[项目记录]一个.net下使用HAP实现的吉大校园通知网爬虫工具:OAWebScraping
本文为大大维原创,最早于博客园发表,转载请注明出处!!!
第一章 简介
本文主要介绍了在.NET下利用优秀的HTML解析组件HtmlAgilityPack开发的一个吉林大学校内通知oa.jlu.edu.cn的爬取器。尽管.Net下解析HTML文件有很多种选择,包括微软自己也提供MSHTML用于manipulate HTML文件。但是,经过我多方查阅资料和自己的尝试,Html Agility Pack逐步脱颖而出:它是Stackoverflow网站上推荐最多的C# HTML解析器。HAP开源,易用,解析速度快。因此,本人最终选择使用HAP作为爬虫的开发的HTML解析组件。
笔者实现的爬虫OAWebScraping可以实现由使用者指定时间的(从当前时间往前n天)的,对oa.jlu.edu.cn上的所有所有通知和新闻,包括时间、标题、发表部门、正文全文和附件的爬取,并且按照时间->发表部门->标题->正文及附件的树形结构将爬取的文件保存在硬盘中。以下是使用截图:
开始爬虫,输入爬取的时间范围:
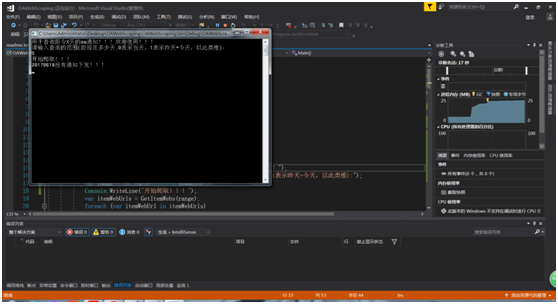
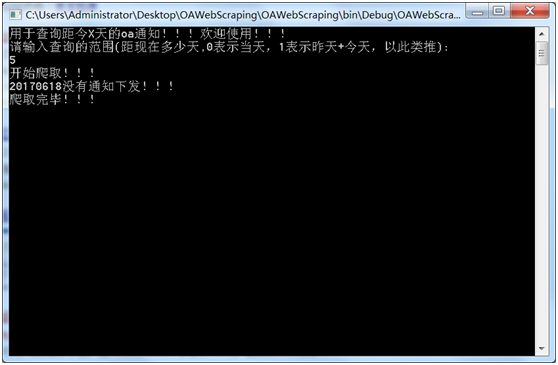
爬取成功,对于没有发放通知的日期给予提示:
文件的组织结构:
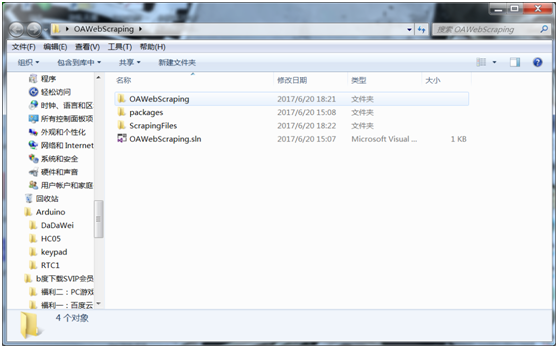
爬取的文件按照树形结构
时间->发表部门->标题->正文及附件
保存在硬盘:
按时间:
按发表部门:
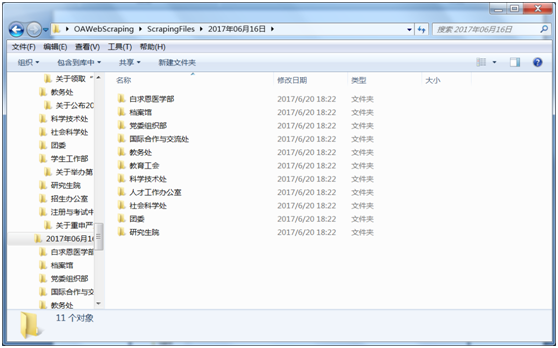
按标题:
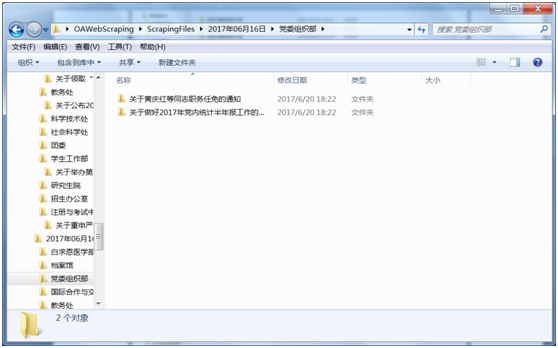
正文及附件:
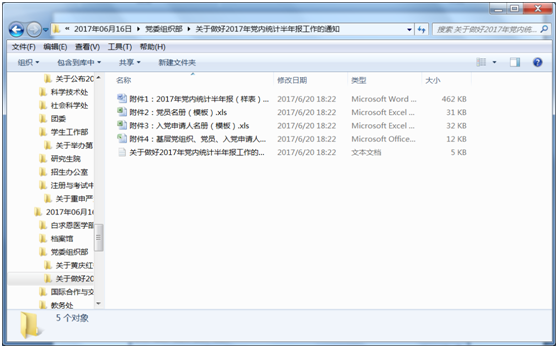
正文:
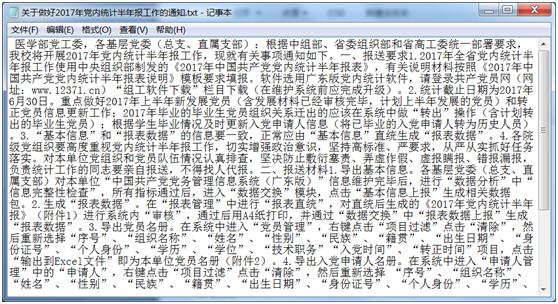
附件:
第二章 研究方法
(1) How to use HAP?【1】
1. 下载http://htmlagilitypack.codeplex.com/
2. 解压
3. 在Visual Studio Solution里,右击project -> add reference -> 选择解压文件夹里的HTMLAgilityPack.dll -> 确定
4. 代码头部加入 using HtmlAgilityPack;
Done!
(2)HAP 概述:【2】
在HtmlAgilityPack中常用到的类有HtmlDocument、HtmlNodeCollection、 HtmlNode和HtmlWeb等.其流程一般是先获取HTML,这个可以通过HtmlDocument的Load()或LoadHtml()来加载静态内容,或者也可以HtmlWeb的Get()或Load()方法来加载网络上的URL对应的HTML。
得到了HtmlDocument的实例之后,就可以用HtmlDocument的DocumentNode属性,这是整个HTML文档的根节点,它本身也是一个HtmlNode,然后就可以利用HtmlNode的SelectNodes()方法返回多个HtmlNode的集合对象HtmlNodeCollection,也可以利用HtmlNode的SelectSingleNode()方法返回单个HtmlNode。
(3)XPath 概述:[2]
HtmlAgilityPack是一个支持用XPath来解析HTML的类库,避免了采用正则表达式一步步将无关的HTML注释及JS代码部分删除掉,然后再用正则表达式找出需要提取的部分,可以说使用正则表达式来做是一个比较繁琐的过程,以下是一个简单的XPath介绍:XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
下面列出了最有用的路径表达式:
nodename:选取此节点的所有子节点。
/:从根节点选取。
//:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
