算出结果并将其返回到驱动程序,最后写入外部的存储资源上。转换RDDs会被惰性评估(lazily evaluated),即Spark不会马上执行实际操作,而只是记录怎样处理或计算这些数据的元数据,一旦动作被请求,Spark才开始执行所有的实际操作(如果再次有新的动作请求,Spark会从头开始计算RDD,所以前一次动作生成中间结果数据可进行缓存或持久)。通过这种方式,Spark减少了在各个节点之间转换原始数据的次数,整个逻辑流程如下:

Spark可根据特定的环境为资源管理框架和文件系统提供多种可选的模式,比如当前有一个干净的集群服务器,可直接使用Standalone Cluster Manager来安装Spark集群;但如果已经有一个Hadoop的集群系统存在,Spark被要求访问HDFS上的数据,那最好让Spark运行在YARN上,而且YARN也提供一些安全策略和集成资源管理策略。

2. 运行架构
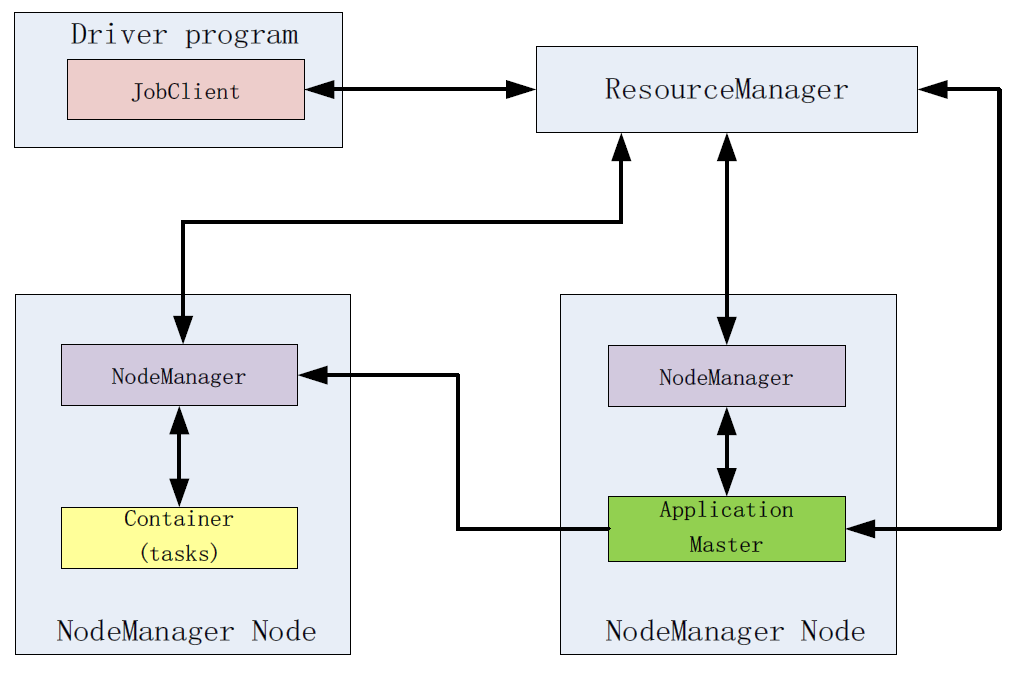
- 在Hadoop中运行一个MapReduce Jobd
- 首先一个driver program创建一个jobClient,这个jobClient请求资源管理器(ResourceManager)获取一个application ID;
- 一旦获取application ID, 则从HDFS复制资源,包括应用所需要的lib及配置文件等;
- 接着jobClient提交application到资源管理器,并且请求YARN scheduler在一个NodeManger节点分配一个容器,在这个容器里资源管理器会启动应用主程序(application master,负责初始化application job),并为每一个分割文件创建一个map任务和reduce任务;
- 如果这个job较小(小于10个map任务,一个reduce任务,每个一个输入文件的大小小于HDFS block),这个job会在本地节点执行平行计算;否则应用主程序会发送一个请求到资源管理器请求更多的容器运行MapReduce任务。
