爬虫系列(四) 用urllib实现英语翻译
这篇文章我们将以 百度翻译 为例,分析网络请求的过程,然后使用 urllib 编写一个英语翻译的小模块
1、准备工作
首先使用 Chrome 浏览器打开 百度翻译,这里,我们选择 Chrome 浏览器自带的开发者工具对网站进行抓包分析
2、抓包分析
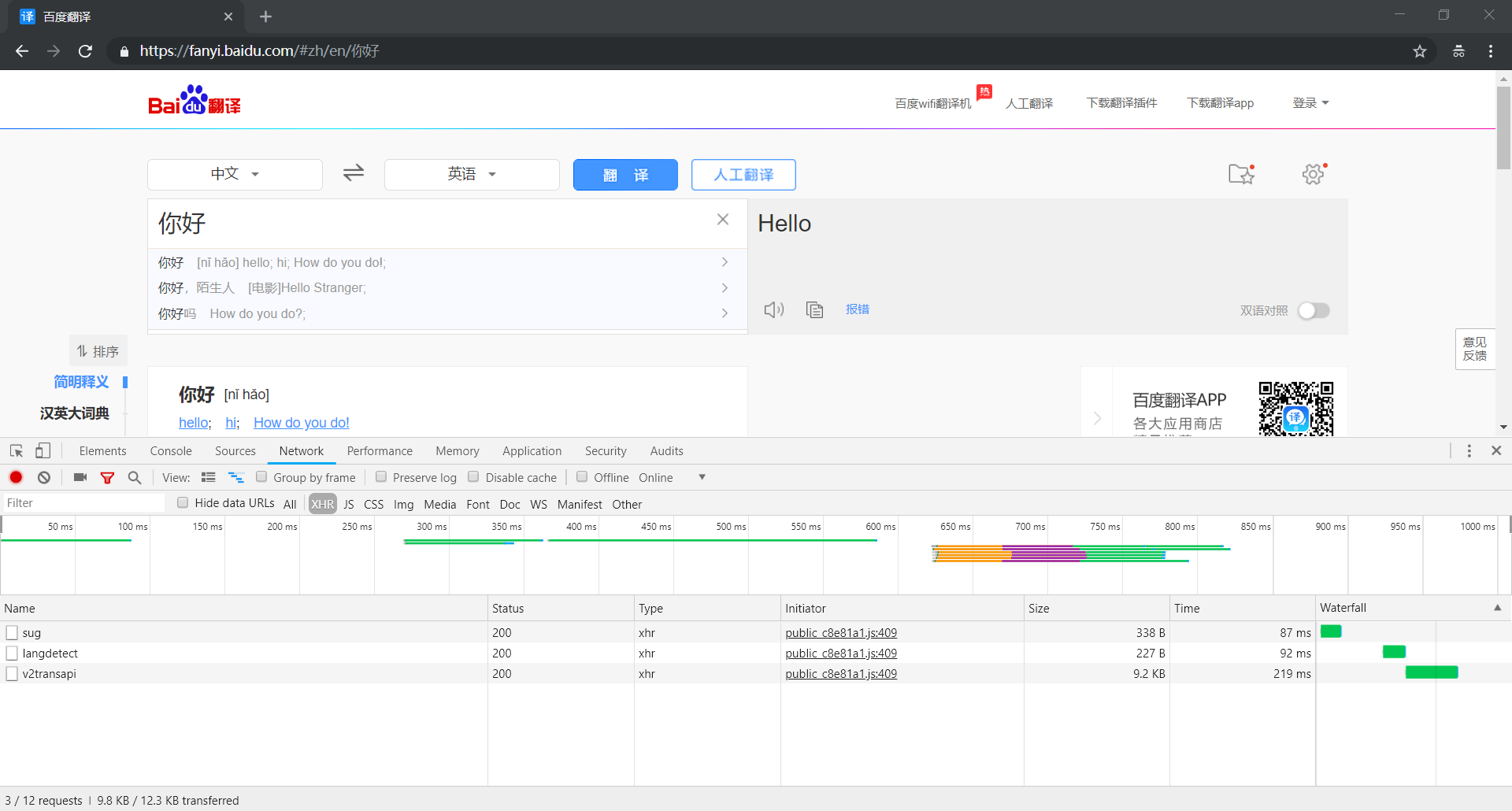
打开 Network 选项卡进行监控,并选择 XHR 作为 Filter 进行过滤
然后,我们在输入框中输入待翻译的文字进行测试,可以看到列表中出现三个数据包
分别是 sug、v2transapi 和 langdetect,下面我们一个一个进行分析
(1)分析 sug 数据包
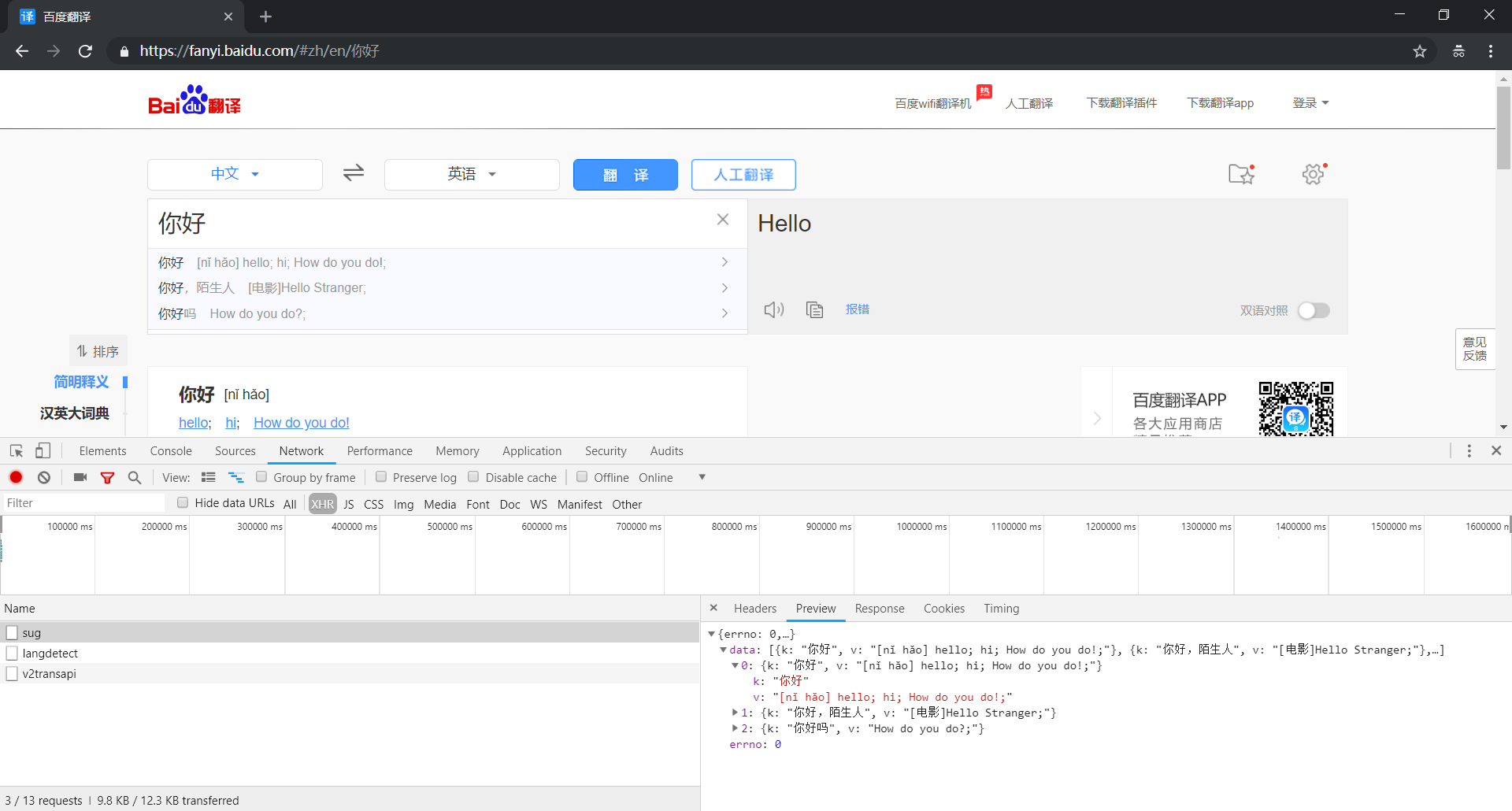
① 打开 sug 数据包的 Preview 选项卡查看响应结果,太棒了,里面有我们需要的翻译结果
② 然后,我们可以打开 sug 数据包的 Headers 选项卡分析请求数据,使用程序模拟发送请求,基本信息如下:
- General:基本参数
Request URL : https://fanyi.baidu.com/sug—— 请求网址Request Method : POST—— 请求方法,POST 请求方法的请求参数放在 Form Data 中
- Request Headers:请求头部
User-Agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36—— 用户代理
- Form Data:表单数据
kw : 你好—— 翻译的内容
③ 下面祭上完整的代码
import urllib.request
import urllib.parse
import json
def translate(text):
# 参数检验
if not text:
return 'None'
# 请求网址
url = "https://fanyi.baidu.com/sug"
# 表单数据
params = {
'kw':text
}
data = urllib.parse.urlencode(params).encode('utf-8')
# 请求头部
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 构造请求对象
req = urllib.request.Request(url=url,data=data,headers=headers)
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 解析数据
content = json.loads(response.read().decode('utf-8'))
if content['errno'] == 0: # 一切正常
result = content['data'][0]['v']
else: # 发生错误
result = 'Error'
# 返回结果
return result
if __name__ == "__main__":
while True :
text = input('翻译内容:')
result = translate(text)
print("翻译结果:%s" % result)
OK,一切完美解决!