.:选取当前节点。
..:选取当前节点的父节点。
(4)关键代码分析:
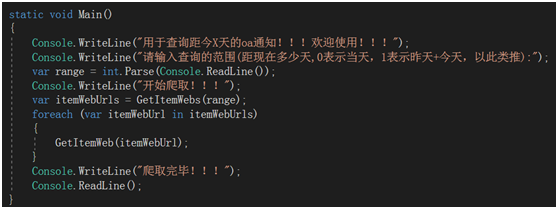
Main函数逻辑:通过GetItemWebs(range)找出需要爬取的url簇,然后用etItemWeb(itemWebUrl)爬取文件并下载。

拼接yyyyMMdd天的oa通知界面url。
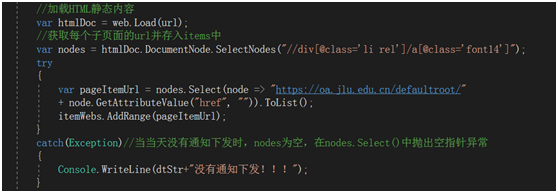
加载Html并查找当前页,由于oa中通知跳转连接均在<div> class“li rel”下 的<a>
Class “font14” 中,爬取出其href并拼接成相关具体通知的url,压入一个List(itemWebs)中,由于有些时段没有发通知,这样会导致nodes为空,会使得nodes.Select()发生空指针异常,因此引入异常机制,保证程序正常运行,并对没有发通知的日期进行提示。
以上是GetItemWebs(int range)的主要逻辑。该函数返回一个所有需要查找的通知的url的string s数组。

在GetItemWeb(string itemWebUrl)函数中,通过url初始化uri,解析uri获得title和orgname。

解析HtmlDocument并通过<div> class ‘content_time’ 获得通知发布时间。
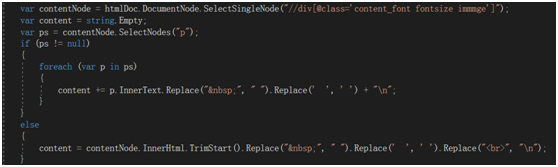
解析HtmlDocument中<div> class ‘content_font fontsize immmge’中的p标签,来拼接通知正文。

按照“时间->发表部门->标题->正文”树形结构将正文存储在硬盘
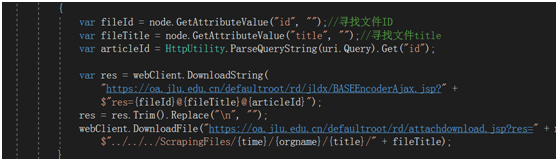
下载附件,并将附件和对应的正文存在一个文件中。
以上是GetItemWeb(string itemWebUrl)的主要逻辑。
第三章 数据分析和结果
由于时间限制,笔者爬取了2017/6/15-2017/6/20之间6天的所有数据,其中2017/6/18没有通知,没有数据。另外17号只有研究院发放的一条通知,其他时段基本上每天都有10个左右的部门发放15条左右的通知。查日历可知,17,18号为周末。
可见在工作日中,我校的教务工作都在积极进行,另外党委组织部和宣传部是通知发送的大头。具体可见ScrapingFiles文件夹(爬取数据的存储文件夹)。
第四章 结论
笔者在.NET下利用优秀的HTML解析组件HtmlAgilityPack开发的一个吉林大学校内通知oa.jlu.edu.cn的爬取器,测试好用并且挺实用。
第五章 参考文献
【1】Brian网络畅游的记录的博客《开源项目Html Agility Pack实现快速解析Html》
http://www.cnblogs.com/GmrBrian/p/6201237.html
【2】51Ct0博主周公的博客《HTML解析利器HtmlAgilityPack》:
http://zhoufoxcn.blog.51cto.com/792419/595344/
【3】CSDN无极世界博主的博客《HtmlAgilityPack——解析html和采集网页的神兵利器》http://blog.csdn.net/dalmeeme/article/details/7191793
【4】HAP官网的开发文档
http://htmlagilitypack.codeplex.com/
第六章 代码
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Net;
using System.Web;
using HtmlAgilityPack; //作者:大大维
namespace OA
{
class Program
{
static void Main()
{
Console.WriteLine("用于查询距今X天的oa通知!!!欢迎使用!!!");
Console.WriteLine("请输入查询的范围(距现在多少天,0表示当天,1表示昨天+今天,以此类推):");