- Spark采用主从结构(master-slave architecture),spark包括一个中心节点central coordinator(driver)和一些工作节点worker(executor),driver可是一个main函数启动的进程,也可是Spark Shell启动的一个应用;
- 默认情况下,Spark以客户端模式(client mode)运行,即应用提交者在集群之外启动driver;工作节点(worker nodes)负责运行executor进程。
- 但driver也可以被放在worker节点上,但必须指定为集群模式(cluster mode);driver和executor是两个独立的进程。
- driver有两个职责:一是转化用户程序为任务单元(task units,在Spark上运行的最小工作单元),二是在executor上计划任务;
- Executor有两个角色:一是负责运行tasks并返回状态给driver,二是为RDDs提供基于内存的存储;
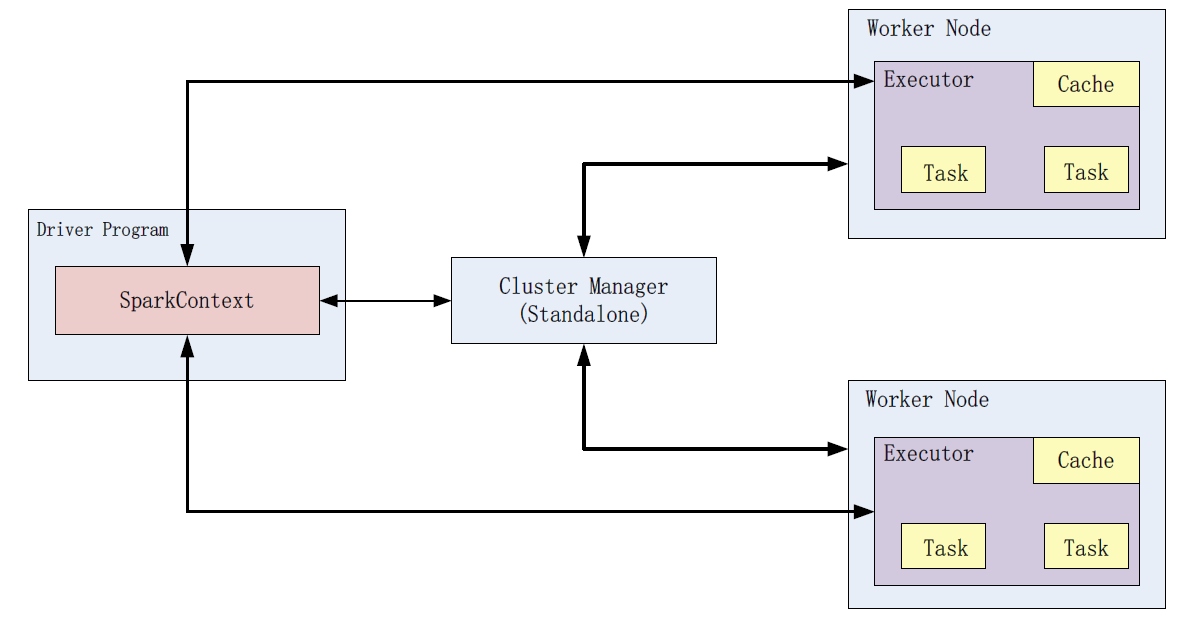
- 下图显示了一个driver program首先创建一个SparkContext,并连接到集群管理器(Cluster Manager),接着资源管理器为应用分配资源,如executors;接下来,应用代码被发送到executor;最后SparkContext派遣任务到executor去运行。
在Spark中运行一个driver program
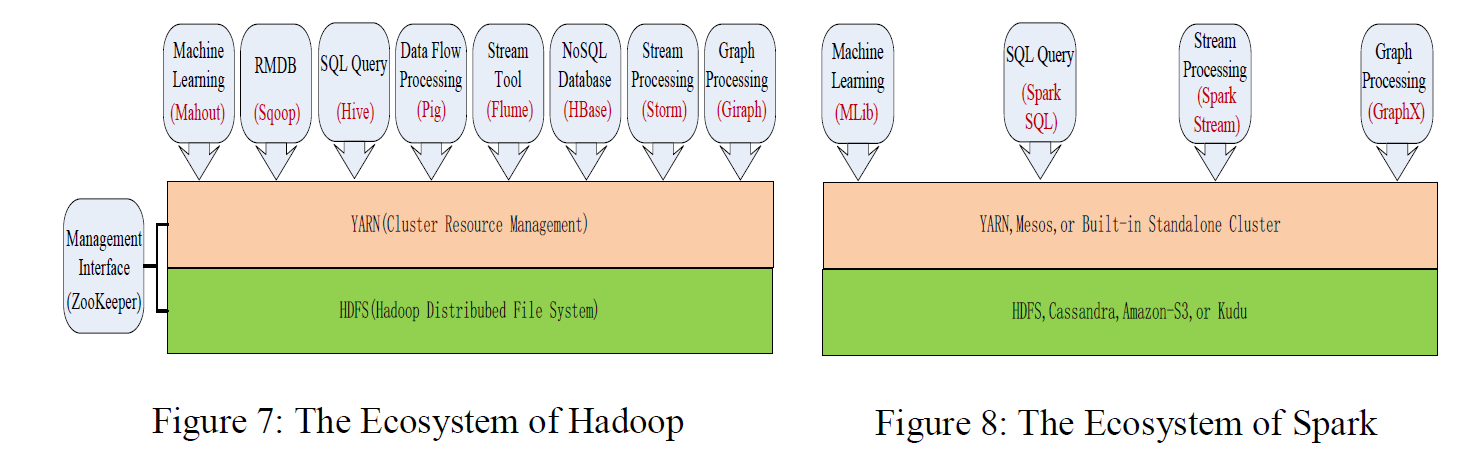
3. Hadoop和Spark各自生态系统
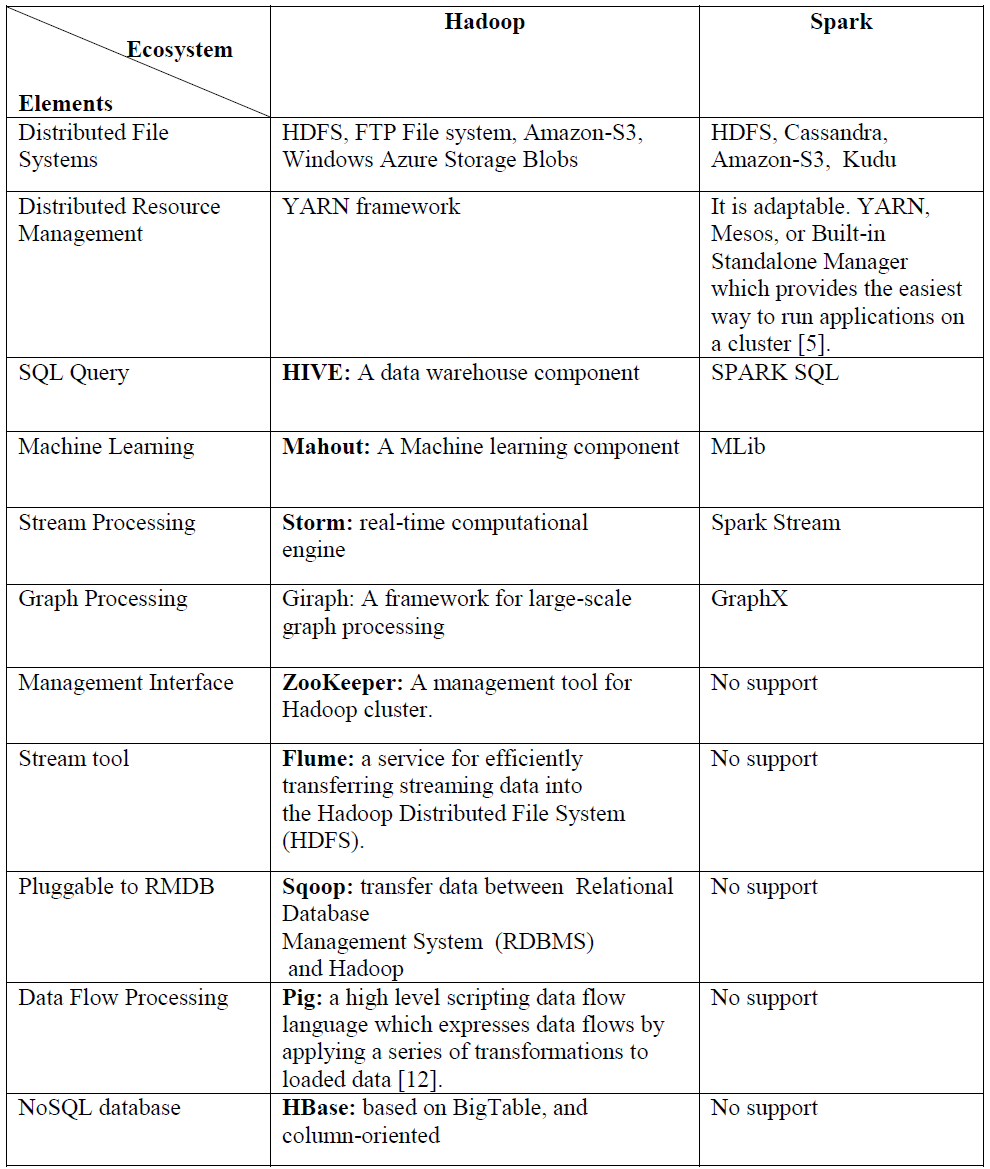
Hadoop & Spark的更多相关文章
- 大数据项目实践:基于hadoop+spark+mongodb+mysql+c#开发医院临床知识库系统
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- 哈,我自己翻译的小书,马上就完成了,是讲用python处理大数据框架hadoop,spark的
