4.Python爬虫入门四之Urllib库的高级用法
1.设置Headers
有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性。
首先,打开我们的浏览器,调试浏览器F12,我用的是Chrome,打开网络监听,示意如下,比如知乎,点登录之后,我们会发现登陆之后界面都变化了,出现一个新的界面,实质上这个页面包含了许许多多的内容,这些内容也不是一次性就加载完成的,实质上是执行了好多次请求,一般是首先请求HTML文件,然后加载JS,CSS 等等,经过多次请求之后,网页的骨架和肌肉全了,整个网页的效果也就出来了。
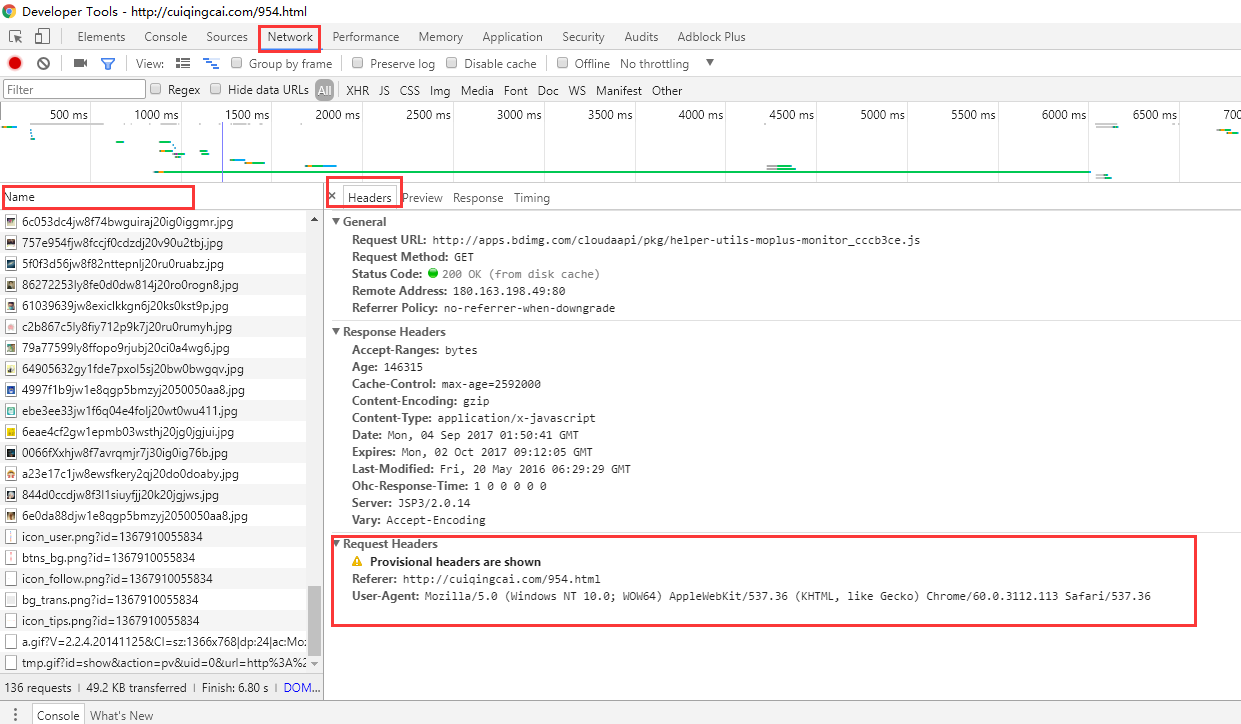
拆分这些请求,我们只看一第一个请求,你可以看到,有个Request URL,还有headers,下面便是response,图片显示得不全,小伙伴们可以亲身实验一下。那么这个头中包含了许许多多是信息,有文件编码啦,压缩方式啦,请求的agent啦等等。
其中,agent就是请求的身份,如果没有写入请求身份,那么服务器不一定会响应,所以可以在headers中设置agent,例如下面的例子,这个例子只是说明了怎样设置的headers,小伙伴们看一下设置格式就好。
url = 'http://www.server.com/login'
user_agent = 'Mozilla/4.0(compatible; MSIE 5.5; Windows NT)'
values = {'username':'cqc','password':'xxxxx'}
headers = {'user-Agent':user_agent}
data = urllib.urlencode(values)
request = urllib2.request(url,data,headers)
response = urllib2.urlopen(request)
page = response.read()
这样,我们设置了一个headers,在构建request时传入,在请求时,就加入了headers传送,服务器若识别了是浏览器发来的请求,就会得到响应。
另外,我们还有对付”反盗链”的方式,对付防盗链,服务器会识别headers中的referer是不是它自己,如果不是,有的服务器不会响应,所以我们还可以在headers中加入referer
例如我们可以构建下面的headers

同上面的方法,在传送请求时把headers传入Request参数里,这样就能应付防盗链了。
另外headers的一些属性,下面的需要特别注意一下:
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
其他的有必要的可以审查浏览器的headers内容,在构建时写入同样的数据即可。
2. Proxy(代理)的设置
urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy。假如一个网站它会检测某一段时间某个IP 的访问次数,如果访问次数过多,它会禁止你的访问。所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理,网站君都不知道是谁在捣鬼了,这酸爽!