等等,真的就这样结束了吗?
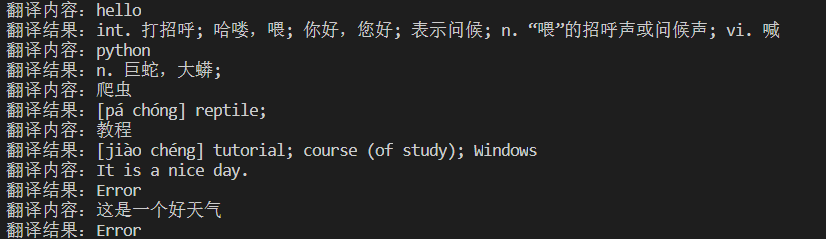
可以看到,上面的代码虽然可以完美翻译中文和英文,但是却不能翻译句子!
这可怎么办呀?别急,不是还有两个数据包没有分析嘛,再看看还有没有其它办法吧
(2)分析 v2transapi 数据包
① 打开 v2transapi 数据包的 Preview 选项卡查看响应结果,这里面竟然也有我们需要的翻译结果
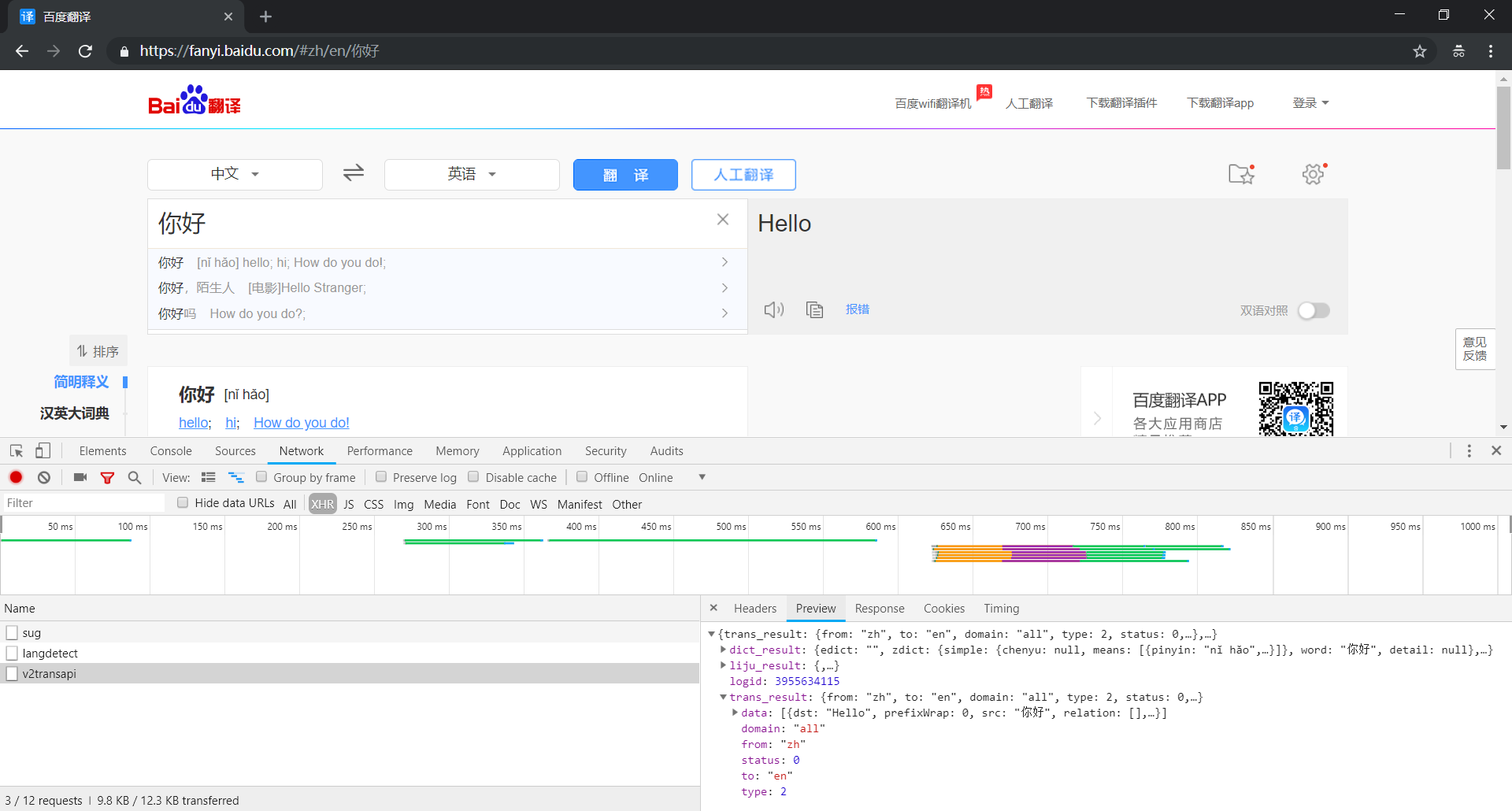
② 接下来,我们还是打开 v2transapi 数据包的 Headers 选项卡查看请求数据,其基本信息如下:
- General:基本参数
Request URL : https://fanyi.baidu.com/v2transapi—— 请求网址Request Method : POST—— 请求方法,POST 请求方法的请求参数放在 Form Data 中
- Request Headers:请求头部
User-Agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36—— 用户代理
- Form Data:表单数据
query : 你好—— 翻译的内容from : zh—— 翻译内容的语言类型,zh 代表中文,设置为 auto 可自动检测to : en—— 翻译结果的语言类型,en 代表英文,设置为 auto 可自动检测sign和token:加密参数
唉,只想简简单单爬个翻译,竟然还要涉及密码破解,没办法,只好请教百度了
一查才知道,原来百度翻译有一个公开的 API,根本就不需要涉及加密解密
只需要把上面的请求地址改成 https://fanyi.baidu.com/transapi 就可以了
③ 下面同样祭上完整的代码,其实和上面的十分类似
import urllib.request
import urllib.parse
import json
def translate(text):
# 参数检验
if not text:
return 'None'
# 请求网址
url = "https://fanyi.baidu.com/transapi"
# 表单数据
params = {
'query':text,
'from':'auto',
'to':'auto'
}
data = urllib.parse.urlencode(params).encode('utf-8')
# 请求头部
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 构造请求对象
req = urllib.request.Request(url=url,data=data,headers=headers)
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 解析数据
content = json.loads(response.read().decode('utf-8'))
result = content['data'][0]['dst']
# 返回结果
return result
if __name__ == "__main__":
while True :
text = input('翻译内容:')
result = translate(text)
print("翻译结果:%s" % result)
下面我们来看看效果如何?

嗯,效果还可以,终于也能够翻译句子了!
