python网络数据采集(伴奏曲)
这里是前章,我们做一下预备。之前太多事情没能写博客~。。 (此博客只适合python3x,python2x请自行更改代码)
首先你要有bs4模块
windows下安装:pip3 install bs4,如果你电脑有python2x和python3x的话,在python3x中安装bs4请已管理员的身份运行cmd执行pip3 install bs4安装bs4。
linux下安装:sudo pip3 install bs4
还有urllib.request模块
windows下安装:pip3 install urllib.request,如果你电脑有python2x和python3x的话,在python3x中安装bs4请已管理员的身份运行cmd执行pip3 install urllib.request安装urllib.request模块
例子1:获取源码
from urllib.request import urlopen
from bs4 import BeautifulSoup
html=urlopen("http://wikipedia.org")
dgc=BeautifulSoup(html)
print(dgc)
输出图如下:
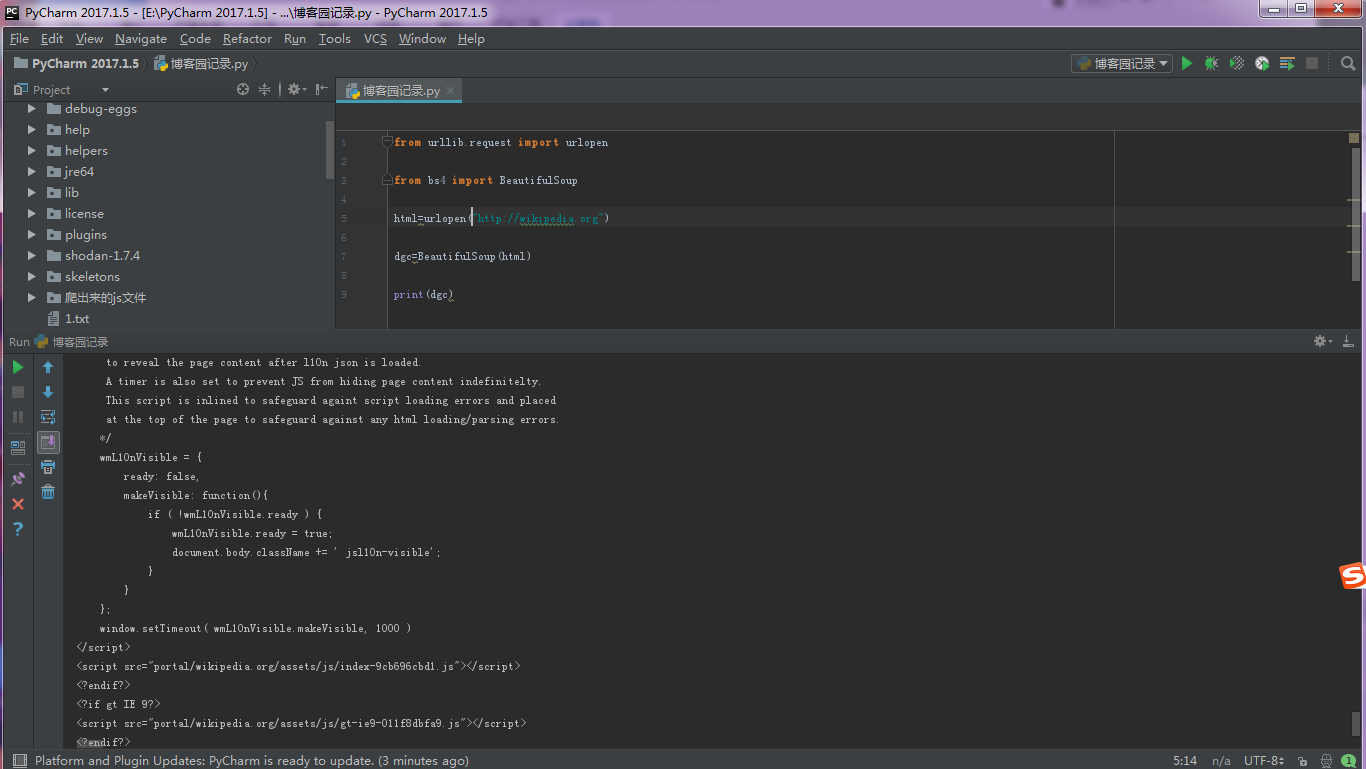
