Hadoop(十七)之MapReduce作业配置与Mapper和Reducer类
前言
前面一篇博文写的是Combiner优化MapReduce执行,也就是使用Combiner在map端执行减少reduce端的计算量。
一、作业的默认配置
MapReduce程序的默认配置
1)概述
在我们的MapReduce程序中有一些默认的配置。所以说当我们程序如果要使用这些默认配置时,可以不用写。

我们的一个MapReduce程序一定会有Mapper和Reducer,但是我们程序中不写的话,它也有默认的Mapper和Reducer。
当我们使用默认的Mapper和Reducer的时候,map和reducer的输入和输出都是偏移量和数据文件的一行数据,所以就是相当于原样输出!
2)默认的MapReduce程序
/**
* 没有指定Mapper和Reducer的最小作业配置
*/
public class MinimalMapReduce {
public static void main(String[] args) throws Exception{
// 构建新的作业
Configuration conf=new Configuration();
Job job = Job.getInstance(conf, "MinimalMapReduce");
job.setJarByClass(MinimalMapReduce.class);
// 设置输入输出路径
FileInputFormat.addInputPath(job, new Path(args[]));
FileOutputFormat.setOutputPath(job, new Path(args[]));
// ᨀ交作业运行
System.exit(job.waitForCompletion(true)?:);
}
}
输入是:
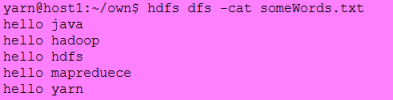
输出是:
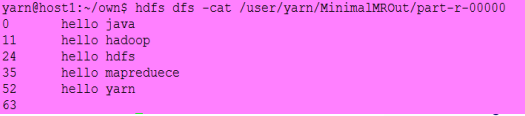
二、作业的配置方式
MapReduce的类型配置
1)用于配置类型的属性


在命令行中,怎么去配置呢?
比如说mapreduce.job.inputformat.class。首先我们要继承Configured实现Tool工具才能这样去指定:
-Dmapreduce.job.inputformat.class = 某一个类的类全名(一定要记得加报名)
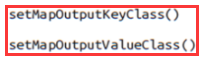 这是Map端的输出类型控制
这是Map端的输出类型控制
 这是整个MapReduce程序输出类型控制,其实就是reduce的类型格式控制
这是整个MapReduce程序输出类型控制,其实就是reduce的类型格式控制
2)No Reducer的MapReduce程序--Mapper
第一步:写一个TokenCounterMapper继承Mapper
/**
* 将输入的文本内容拆分为word,做一个简单输出的Mapper
*/
public class TokenCounterMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private Text word=new Text();
private static final IntWritable one=new IntWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
StringTokenizer itr=new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}
TokenCounterMapper
第二步:写一个NoReducerMRDriver完成作业配置
/**
*没有设置Reducer的MR程序
*/
public class NoReducerMRDriver {
public static void main(String[] args) throws Exception {
// 构建新的作业
Configuration conf=new Configuration();
Job job = Job.getInstance(conf, "NoReducer");
job.setJarByClass(NoReducerMRDriver.class);
// 设置Mapper
job.setMapperClass(TokenCounterMapper.class);
// 设置reducer的数量为0
job.setNumReduceTasks();
// 设置输出格式
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[]));
FileOutputFormat.setOutputPath(job, new Path(args[]));
// ᨀ交运行作业
System.exit(job.waitForCompletion(true)?:);
}
}
NoReducerMRDriver
输入:
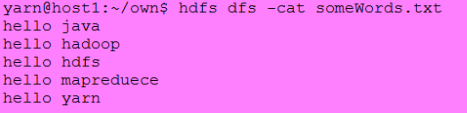
结果:
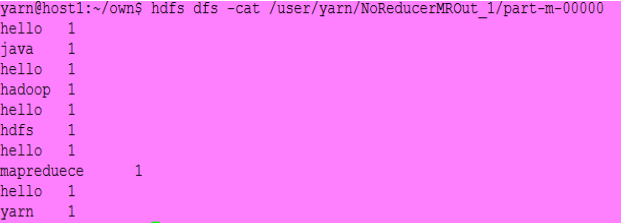
注意:如果作业拥有0个Reducer,则Mapper结果直接写入OutputFormat而不经key值排序。
3)No Mapper的MapReduce程序--Reducer
第一步:写一个TokenCounterReducer继承Reducer
/**
* 将reduce输入的values内容拆分为word,做一个简单输出的Reducer
*/
public class TokenCounterReducer extends Reducer<LongWritable, Text, Text, IntWritable>{
private Text word=new Text();
private static final IntWritable one=new IntWritable();
@Override
protected void reduce(LongWritable key, Iterable<Text> values,Reducer<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
for(Text value:values){
StringTokenizer itr=new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}
}
TokenCounterReducer
第二步:写一个NoMapperMRDrive完成作业配置
/**
*没有设置Mapper的MR程序
*/
public class NoMapperMRDriver {
public static void main(String[] args) throws Exception {
// 构建新的作业
Configuration conf=new Configuration();