3、相关拓展
有道翻译的爬取和百度翻译的十分类似,这里也顺便提及一下
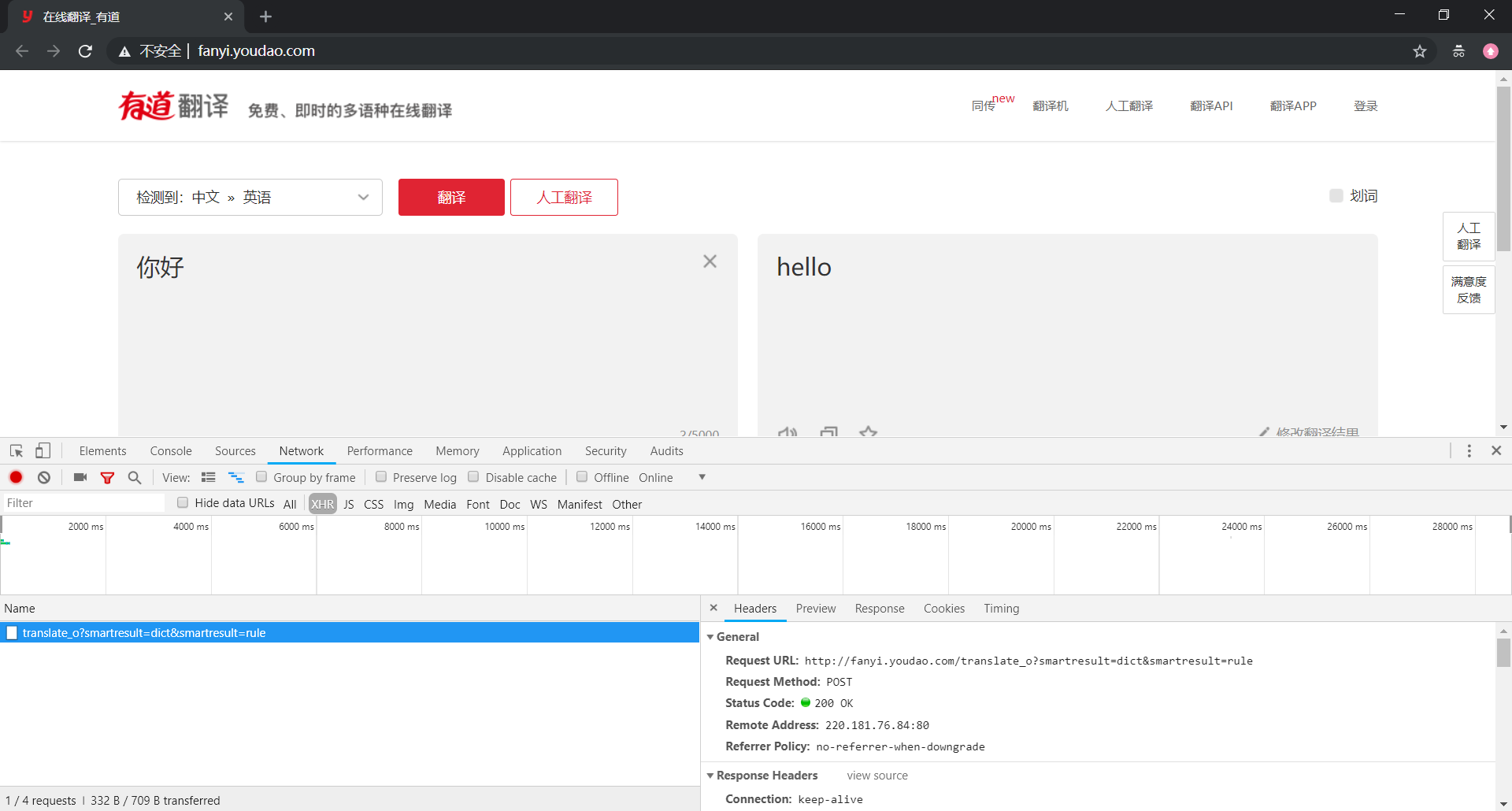
我们还是先来打开数据包的 Headers 选项卡查看请求数据,其基本信息如下:
- General:基本参数
Request URL : http://fanyi.youdao.com/translate_o—— 请求网址Request Method : POST—— 请求方法,POST 请求方法的请求参数放在 Form Data 中
- Request Headers:请求头部
User-Agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36—— 用户代理
- Form Data:表单数据
i: 你好—— 翻译的内容doctype : json—— 数据类型,指定为 JSONfrom : AUTO—— 翻译内容的语言类型,自动检测to : AUTO—— 翻译结果的语言类型,自动检测sign和salt:加密参数
和百度翻译的很类似,都设置了加密参数,怎么办?也和百度翻译类似,修改一下请求地址就好
话不多说,直接放代码:
import urllib.request
import urllib.parse
import json
def translate(text):
# 参数检验
if not text:
return 'None'
# 请求网址
url = "https://fanyi.youdao.com/translate"
# 表单数据
params = {
'i':text,
'doctype':'json',
'from':'AUTO',
'to':'AUTO'
}
data = urllib.parse.urlencode(params).encode('utf-8')
# 请求头部
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 构造请求对象
req = urllib.request.Request(url=url,data=data,headers=headers)
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 解析数据
content = json.loads(response.read().decode('utf-8'))
if content['errorCode'] == 0: # 一切正常
result_tup = (item['tgt'] for item in content['translateResult'][0])
result = ''.join(result_tup)
else: # 发生错误
result = 'Error'
# 返回结果
return result
if __name__ == "__main__":
while True :
text = input('翻译内容:')
result = translate(text)
print("翻译结果:%s" % result)
效果演示:

【爬虫系列相关文章】
爬虫系列(四) 用urllib实现英语翻译的更多相关文章
- 爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图 1.网页分析 (1)准备工作 首先我们使用 Chrome 浏览器打开 百度贴吧,在输入 ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- Java爬虫系列四:使用selenium-java爬取js异步请求的数据
在之前的系列文章中介绍了如何使用httpclient抓取页面html以及如何用jsoup分析html源文件内容得到我们想要的数据,但是有时候通过这两种方式不能正常抓取到我们想要的数据,比如看如下例子. ...