var range = int.Parse(Console.ReadLine());
Console.WriteLine("开始爬取!!!");
var itemWebUrls = GetItemWebs(range);
foreach (var itemWebUrl in itemWebUrls)
{
GetItemWeb(itemWebUrl);
}
Console.WriteLine("爬取完毕!!!");
Console.ReadLine();
} private static string[] GetItemWebs(int range)
{
/*在HtmlAgilityPack中常用到的类有HtmlDocument、HtmlNodeCollection、
HtmlNode和HtmlWeb等.其流程一般是先获取HTML,这个可以通过HtmlDocument的Load()或LoadHtml()来加载静态内容,
或者也可以HtmlWeb的Get()或Load()方法来加载网络上的URL对应的HTML。
得到了HtmlDocument的实例之后,就可以用HtmlDocument的DocumentNode属性,
这是整个HTML文档的根节点,它本身也是一个HtmlNode,
然后就可以利用HtmlNode的SelectNodes()方法返回多个HtmlNode的集合对象HtmlNodeCollection,
也可以利用HtmlNode的SelectSingleNode()方法返回单个HtmlNode。 */
var itemWebs = new List<string>();//由于每页网站的通知内容数目不定,采用List较好
//@忽略转义字符
var baseUrl = @"https://oa.jlu.edu.cn/defaultroot/PortalInformation!jldxList.action?channelId=179577&searchnr=";
var web = new HtmlWeb();
for (var i = range; i >= ; --i)
{
//拼接yyyyMMdd天的oa通知界面
DateTime dt = DateTime.Now.AddDays(-i);
var dtStr = string.Format("{0:yyyyMMdd}", dt);
var url = baseUrl + dtStr + "&searchlx=3";
//加载HTML静态内容
var htmlDoc = web.Load(url);
//获取每个子页面的url并存入items中
var nodes = htmlDoc.DocumentNode.SelectNodes("//div[@class='li rel']/a[@class='font14']");
try
{
var pageItemUrl = nodes.Select(node => "https://oa.jlu.edu.cn/defaultroot/"
+ node.GetAttributeValue("href", "")).ToList();
itemWebs.AddRange(pageItemUrl);
}
catch(Exception)//当当天没有通知下发时,nodes为空,在nodes.Select()中抛出空指针异常
{
Console.WriteLine(dtStr+"没有通知下发!!!");
}
}
return itemWebs.ToArray();
} private static void GetItemWeb(string itemWebUrl)
{
//uri解析
var uri = new Uri(itemWebUrl);
var title = HttpUtility.ParseQueryString(uri.Query).Get("title");//title即url的title部分
var orgname = HttpUtility.ParseQueryString(uri.Query).Get("orgname");//orgname即url的orgname部分 var web = new HtmlWeb();
