hadoop 3.x 单机集群配置/启动时的问题处理
一.修改配置文件(hadoop目录/etc/hadoop/配置文件)
1.修改hadoop-env.sh,指定JAVA_HOME

修改完毕后

2.修改core-site.xml
<configuration>
<!-- 指定hadoop运行时产生的临时文件存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.1/data/tmp</value>
</property> <!-- 指定hfds namenode的缺省路径,可以是主机/ip :端口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop002:9000</value>
</property>
</configuration>
3.修改hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--配置namenode的web界面-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop002:50070</value>
</property>
</configuration>
到这启动hadoop的基本配置已经完成了(配置完这些已经可以启动hadoop了),下面配置yarn相关的文件
4.修改mapred-site.xml(此配置文件中尽量不要使用中文注释,否则启动的时候会有一个java.lang.RuntimeException: com.ctc.wstx.exc.WstxIOException: Invalid UTF-8 start byte 0xb5 (at char #672, byte #20))
<configuration>
<!-- 使用yarn框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.修改yarn-site.xml(此配置文件中尽量不要使用中文注释,否则启动的时候会有一个java.lang.RuntimeException: com.ctc.wstx.exc.WstxIOException: Invalid UTF-8 start byte 0xb5 (at char #672, byte #20))
<configuration>
<!-- Site specific YARN configuration properties -->
<!--resourcemanager address-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property> <!--reduce-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6.启动
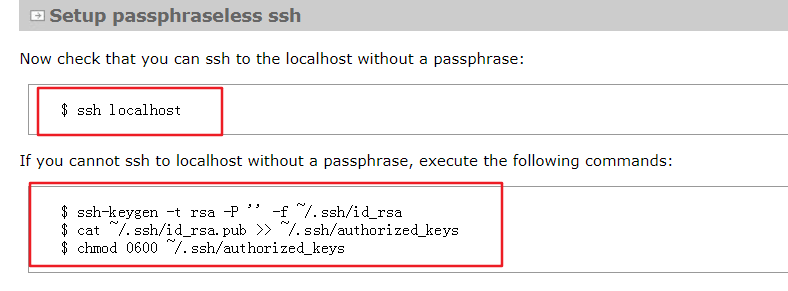
6.1按照官方文档,第一步先检查ssh能否免密登录如果不能免密登录需要执行以下命令
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
如果不能免密且没有执行这三个命令,那么启动时会有Permission Dennied
如果出现ssh connect to host xxx port 22:Connection timed out,ifconfig查看自己的ip与 /etc/hosts下的映射中的ip是否一致
6.2执行hdfs namenode -format格式化namenode,第一次启动时执行即可,今后不再需要