Job job = Job.getInstance(conf, "NoMapper");
job.setJarByClass(NoMapperMRDriver.class);
// 设置Reducer
job.setReducerClass(TokenCounterReducer.class);
// 设置输出格式
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[]));
FileOutputFormat.setOutputPath(job, new Path(args[]));
// ᨀ交运行作业
System.exit(job.waitForCompletion(true)?:);
}
}
NoMapperMRDrive
输入:

输出:
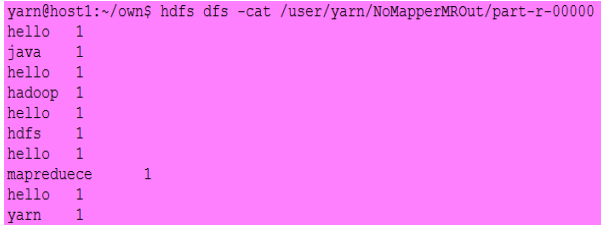
三、Mapper类和Reducer类以及它们的子类(实现类)
3.1、Mapper概述
Mapper:封装了应用程序Mapper阶段的数据处理逻辑
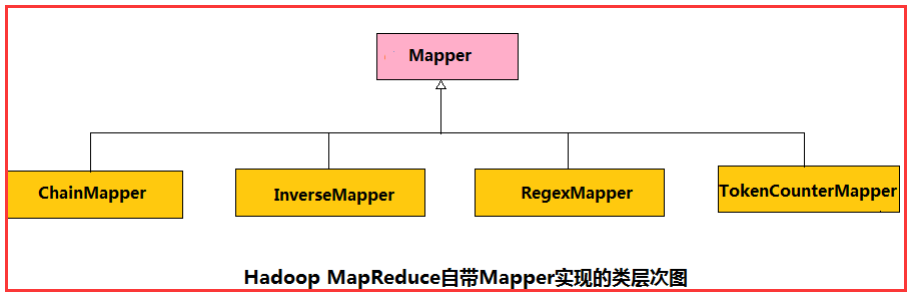
1)ChainMapper
方便用户编写链式Map任务, 即Map阶段包含多个Mapper,即可以别写多个自定义map去参与运算。
2)InverseMapper
一个能交换key和value的Mapper
3)RegexMapper
检查输入是否匹配某正则表达式, 输出匹配字符串和计数器(用的很少)
4)TockenCounterMapper
将输入分解为独立的单词, 输出个单词和计数器(以空格分割单词,value值为1)
3.2、Reducer概述
Mapper:封装了应用程序Mapper阶段的数据处理逻辑
1)ChainMapper:
方便用户编写链式Map任务, 即Map阶段只能有一个Reducer,后面还可以用ChainMapper去多加Mapper。
2)IntSumReducer/LongSumReducer
对各key的所有整型值求和
3.2、写一个实例去使用
注意:这里用到了一个输入格式为KeyValueTextInputFormat,我们查看源码注释:

我们需要用mapreduce.input.keyvaluelinerecordreader.key.value.separator去指定key和value的分隔符是什么,它的默认分隔符是"\t"也就是tab键。
这个需要在配置文件中去指定,但是我们知道在配置文件中能设置的在程序中也是可以设置的。
conf.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator",",");
代码实现:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.chain.ChainMapper;
import org.apache.hadoop.mapreduce.lib.chain.ChainReducer;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.map.InverseMapper;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.reduce.IntSumReducer;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class PatentReference_0010 extends Configured implements Tool{ static class PatentReferenceMapper extends Mapper<Text,Text,Text,IntWritable>{
private IntWritable one=new IntWritable();
@Override
protected void map(Text key,Text value,Context context) throws IOException, InterruptedException{
context.write(key,one);
}
} @Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
Path input=new Path(conf.get("input"));
Path output=new Path(conf.get("output"));
conf.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator",","); Job job=Job.getInstance(conf,this.getClass().getSimpleName());
job.setJarByClass(this.getClass()); ChainMapper.addMapper(job,InverseMapper.class,
// 输入的键值类型由InputFormat决定
Text.class,Text.class,
// 输出的键值类型与输入的键值类型相反
Text.class,Text.class,conf); ChainMapper.addMapper(job,PatentReferenceMapper.class,
// 输入的键值类型由前一个Mapper输出的键值类型决定
Text.class,Text.class,
Text.class,IntWritable.class,conf); ChainReducer.setReducer(job,IntSumReducer.class,
Text.class,IntWritable.class,
Text.class,IntWritable.class,conf); ChainReducer.addMapper(job,InverseMapper.class,
Text.class,IntWritable.class,
IntWritable.class,Text.class,conf); job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); KeyValueTextInputFormat.addInputPath(job,input);
TextOutputFormat.setOutputPath(job,output); return job.waitForCompletion(true)?:;
} public static void main(String[] args) throws Exception{
System.exit(ToolRunner.run(new P00010_PatentReference_0010(),args));
}
}
在Job job=Job.getInstance(conf,this.getClass().getSimpleName());设置中,job把conf也就是配置文件做了一个拷贝,因为hadoop要重复利用一个对象,如果是引用的话,发现值得改变就都改变了。
喜欢就点个“推荐”哦!