var htmlDoc = web.Load(itemWebUrl); var contentTime = htmlDoc.DocumentNode.SelectSingleNode("//div[@class='content_time']").InnerText;
var indexOfBlank = contentTime.IndexOf(' ');
var time = contentTime.Substring(, indexOfBlank); var contentNode = htmlDoc.DocumentNode.SelectSingleNode("//div[@class='content_font fontsize immmge']");
var content = string.Empty;
var ps = contentNode.SelectNodes("p");
if (ps != null)
{
foreach (var p in ps)
{
content += p.InnerText.Replace(" ", " ").Replace(' ', ' ') + "\n";
}
}
else
{
content = contentNode.InnerHtml.TrimStart().Replace(" ", " ").Replace(' ', ' ').Replace("<br>", "\n");
} //创建ScrapingFiles文件夹保存文件
Directory.CreateDirectory($"../../../ScrapingFiles/{time}/{orgname}/{title}");
File.WriteAllText($"../../../ScrapingFiles/{time}/{orgname}/{title}/"+title + ".txt", content); //下载相关附件
var fileNodes = htmlDoc.DocumentNode.SelectNodes("//td[@width='93%']/span");
if (fileNodes != null)
{
var webClient = new WebClient();
foreach (var node in fileNodes)
{
var fileId = node.GetAttributeValue("id", "");//寻找文件ID
var fileTitle = node.GetAttributeValue("title", "");//寻找文件title
var articleId = HttpUtility.ParseQueryString(uri.Query).Get("id"); var res = webClient.DownloadString(
"https://oa.jlu.edu.cn/defaultroot/rd/jldx/BASEEncoderAjax.jsp?" +
$"res={fileId}@{fileTitle}@{articleId}");
res = res.Trim().Replace("\n", "");
webClient.DownloadFile("https://oa.jlu.edu.cn/defaultroot/rd/attachdownload.jsp?res=" + res,
$"../../../ScrapingFiles/{time}/{orgname}/{title}/" + fileTitle);
}
}
}
}
}
[项目记录]一个.net下使用HAP实现的吉大校园通知网爬虫工具:OAWebScraping的更多相关文章
- 记录一个linux下批处理的代码
DATA_DIR=/home/liupan/.navinsight/data/dataset_rec SHELL_DIR=/home/liupan/workspace/nvi_postprocessi ...