这里我忘记加自定义错误了,当然你也可以不加。保险起见还是加
例子二:匹配对应的标签
from urllib.request import urlopen from bs4 import BeautifulSoup
try:
html=urlopen("http://dlszx.dgjy.net/")
except EOFError as a:
print("404 ")
except:
print("404")
dgc=BeautifulSoup(html)
fbc=dgc.findAll("img",{"src":"uploadfile/201762105219962.jpg"})
print(fbc)
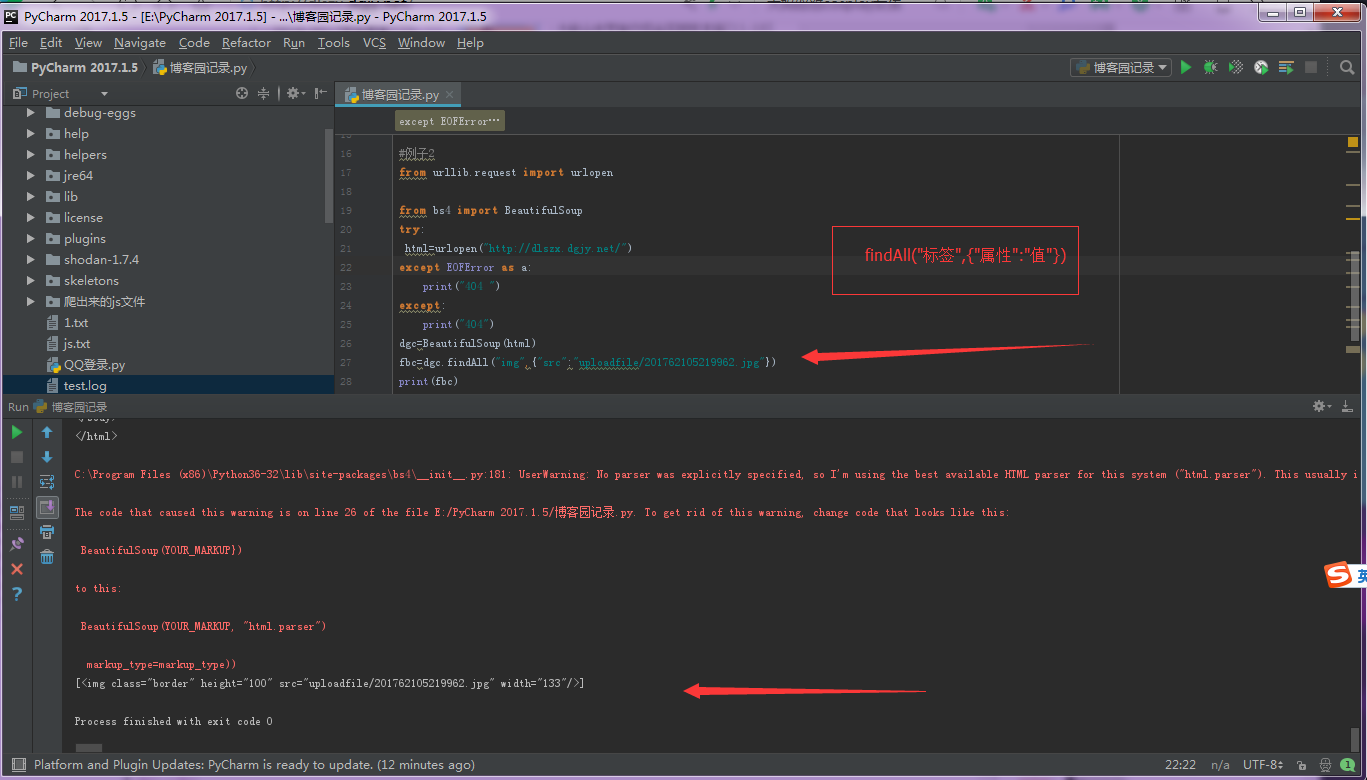
例子3:正则匹配所有对应的标签
不会正则的请去学习
from urllib.request import urlopen
import re
from bs4 import BeautifulSoup
try:
html=urlopen("http://dlszx.dgjy.net/")
except EOFError as a:
print("404 ")
except:
print("404")
