Hadoop+Spark:集群环境搭建
- 环境准备:
在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.04.2-server-amd64.iso):
192.168.1.200 master
192.168.1.201 node1
192.168.1.202 node2
- 在Master上安装Spark环境:
Spark集群环境搭建:
搭建hadoop集群使用hadoop版本是hadoop2.6.4(这里hadoop我已经安装完成,具体如何安装hadoop具体请参考我的文章:《Hadoop:搭建hadoop集群》)
搭建spark这里使用spark版本是spark1.6.2(spark-1.6.2-bin-hadoop2.6.tgz)
1、下载安装包到master虚拟服务器:
在线下载:
hadoop@master:~/ wget http://mirror.bit.edu.cn/apache/spark/spark-1.6.2/spark-1.6.2-bin-hadoop2.6.tgz
离线上传到集群:
2、解压spark安装包到master虚拟服务器/usr/local/spark下,并分配权限:
#解压到/usr/local/下
hadoop@master:~$ sudo tar -zxvf spark-1.6.2-bin-hadoop2.6.tgz -C /usr/local/
hadoop@master:~$ cd /usr/local/
hadoop@master:/usr/local$ ls
bin games include man share src
etc hadoop lib sbin spark-1.6.2-bin-hadoop2.6
#重命名 为spark
hadoop@master:/usr/local$ sudo mv spark-1.6.2-bin-hadoop2.6/ spark/
hadoop@master:/usr/local$ ls
bin etc games hadoop include lib man sbin share spark src
#分配权限
hadoop@master:/usr/local$ sudo chown -R hadoop:hadoop spark
hadoop@master:/usr/local$
3、在master虚拟服务器/etc/profile中添加Spark环境变量:
编辑/etc/profile文件
sudo vim /etc/profile
在尾部添加$SPARK_HOME变量,添加后,目前我的/etc/profile文件尾部内容如下:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export JRE_HOME=/usr/lib/jvm/java-8-oracle
export SCALA_HOME=/opt/scala/scala-2.10.5
# add hadoop bin/ directory to PATH
export HADOOP_HOME=/usr/local/hadoop
export SPARK_HOME=/usr/local/spark
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$JAVA_HOME:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$PATH
export CLASSPATH=$CLASS_PATH::$JAVA_HOME/lib:$JAVA_HOME/jre/lib
生效:
source /etc/profile
- 在Master配置Spark:
1、配置master虚拟服务器hadoop-env.sh文件:
sudo vim /usr/local/spark/conf/hadoop-env.sh
注意:默认情况下没有hadoop-env.sh和slaves文件,而是*.template文件,需要重命名:
hadoop@master:/usr/local/spark/conf$ ls
docker.properties.template metrics.properties.template spark-env.sh
fairscheduler.xml.template slaves.template
log4j.properties.template spark-defaults.conf.template
hadoop@master:/usr/local/spark/conf$ sudo vim spark-env.sh
hadoop@master:/usr/local/spark/conf$ mv slaves.template slaves
在文件末尾追加如下内容:
export STANDALONE_SPARK_MASTER_HOST=192.168.1.200
export SPARK_MASTER_IP=192.168.1.200
export SPARK_WORKER_CORES=1
#every slave node start work instance count
export SPARK_WORKER_INSTANCES=1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1g
export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}
export SCALA_HOME=/opt/scala/scala-2.10.5
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://192.168.1.200:9000/SparkEventLog"
export SPARK_WORKDER_OPTS="-Dspark.worker.cleanup.enabled=true"
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
2、配置master虚拟服务器下slaves文件:
sudo vim /usr/local/spark/conf/slaves
在slaves文件中内容如下:
192.168.1.201
192.168.1.202
注意:每行写一个机器的ip。
3、Master虚拟机下/usr/local/spark/目录下创建logs文件夹,并分配777权限:
hadoop@master:/usr/local/spark$ mkdir logs
hadoop@master:/usr/local/spark$ chmod 777 logs
- 复制Master虚拟服务器上的/usr/loca/spark下文件到所有slaves节点(node1、node2)下:
1、复制Master虚拟服务器上/usr/local/spark/安装文件到各个salves(node1、node2)上:
注意:拷贝钱需要在ssh到所有salves节点(node1、node2)上,创建/usr/local/spark/目录,并分配777权限。
hadoop@master:/usr/local/spark/conf$ cd ~/
hadoop@master:~$ sudo chmod 777 /usr/local/spark
hadoop@master:~$ scp -r /usr/local/spark hadoop@node1:/usr/local
scp: /usr/local/spark: Permission denied
hadoop@master:~$ sudo scp -r /usr/local/spark hadoop@node1:/usr/local
hadoop@node1's password:
scp: /usr/local/spark: Permission denied
hadoop@master:~$ sudo chmod 777 /usr/local/spark
hadoop@master:~$ ssh node1
Welcome to Ubuntu 14.04.2 LTS (GNU/Linux 3.16.0-30-generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep 23 16:40:31 UTC 2016 System load: 0.08 Processes: 400
Usage of /: 12.2% of 17.34GB Users logged in: 0
Memory usage: 5% IP address for eth0: 192.168.1.201
Swap usage: 0% Graph this data and manage this system at:
https://landscape.canonical.com/ New release '16.04.1 LTS' available.