6.3执行start-dfs.sh
6.4执行start-yarn.sh
或者直接执行stop-all.sh
6.5jps查看进程
可以在/tmp/下查看*.pid文件,其内容为上图的进程号
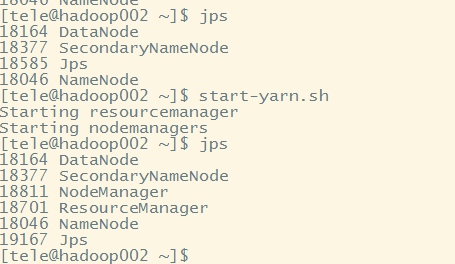
6.6停止的话使用对应的stop-xxx.sh(或者stop-all.sh)即可
到这hadoop已经成功启动了,官方文档:http://hadoop.apache.org/docs/r3.1.1/hadoop-project-dist/hadoop-common/SingleCluster.html
6.7无法停止hadoop
此时虽然已经可以正常启动了,但为了维护方便建议修改pid的路径 ,因为默认把pid文件存储在/tmp/下,而linux会定期清理/tmp/路径一旦pid文件被清理到,此时想执行stop-all.sh后再次jps发现hadoop依然在运行,这个时候想关闭hadoop就只能手动的kill了因此要修改pid的存储路径,打开hadoop目录/etc/hadoop/hadoop-env.sh,找到HADOOP_PID_DIR,修改路径为你自定义的路径即可接下来通过实验证明以上结论

先执行jps,证明此时hadoop并未启动,然后再启动hadoop
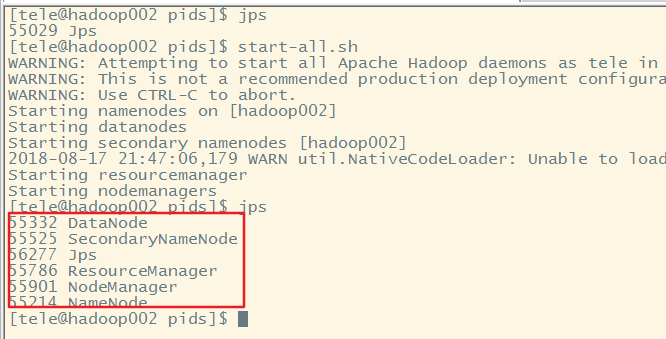
成功启动后查看pid文件后然后删除
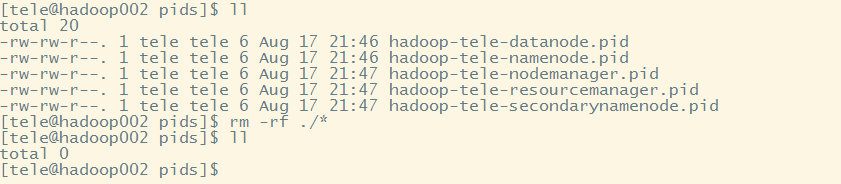
执行stop-all.sh,发现hadoop依然在运行
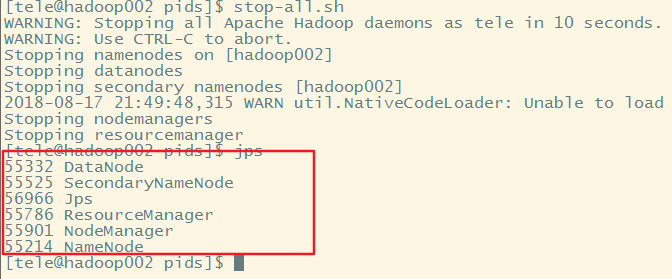
此时重新启动hadoop,发现进程号没有改变,虽然重新生成了pid
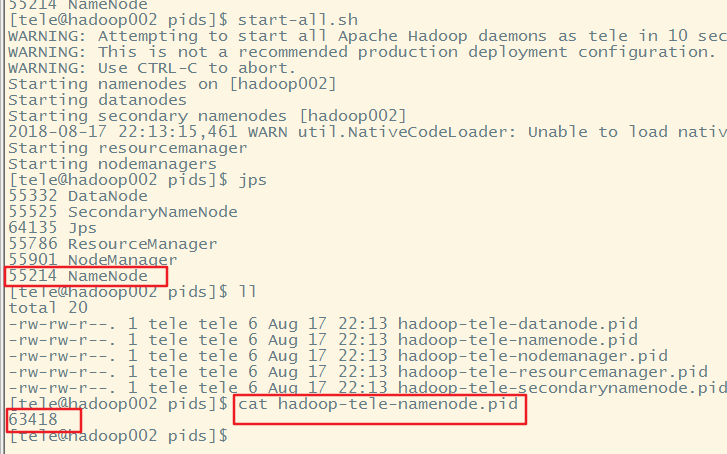
到这说明,一旦hadoop的pid文件被删除想要停止hadoop就只能手动kill,而且如果hadoop没有停止掉,又重新启动了hadoop,此时虽然会生成新的pid,但从进程号上来看依旧是之前没有被停止掉的hadoop
6.8初始化时出现Cannot remove/create xxxx

打开你的core-site.xml,如果是在"/"下创建目录最好手动去创建 并且修改属主与组为你启动hadoop的用户
sudo mkdir -p /hadoop/tmp
sudo chown -R tele:tele /hadoop/
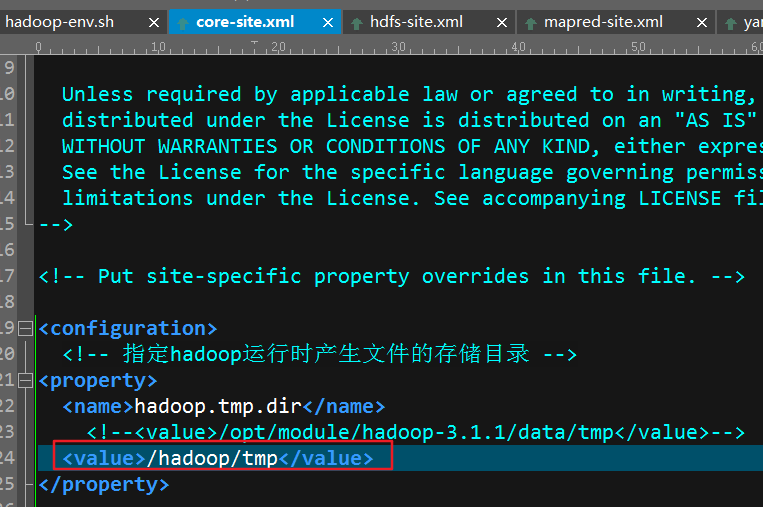
创建并且修改完成后重新初始化即可,如果不是在"/"直接创建文件夹,那么就可以交给hadoop自动创建属主为启动hadoop的用户的文件夹了初始化之后如果启动hadoop,发现没有datanode,在你指定的tmp路径/dfs/name目录下找到一个current/VERSION文件,记录clusterID并复制。然后dfs/data目录下找到一个current/VERSION文件,将其中clustreID的值替换成刚刚复制的clusterID的值后重新启动即可
hadoop 3.x 单机集群配置/启动时的问题处理的更多相关文章
- Hadoop(25)-高可用集群配置,HDFS-HA和YARN-HA
一. HA概述 1. 所谓HA(High Available),即高可用(7*24小时不中断服务). 2. 实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制:HDFS的HA ...