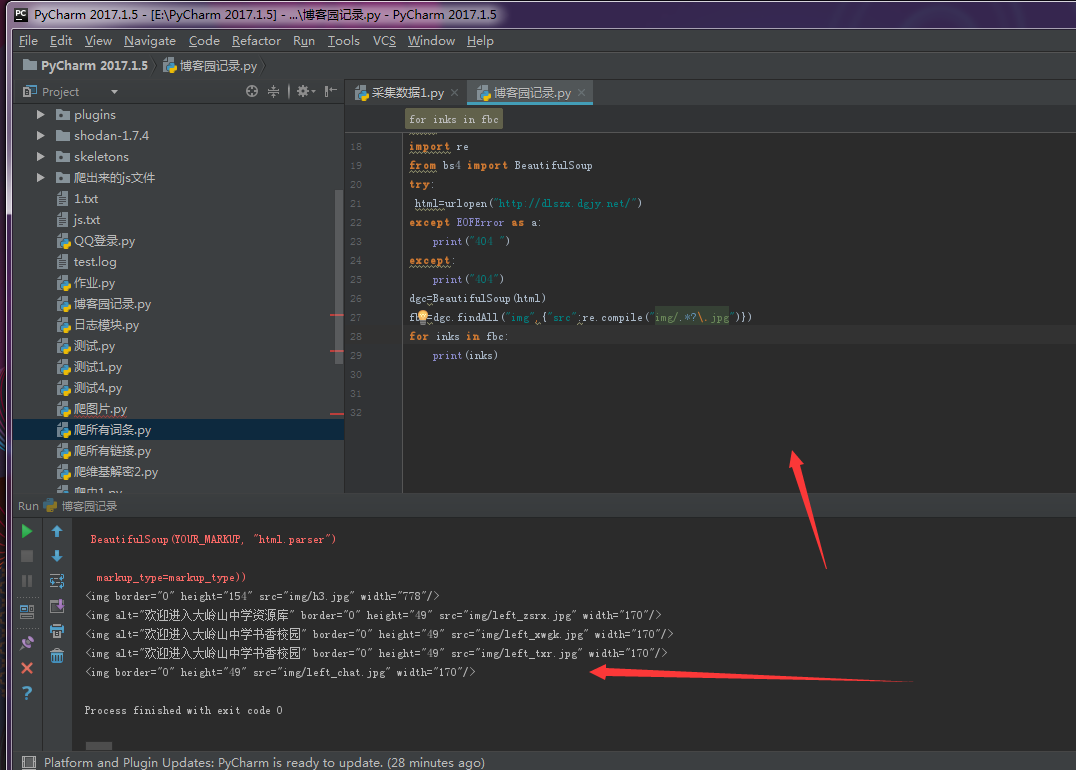
dgc=BeautifulSoup(html)
fbc=dgc.findAll("img",{"src":re.compile("img/.*?\.jpg")})
for inks in fbc:
print(inks)
注意事项!!!:不要拿findAll去搜索引擎匹配,乱的你想死
搜索引擎正则匹配要求很高:http:\/\/[a-zA-z].*?\[a-z]
例子4:
匹配网站所有的链接
from urllib.request import urlopen
import re
from bs4 import BeautifulSoup
try:
html=urlopen("http://wikipeda.org")
except EOFError as a:
print("EOFError")
except:
print("I dont EOFError")
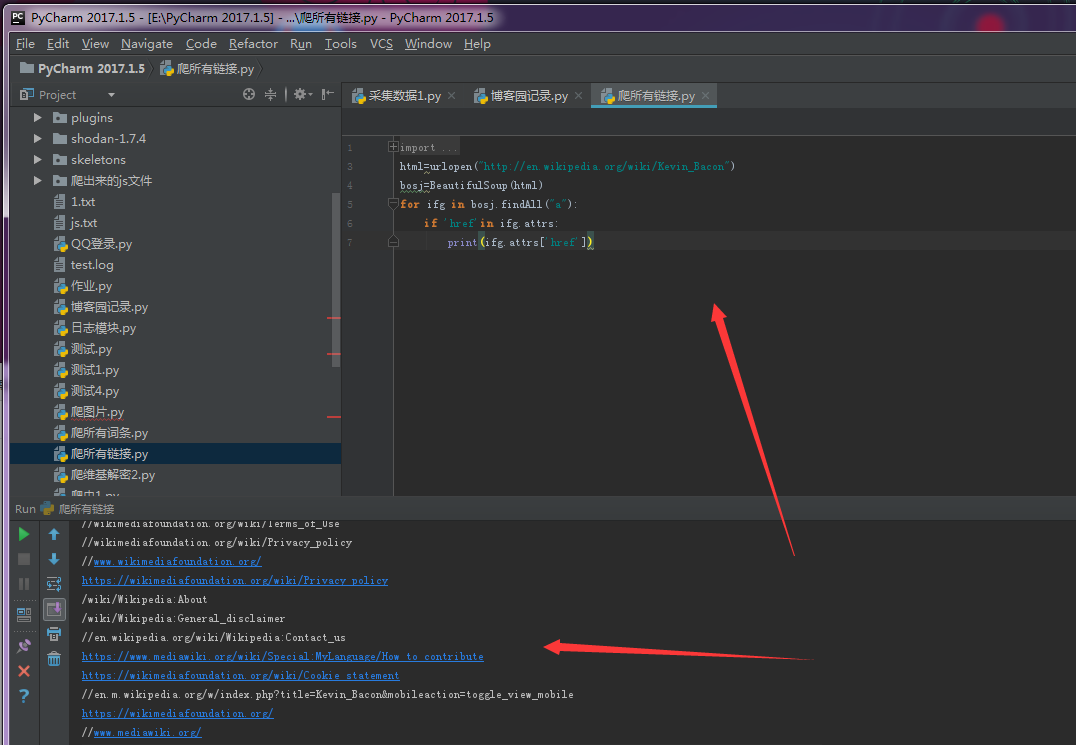
gfc=BeautifulSoup(html)
for inks in gfc.findAll("a")
if 'href' in inks.attrs:
print("inks.attrs["href"]")
现在的时间是
2017-8-13-13:38
python网络数据采集(伴奏曲)的更多相关文章
- 笔记之Python网络数据采集
笔记之Python网络数据采集 非原创即采集 一念清净, 烈焰成池, 一念觉醒, 方登彼岸 网络数据采集, 无非就是写一个自动化程序向网络服务器请求数据, 再对数据进行解析, 提取需要的信息 通常, ...
- Python网络数据采集7-单元测试与Selenium自动化测试
Python网络数据采集7-单元测试与Selenium自动化测试 单元测试 Python中使用内置库unittest可完成单元测试.只要继承unittest.TestCase类,就可以实现下面的功能. ...
- Python网络数据采集6-隐含输入字段
Python网络数据采集6-隐含输入字段 selenium的get_cookies可以轻松获取所有cookie. from pprint import pprint from selenium imp ...
- Python网络数据采集4-POST提交与Cookie的处理
Python网络数据采集4-POST提交与Cookie的处理 POST提交 之前访问页面都是用的get提交方式,有些网页需要登录才能访问,此时需要提交参数.虽然在一些网页,get方式也能提交参.比如h ...