Run 'do-release-upgrade' to upgrade to it. Last login: Wed Sep 21 16:19:25 2016 from master
hadoop@node1:~$ cd /usr/local/
hadoop@node1:/usr/local$ sudo mkdir spark
[sudo] password for hadoop:
hadoop@node1:/usr/local$ ls
bin etc games hadoop include lib man sbin share spark src
hadoop@node1:/usr/local$ sudo chmod 777 ./spark
hadoop@node1:/usr/local$ exit
hadoop@master:~$ scp -r /usr/local/spark hadoop@node1:/usr/local
...........
hadoop@master:~$ ssh node2
Welcome to Ubuntu 14.04.2 LTS (GNU/Linux 3.16.0-30-generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep 23 16:15:03 UTC 2016 System load: 0.08 Processes: 435
Usage of /: 13.0% of 17.34GB Users logged in: 0
Memory usage: 6% IP address for eth0: 192.168.1.202
Swap usage: 0% Graph this data and manage this system at:
https://landscape.canonical.com/ Last login: Wed Sep 21 16:19:47 2016 from master
hadoop@node2:~$ cd /usr/local
hadoop@node2:/usr/local$ sudo mkdir spark
[sudo] password for hadoop:
hadoop@node2:/usr/local$ sudo chmod 777 ./spark
hadoop@node2:/usr/local$ exit
logout
Connection to node2 closed.
hadoop@master:~$ scp -r /usr/local/spark hadoop@node2:/usr/local
...........
2、修改所有salves节点(node1、node2)上/etc/profile,追加$SPARK_HOME环境变量:
注意:一般都会遇到权限问题。最好登录到各个salves节点(node1、node2)上手动编辑/etc/profile。
hadoop@master:~$ ssh node1
Welcome to Ubuntu 14.04.2 LTS (GNU/Linux 3.16.0-30-generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep 23 16:42:44 UTC 2016 System load: 0.01 Processes: 400
Usage of /: 12.2% of 17.34GB Users logged in: 0
Memory usage: 5% IP address for eth0: 192.168.1.201
Swap usage: 0% Graph this data and manage this system at:
https://landscape.canonical.com/ New release '16.04.1 LTS' available.
Run 'do-release-upgrade' to upgrade to it. Last login: Fri Sep 23 16:40:52 2016 from master
hadoop@node1:~$ sudo vim /etc/profile
[sudo] password for hadoop:
hadoop@node1:~$ exit
logout
Connection to node1 closed.
hadoop@master:~$ ssh node2
Welcome to Ubuntu 14.04.2 LTS (GNU/Linux 3.16.0-30-generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep 23 16:44:42 UTC 2016 System load: 0.0 Processes: 400
Usage of /: 13.0% of 17.34GB Users logged in: 0
Memory usage: 5% IP address for eth0: 192.168.1.202
Swap usage: 0% Graph this data and manage this system at:
https://landscape.canonical.com/ New release '16.04.1 LTS' available.