- 4.Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 爬虫系列(三) urllib的基本使用
一.urllib 简介 urllib 是 Python3 中自带的 HTTP 请求库,无需复杂的安装过程即可正常使用,十分适合爬虫入门 urllib 中包含四个模块,分别是 request:请求处理模 ...
- 爬虫系列(九) xpath的基本使用
一.xpath 简介 究竟什么是 xpath 呢?简单来说,xpath 就是一种在 XML 文档中查找信息的语言 而 XML 文档就是由一系列节点构成的树,例如,下面是一份简单的 XML 文档: &l ...
- 爬虫系列(二) Chrome抓包分析
在这篇文章中,我们将尝试使用直观的网页分析工具(Chrome 开发者工具)对网页进行抓包分析,更加深入的了解网络爬虫的本质与内涵 1.测试环境 浏览器:Chrome 浏览器 浏览器版本:67.0.33 ...
- 爬虫系列(五) re的基本使用
1.简介 究竟什么是正则表达式 (Regular Expression) 呢?可以用下面的一句话简单概括: 正则表达式是一组特殊的 字符序列,由一些事先定义好的字符以及这些字符的组合形成,常常用于 匹 ...
随机推荐
- 利用keepalive和timeout来推断死连接
问题是这样出现的. 操作:client正在向服务端请求数据的时候,突然拔掉client的网线. 现象:client死等.服务端socket一直存在. 在网上搜索后,须要设置KEEPALIVE属性. 于 ...
- MyBatis对数据库的增删改查操作,简单演示样例
之前一直有用Hibernate进行开发.近期公司在使用Mybatis.依据网上的演示样例,做了一个简单的Demo,以便日后复习 使用XMl方式映射sql语句 整体结构例如以下图 watermark/2 ...
- 升级DM5校验
1,将某个文件生成带DM5的文件,使用srec_cat工具: read A #原始文件 srec_cat $A -o 要生成的文件名称 -Line_Length 46 -Address_Leng ...
- HDU5195 线段树+拓扑
DZY Loves Topological Sorting Problem Description A topological sort or topological ordering of a di ...
- 20170322js面向对象
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- bzoj4737: 组合数问题
终于过了肝了一天啊,怎么我最近都在做细节码农题啊 (这种水平NOIP凉凉??) luacs大家都可以想到用吧,一开始我的思路是把所有在p以内的%p==0的组合数预处理出来,那C(n/p,m/p)任取, ...
- Android+Jquery Mobile学习系列(7)-保险人信息
[保险人管理]是这个APP最重要的功能,用于保存保险客户的数据,给后面的功能提供数据支撑. 简单说说[保险人管理]功能:主要就是增.删.改.查四个功能,在新增和修改的时候不仅可以保存保险人的姓名.身份 ...
- myeclipse视图布局恢复
使用Windows 菜单下的 Reset Perspective
- Java 精度控制
四舍五入,保留两位小数 (找了很多种方法,都有问题,测试得出下面这种方式是可用的) String str="0.235"; String.format("%.2f&quo ...
- ES6 Template String 模板字符串
模板字符串(Template String)是增强版的字符串,用反引号(`)标识,它可以当作普通字符串使用,也可以用来定义多行字符串,或者在字符串中嵌入变量. 大家可以先看下面一段代码: $(&quo ...