- hadoop之完全分布式集群配置(centos7)
一.基础环境 现在我们有两台虚拟机了,再克隆两台: 克隆好之后需要做三件事:1.更改主机名称 2.修改ip地址 3.将ip地址和对应的主机号加入到/etc/hosts文件中 1.永久修改主机名 hos ...
- Hadoop的多节点集群详细启动步骤(3或5节点)
版本1 利用自己写的脚本来启动,见如下博客 hadoop-2.6.0-cdh5.4.5.tar.gz(CDH)的3节点集群搭建 hadoop-2.6.0.tar.gz的集群搭建(3节点) hadoop ...
- Eureka单机&集群配置
目录 Eureka是什么 自我保护机制 版本选择 服务搭建 创建项目 导入GAV坐标 application启动类添加注解 配置yml 启动项目 集群配置 修改上面的yml 打jar包到另外一台电脑O ...
- Hadoop学习11--Ha集群配置启动
理论知识: http://www.tuicool.com/articles/jameeqm 这篇文章讲的非常详细了: http://www.tuicool.com/articles/jameeqm 以 ...
- debian下 Hadoop 1.0.4 集群配置及运行WordCount
说明:我用的是压缩包安装,不是安装包 官网安装说明:http://hadoop.apache.org/docs/r1.1.2/cluster_setup.html,繁冗,看的眼花...大部分人应该都不 ...
- hadoop分布式安装及其集群配置笔记
各机器及角色信息: 共10台机器,hostname与ip地址映射在此不做赘述.此为模拟开发环境安装,所以不考虑将NameNode和SecondaryNameNode安装在同一台机器. 节点 角色 na ...
- hadoop(四): 本地 hbase 集群配置 Azure Blob Storage
基于 HDP2.4安装(五):集群及组件安装 创建的hadoop集群,修改默认配置,将hbase 存储配置为 Azure Blob Storage 目录: 简述 配置 验证 FAQ 简述: hadoo ...
- Hadoop HA on Yarn——集群配置
集群搭建 因为服务器数量有限,这里服务器开启的进程有点多: 机器名 安装软件 运行进程 hadoop001 Hadoop,Zookeeper NameNode, DFSZKFailoverContro ...
随机推荐
- SpringMVC之类型转换Converter
(转载:http://blog.csdn.net/renhui999/article/details/9837897) 1.1 目录 1.1 目录 1.2 前言 1.3 ...
- 1.3 Python基础知识 - 用户交互及传递参数
一.用户交互 用户交互方面,每种开发语言都有不同的方式,例如shell语言用的是,“read -p "What is your name ? " ”.python中是什么样子的呢 ...
- [React Intl] Render Content with Markup Using react-intl FormattedHTMLMessage
In this lesson, we’ll use the react-intl FormattedHTMLMessage component to display text with dynamic ...
- 使用BeautifulSoup爬取“0daydown”站点的信息(2)——字符编码问题解决
上篇中的程序实现了抓取0daydown最新的10页信息.输出是直接输出到控制台里面.再次改进代码时我准备把它们写入到一个TXT文档中.这是问题就出来了. 最初我的代码例如以下: #-*- coding ...
- log4j 2.x 版本的 properties 配置
#用于设置log4j2自身内部的信息输出,可以不设置,当设置成trace时,会看到log4j2内部各种详细输出status = debugdest = errname = PropertiesConf ...
- UVA 11388 - GCD LCM 水~
看题传送门 题目大意: 输入两个数G,L找出两个正整数a 和b,使得二者的最大公约数为G,最小公倍数为L,如果有多解,输出a<=b且a最小的解,无解则输出-1 思路: 方法一: 显然有G< ...
- LoaderManager使用具体解释(一)---没有Loader之前的世界
来源: http://www.androiddesignpatterns.com/2012/07/loaders-and-loadermanager-background.html 感谢作者Alex ...
- IPv4与IPv6数据报格式详解
摘要: 本文给出IPv4与IPv6数据报格式示意图,并整理了各个字段含义,最后对比IPv4与IPv6数据报格式的区别. 一.IPv4数据报 图1 IPv4数据报格式版本号(version) 不同的IP ...
- 又在折腾cygwin
apt-cyg https://github.com/transcode-open/apt-cyg/blob/master/README.md cygwin 163镜像 http://mirrors. ...
- ORACEL上传BLOB,深度遍历文件夹
// uploadingDlg.cpp : 实现文件// #include "stdafx.h"#include "uploading.h"#include & ...