花了一些时间, 但感觉很值得. Big Data, MapReduce, Hadoop, and Spark with Python Master Big Data Analytics and Dat ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- java+hadoop+spark+hbase+scala+kafka+zookeeper配置环境变量记录备忘
java+hadoop+spark+hbase+scala 在/etc/profile 下面加上如下环境变量 export JAVA_HOME=/usr/java/jdk1.8.0_102 expor ...
- hadoop+spark+mongodb+mysql+c#
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- Hadoop Spark 集群简便安装总结
本人实际安装经验,目的是为以后高速安装.仅供自己參考. 一.Hadoop 1.操作系统一如既往:①setup关掉防火墙.②vi /etc/sysconfig/selinux,改SELINUX=disa ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
随机推荐
- Hadoop 集群的三种方式
1,Local(Standalone) Mode 单机模式 $ mkdir input $ cp etc/hadoop/*.xml input $ bin/hadoop jar share/hadoo ...
- 记录Ok6410 sd 启动uboot
1\参考资料https://github.com/SeanXP/ARM-Tiny6410/tree/master/no-os/sd-no-os/u-boot 2\参考资料https://blog.cs ...
- 实现Runnable接口创建多线程及其优势
实现Runnable接口创建多线程: 创建一个Runnable接口的实现类RunnableImpl: 主线程中: 其中,链式编程的Thread类的静态方法currentThread方法点getName ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- Flutter路由跳转及参数传递
本文要介绍的知识点 用路由推出一个新页面 打开新页面时,传入参数 参数的回传 路由 做Android/iOS原生开发的时候,要打开一个新的页面,你得知道你的目标页面对象,然后初始化一个Intent或者 ...
- Idea 全局替换指定字符
最近使用idea开发,刚接触不久,然后碰到需要全局替换的时候,懵逼了.之前使用eclipse 直接Ctrl+F 就可以操作了. 现在使用idea 摁Ctrl+F竟然只能搜,不能替换....尴尬的一匹. ...
- Convolutional Pose Machines
Convolutional Pose Machines 2018-12-10 18:17:20 Paper:https://www.cv-foundation.org/openaccess/conte ...
- Lintcode40-Implement Queue by Two Stacks-Medium
40. Implement Queue by Two Stacks As the title described, you should only use two stacks to implemen ...
- js Infinity 属性
Infinity 属性用于存放表示正无穷大的数值. 说明 无法使用 for/in 循环来枚举 Infinity 属性,也不能用 delete 运算符来删除它. Infinity 不是常量,可以把它设置 ...
- 力扣(LeetCode)482. 密钥格式化
给定一个密钥字符串S,只包含字母,数字以及 '-'(破折号).N 个 '-' 将字符串分成了 N+1 组.给定一个数字 K,重新格式化字符串,除了第一个分组以外,每个分组要包含 K 个字##符,第一个 ...