Run 'do-release-upgrade' to upgrade to it. Last login: Fri Sep 23 16:43:31 2016 from master
hadoop@node2:~$ sudo vim /etc/profile
[sudo] password for hadoop:
hadoop@node2:~$ exit
logout
Connection to node2 closed.
hadoop@master:~$
修改后的所有salves上/etc/profile文件与master节点上/etc/profile文件配置一致。
- 在Master启动spark并验证是否配置成功:
1、启动命令:
一般要确保hadoop已经启动,之后才启动spark
hadoop@master:~$ cd /usr/local/spark/
hadoop@master:/usr/local/spark$ ./sbin/start-all.sh
2、验证是否启动成功:
方法一、jps
hadoop@master:/usr/local/spark$ ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master--master.out
192.168.1.201: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker--node1.out
192.168.1.202: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker--node2.out
hadoop@master:/usr/local/spark$ jps
NameNode
SecondaryNameNode
Jps
ResourceManager
Master
hadoop@master:/usr/local/spark$ cd ~/
hadoop@master:~$ ssh node1
Welcome to Ubuntu 14.04. LTS (GNU/Linux 3.16.--generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep :: UTC System load: 0.06 Processes:
Usage of /: 13.9% of .34GB Users logged in:
Memory usage: % IP address for eth0: 192.168.1.201
Swap usage: % Graph this data and manage this system at:
https://landscape.canonical.com/ New release '16.04.1 LTS' available.
Run 'do-release-upgrade' to upgrade to it. Last login: Fri Sep :: from master
hadoop@node1:~$ jps
1392 DataNode
2449 Jps
2330 Worker
2079 NodeManager
hadoop@node1:~$ exit
logout
Connection to node1 closed.
hadoop@master:~$ ssh node2
Welcome to Ubuntu 14.04. LTS (GNU/Linux 3.16.--generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep :: UTC System load: 0.07 Processes:
Usage of /: 14.7% of .34GB Users logged in:
Memory usage: % IP address for eth0: 192.168.1.202
Swap usage: % Graph this data and manage this system at:
https://landscape.canonical.com/ New release '16.04.1 LTS' available.
Run 'do-release-upgrade' to upgrade to it. Last login: Fri Sep :: from master
hadoop@node2:~$ jps
Worker
NodeManager
DataNode
Jps
hadoop@node2:~$
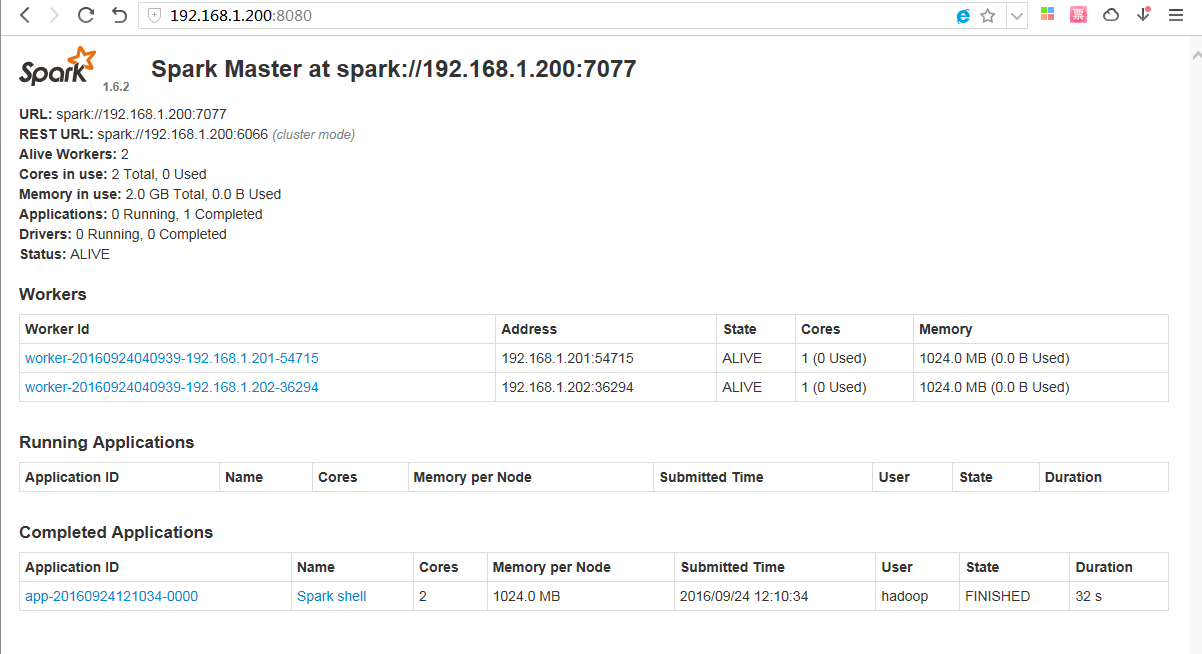
方法二、web方式http://192.168.1.200:8080看是否正常:
Hadoop+Spark:集群环境搭建的更多相关文章
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- Spark 集群环境搭建
思路: ①先在主机s0上安装Scala和Spark,然后复制到其它两台主机s1.s2 ②分别配置三台主机环境变量,并使用source命令使之立即生效 主机映射信息如下: 192.168.32.100 ...