下面一段代码说明了代理的设置用法
enable_proxy = True
proxy_handler = urllib2.ProxyHandler({'http':'http://some-proxy.com:8080'})
null_proxy_handler = urllib2.ProxyHandler({})
if enable_proxy:
opener = urllib2.build_opener(proxy_handler)
else:
opener = urllib2.build_opener(null_proxy_handler) urllib2.install_opener(opener)
3.Timeout 设置
上一节已经说过urlopen方法了,第三个参数就是timeout的设置,可以设置等待多久超时,为了解决一些网站实在响应过慢而造成的影响。
例如下面的代码,如果第二个参数data为空那么要特别指定是timeout是多少,写明形参,如果data已经传入,则不必声明。
#timeout设置
response = urllib2.urlopen('http://www.baidu.com',timeout=10)
response1 = urllib2.urlopen('http://www.baidu.com',data,10)
4.使用 HTTP 的 PUT 和 DELETE 方法
http协议有六种请求方法,get,head,put,delete,post,options,我们有时候需要用到PUT方式或者DELETE方式请求。
PUT:这个方法比较少见。HTML表单也不支持这个。本质上来讲, PUT和POST极为相似,都是向服务器发送数据,但它们之间有一个重要区别,PUT通常指定了资源的存放位置,而POST则没有,POST的数据存放位置由服务器自己决定。
DELETE:删除某一个资源。基本上这个也很少见,不过还是有一些地方比如amazon的S3云服务里面就用的这个方法来删除资源。
如果要使用 HTTP PUT 和 DELETE ,只能使用比较低层的 httplib 库。虽然如此,我们还是能通过下面的方式,使 urllib2 能够发出 PUT 或DELETE 的请求,不过用的次数的确是少,在这里提一下。
4.Python爬虫入门四之Urllib库的高级用法的更多相关文章
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
- python爬虫(2)--Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 拆分这些请求,我们只 ...
- 转 Python爬虫入门三之Urllib库的基本使用
静觅 » Python爬虫入门三之Urllib库的基本使用 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器 ...
- python爬虫入门四:BeautifulSoup库(转)
正则表达式可以从html代码中提取我们想要的数据信息,它比较繁琐复杂,编写的时候效率不高,但我们又最好是能够学会使用正则表达式. 我在网络上发现了一篇关于写得很好的教程,如果需要使用正则表达式的话,参 ...
- Python爬虫入门三之Urllib库的基本使用
转自http://cuiqingcai.com/947.html 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由 ...
- python系列:二、Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 打开我们的浏览器,调 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 3.Python爬虫入门三之Urllib和Urllib2库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
随机推荐
- 11月26日11月26日,周日在家practice.基本了解了layouts and Rending (guides); gem font-awesome-rails的实例用法;建立路径route, member..do的实际例子
http://fontawesome.io/examples/ content_tag(:i,"", class:"fa fa-lock fa-spin fa-lg fa ...
- android -------- WIFI 详解
今天简单的来聊一下安卓开发中的Wifi,一些常用的基础,主要分为两部分: 1:WiFi的信息 2:WiFi的搜索和连接 现在app大多都需要从网络上获得数据.所以访问网络是在所难免.但是在访问网络之前 ...
- git 基础知识
git 分布式版本控制系统 git三棵树: 工作目录 红色 等待添加到暂存区域 需执行git add filename 命令添加到暂存区 暂存区域 绿色 文件等待被提交 需执行 git commit ...
- 牛客练习赛41 B-666RPG
题目链接:https://ac.nowcoder.com/acm/contest/373/B 题意:有n个回合,每个回合给1个数,每个回合你有两种选择 1.加上第i个数 2.将当前数乘-1 想知道有多 ...
- Shiro中Realm
6.1 Realm [2.5 Realm]及[3.5 Authorizer]部分都已经详细介绍过Realm了,接下来再来看一下一般真实环境下的Realm如何实现. 1.定义实体及关系 即用户-角色 ...
- python-day76--django-Form组件
django中Form组件 1. 用户请求数据验证 2. 自动生成错误信息 3. 打包用户提交正确信息 4. 错误:保留上次输入内容 5. 定制页面上显示的HTML标签 引入: from django ...
- pycharm下打开、执行并调试scrapy爬虫程序
首先得有一个Scrapy项目,我在Desktop上新建一个Scrapy的项目叫test,在Desktop目录打开命令行,键入命令:scrapy startproject test1 目录结构如下: ...
- logmnr使用
logminer 工具的使用 Oracle LogMiner 是Oracle公司从产品8i以后提供的一个实际非常有用的分析工具,使用该工具可以轻松获得Oracle 重作日志文件(归档日志文件)中的具体 ...
- 为什么要使用oath协议?
一.如何查看用户是否登录? 通过cookie和session来查看用户是否登录. 如果cookie对应的session中保存了用户登录信息,则判定用户已登录 Jsessionid,也就是tomcat自 ...
- 使用AJAX报406错误
使用AJAX报406错误,基本有一下两种情况: (1)90%的可能是没有添加jackson包: (2)10%的可能是请求的url后缀是*.html 在springmvc里面,如果请求的是*.html, ...