Hadoop(十七)之MapReduce作业配置与Mapper和Reducer类的更多相关文章
- hadoop学习(七)----mapReduce原理以及操作过程
前面我们使用HDFS进行了相关的操作,也了解了HDFS的原理和机制,有了分布式文件系统我们如何去处理文件呢,这就的提到hadoop的第二个组成部分-MapReduce. MapReduce充分借鉴了分 ...
- 关于Mapper、Reducer的个人总结(转)
Mapper的处理过程: 1.1. InputFormat 产生 InputSplit,并且调用RecordReader将这些逻辑单元(InputSplit)转化为map task的输入.其中Inpu ...
- 使用MRUnit,Mockito和PowerMock进行Hadoop MapReduce作业的单元测试
0.preliminary 环境搭建 Setup development environment Download the latest version of MRUnit jar from Apac ...
- 分布式配置 tachyon 并执行Hadoop样例 MapReduce
----------此文章.笔者按着tachyon官网教程进行安装并记录. (本地安装tachyon具体解释:http://blog.csdn.net/u012587561/article/detai ...
- 使用IDEA远程向伪分布式搭建的Hadoop提交MapReduce作业
环境 VirtualBox 6.1 IntelliJ IDEA 2020.1.1 Ubuntu-18.04.4-live-server-amd64 jdk-8u251-linux-x64 hadoop ...
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
原文:http://my.oschina.net/wstone/blog/365010#OSC_h3_13 (WJW)高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南 [X] ...
- Hadoop学习之路(二十七)MapReduce的API使用(四)
第一题 下面是三种商品的销售数据 要求:根据以上数据,用 MapReduce 统计出如下数据: 1.每种商品的销售总金额,并降序排序 2.每种商品销售额最多的三周 第二题:MapReduce 题 现有 ...
- Hadoop官方文档翻译——MapReduce Tutorial
MapReduce Tutorial(个人指导) Purpose(目的) Prerequisites(必备条件) Overview(综述) Inputs and Outputs(输入输出) MapRe ...
- 剖析MapReduce 作业运行机制
包含四个独立的实体: · Client Node 客户端:编写 MapReduce代码,配置作业,提交MapReduce作业. · JobTracker :初始化作业,分配作业,与 TaskTra ...
随机推荐
- Babel初体验
原文地址:→传送门 写在前面 现在es6很流行,尽管各大浏览器都还不能支持它的新特性,但是小伙伴们还是很中意它呀,于是小小的学习的一下 Babel 这里我们不介绍es6相关内容,只是说下入坑前奏,记录 ...
- 磁盘管理之inode与block
索引式文件系统 什么是inode? Inode其实就是索引号,便于我们寻找我们文件所存储的数据块block,索引式文件系统在查找信息,读写操作上都比原来的文件系统要快,我们可以通过inode中记录的b ...
- C++初学 virtual 相关
声明: 1.为了节省篇幅,头文件和域什么的都没写.另外可能是java转C++,有些叫法可能会不对 2.因初学,都是自己摸索的,有错望指出,勿喷 假设父类声明 Parent.h中如下 class Par ...
- ACM学习之路__HDU 1045
Fire Net Description : Suppose that we have a square city with straight streets. A map of a city is ...
- 杂谈--DML触发器学习
触发器按类型分为三类: 1. DML 触发器,在数据变更时触发: 2. DDL 触发器,在修改数据库级别或实例级别对象时触发: 3. Login 触发器,在用户登录时触发: 最常见的是DML触发器,D ...
- 代码与编程(java基础)
代码与编程(面试与笔试java) 1.写一个Singleton出来 Singleton模式主要作用是保证在Java应用程序中,一个类Class只有一个实例存在. 一般Singleton模式通常有几种种 ...
- Quartz学习——Quartz简单入门Demo(二)
要学习Quartz框架,首先大概了解了Quartz的基本知识后,在通过简单的例子入门,一步一个脚印的走下去. 下面介绍Quartz入门的示例,由于Quartz的存储方式分为RAM和JDBC,分别对这两 ...
- Qt学习之路MainWindow学习过程中的知识点
一.Qt的GUI程序有一个常用的顶层窗口,叫做MainWindow MainWindow继承自QMainWindow.QMainWindow窗口分成几个主要的区域: 二.QAction类 QAct ...
- HDFS概述(1)————HDFS架构
概述 Hadoop分布式文件系统(HDFS)是一种分布式文件系统,用于在普通商用硬件上运行.它与现有的分布式文件系统有许多相似之处.然而,与其他分布式文件系统的区别很大.HDFS具有高度的容错能力,旨 ...
- 洗礼灵魂,修炼python(1)--python简介
首先,本人也是刚接触python短短几个月,没有老鸟的经验和技能,大佬勿喷,以下所有皆是本人对python的理解 python,是一种解释型(高级)的,面向对象的,带有动态语义的高级程序设计的开源语言 ...