- Spark集群环境搭建——部署Spark集群
在前面我们已经准备了三台服务器,并做好初始化,配置好jdk与免密登录等.并且已经安装好了hadoop集群. 如果还没有配置好的,参考我前面两篇博客: Spark集群环境搭建--服务器环境初始化:htt ...
- Spark集群环境搭建——服务器环境初始化
Spark也是属于Hadoop生态圈的一部分,需要用到Hadoop框架里的HDFS存储和YARN调度,可以用Spark来替换MR做分布式计算引擎. 接下来,讲解一下spark集群环境的搭建部署. 一. ...
- Hadoop、Spark 集群环境搭建问题汇总
Hadoop 问题1: Hadoop Slave节点 NodeManager 无法启动 解决方法: yarn-site.xml reducer取数据的方式是mapreduce_shuffle 问题2: ...
- Hadoop、Spark 集群环境搭建
1.基础环境搭建 1.1运行环境说明 1.1.1硬软件环境 主机操作系统:Windows 64位,四核8线程,主频3.2G,8G内存 虚拟软件:VMware Workstation Pro 虚拟机操作 ...
- Hadoop,HBase集群环境搭建的问题集锦(四)
21.Schema.xml和solrconfig.xml配置文件里參数说明: 參考资料:http://www.hipony.com/post-610.html 22.执行时报错: 23., /comm ...
- hadoop分布式集群环境搭建
参考 http://www.cnblogs.com/zhijianliutang/p/5736103.html 1 wget http://mirrors.shu.edu.cn/apache/hado ...
- Hadoop,HBase集群环境搭建的问题集锦(二)
10.艾玛, Datanode也启动不了了? 找到log: Caused by: java.net.UnknownHostException: Invalid host name: local hos ...
随机推荐
- CF 71C. Round Table Knights
题目链接 很多小的细节都没想到... #include <cstdio> #include <cstring> #include <iostream> #inclu ...
- TC SRM 593 DIV2 1000
很棒的DP,不过没想出,看题解了..思维很重要. #include <iostream> #include <cstdio> #include <cstring> ...
- 获取UILabel宽度的方法
- (CGFloat)labelLength:(NSString *)str font:(CGFloat)font{ str = ISSTRING(str) ? str : @"" ...
- thinkphp遗留问题
$data = array( 'username' => I('username','','htmlspecialchars'), 'content' => I('content'), ' ...
- vue.js中v-for的使用及索引获取
1.v-for 直接上代码. 示例一: <!DOCTYPE html> <html> <head> <meta charset="utf-8&quo ...
- App如何适应 iPhone 5s/6/6 Plus 三种屏幕的尺寸?
来自//www.cocoachina.com/ 初代 iPhone 2007 年,初代 iPhone 发布,屏幕的宽高是 320 x 480 像素.下文也是按照宽度,高度的顺序排列.这个分辨率一直到 ...
- DockerFile 参数详解
Docker 指令: From --- ENV ---设置环境变量ENV App_DIR /appp Add 和 Copy 可以复制文件到容器里面 .区别 Add 可以写网络的链接地址 Add 支持解 ...
- MyBatis的几种批量操作
MyBatis中批量插入 方法一: <insert id="insertbatch" parameterType="java.util.List"> ...
- 【Go语言】I/O专题
本文目录 1.bytes包:字节切片.Buffer和Reader 1_1.字节切片处理函数 1_1_1.基本处理函数 1_1_2.字节切片比较函数 1_1_3.字节切片前后缀检查函数 1_1_4.字节 ...
- Enumerators and Enumerable
Next week task is to learn how generic enumeration interface works, try to build a sample and write ...