- Python网络数据采集3-数据存到CSV以及MySql
Python网络数据采集3-数据存到CSV以及MySql 先热热身,下载某个页面的所有图片. import requests from bs4 import BeautifulSoup headers ...
- Python网络数据采集2-wikipedia
Python网络数据采集2-wikipedia 随机链接跳转 获取维基百科的词条超链接,并随机跳转.可能侧边栏和低栏会有其他链接.这不是我们想要的,所以定位到正文.正文在id为bodyContent的 ...
- Python网络数据采集1-Beautifulsoup的使用
Python网络数据采集1-Beautifulsoup的使用 来自此书: [美]Ryan Mitchell <Python网络数据采集>,例子是照搬的,觉得跟着敲一遍还是有作用的,所以记录 ...
- Python网络数据采集PDF
Python网络数据采集(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/16c4GjoAL_uKzdGPjG47S4Q 提取码:febb 复制这段内容后打开百度网盘手 ...
- python网络数据采集的代码
python网络数据采集的代码 https://github.com/REMitchell/python-scraping
- [python] 网络数据采集 操作清单 BeautifulSoup、Selenium、Tesseract、CSV等
Python网络数据采集操作清单 BeautifulSoup.Selenium.Tesseract.CSV等 Python网络数据采集操作清单 BeautifulSoup.Selenium.Tesse ...
随机推荐
- 【CSS3】字体font
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- 33 款主宰 2017 iOS 开发的开源库
推荐一篇文章 改文章汇聚了现在主流的一些三方框架,很值得一看 https://mp.weixin.qq.com/s/ICodliohtzbmA-eLKRFT-Q
- Memcached的简介和使用
缘起: 在数据驱动的web开发中,经常要重复从数据库中取出相同的数据,这种重复极大的增加了数据库负载.缓存是解决这个问题的好办法.但是ASP.NET中的虽然已经可以实现对页面局部进行缓存,但还是不够灵 ...
- 随手记一下,VS2015卡顿问题解决。
不知道什么开始,vs2015卡顿的很,启动时加载项目很慢,调试是启动慢,停止调试时直接卡死半分钟.其他都还能忍受,最不能忍受的是点击停止调试按钮后十几秒没反应! 网上有解决方案如下几个,我试了,都不行 ...
- Linux发行版 CentOS6.5下的分区操作
本文地址http://comexchan.cnblogs.com/ ,尊重知识产权,转载请注明出处,谢谢! 查询磁盘信息并作分区规划 执行下述命令查询磁盘信息: fdisk -l 可知.数据盘大小50 ...
- jquery中attr和prop的区别分析
这篇文章主要介绍了jquery中attr和prop的区别分析的相关资料,需要的朋友可以参考下 在高版本的jquery引入prop方法后,什么时候该用prop?什么时候用attr?它们两个之间有什么区别 ...
- linux svn up 中文显示乱码解决办法
vi /etc/sysconfig/i18n #LANG="en_US.UTF-8" #LANG=zh_CN.GB18030 #LC_ALL=zh_CN.GB18030 #SYSF ...
- PCA主成份分析
1 背景介绍 真实的训练数据总是存在各种各样的问题: 1. 比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余. 2. ...
- Android动画(一)-视图动画与帧动画
项目中好久没用过动画了,所以关于动画的知识都忘光了.知识总是不用则忘.正好最近的版本要添加比较炫酷的动画效果,所以也借着这个机会,写博客来整理和总结关于动画的一些知识.也方便自己今后的查阅. Andr ...
- Scrum And Teamwork
Scrum Learning 概念 Scrum是迭代式增量软件开发过程,通常用于敏捷软件开发.Scrum包括了一系列实践和预定义角色的过程骨架.Scrum中的主要角色包括同项目经理类似的Scrum主管 ...