- 一个tomcat下部署多个项目或一个服务器部署多个tomcat
最近需要把两个项目同时部署到服务器上,于是研究了一下,页借鉴了很多别人的方法,把过程记录下来,以儆效尤. 目录: 1,一个tomcat下同时部署两个项目(多个项目可以参考) 1.1项目都放在webap ...
- 记录-Intellij Idea下以Tomcat运行Web项目时的位置问题
今天本来准备把原来的一个Web项目导入到Idea下,之前这个项目是用eclipse写的,容器用的tomcat,首先导入前我把一些没用的配置文件都给删了,像什么.eclipse..setting什么的, ...
- Nginx高级配置,同1台机器部署多个tomcat、配置多个域名,每个域名指向某一个tomcat下的项目,共用Nginx80端口访问;
需求说明: 只有一台服务器和一个公网IP,多个项目部署在这台机器上面,且每个项目使用一个单独的域名访问,域名访问时都通过Nginx的80端口访问.(如下图所示) 配置过程: 一.tomcat的serv ...
- elasticsearch type类型创建时注意项目,最新的elasticsearch已经不建议一个索引下多个type
https://www.elastic.co/guide/cn/elasticsearch/guide/current/mapping.html如果有两个不同的类型,每个类型都有同名的字段,但映射不同 ...
- IOS客户端Coding项目记录导航
IOS客户端Coding项目记录(一) a:UITextField设置出现清除按键 b:绘画一条下划线 表格一些设置 c:可以定义表头跟底部视图(代码接上面) d:隐藏本页的导航栏 e:UIEdge ...
- 用spring+hibernate+struts 项目记录以及常用的用法进等
一.hibernate1. -----BaseDao------ // 容器注入 private SessionFactory sessionFactory; public void setSessi ...
- NodeJS项目迁移兼Ubuntu下NodeJS环境部署
前言 之前做的几个项目都托管在阿里云服务器,但是最近要到期了.想着到底要不要续期,毕竟100/月.后面看着阿里云有个活动,800/三年.果断买下.环境部署折腾了一天,其中也遇到几个坑. 目录 一.安装 ...
- Maven Web项目部署到Tomcat下问题
但是也遇到了很多问题,下面记录一下Web项目部署到Tomcat下的问题 1.普通的WEB项目,就是虽然是用maven搭建的,但是没有使用profiles.xml文件来配置参数.这样的项目可以通过以下的 ...
随机推荐
- Android系统--输入系统(十一)Reader线程_简单处理
Android系统--输入系统(十一)Reader线程_简单处理 1. 引入 Reader线程主要负责三件事情 获得输入事件 简单处理 上传给Dispatch线程 InputReader.cpp vo ...
- 2017云计算开源峰会 你是想听Linux谈开源还是想听OpenStack谈开源?
2017年,善于把握机遇的企业们不是正在开源,就是走在去开源的路上-- 开源是不是就意味着免费? 开源企业就是要当"活雷锋"? 开源项目究竟如何运作?如何参与开源社区? 如何获得最 ...
- Python输入一个数字打印等腰三角形
要求 用户输入一个数字,按照数字打印出等腰三角形 思路 1,用户输入的数字为n代表一共有多少行 2,使用一个循环带两个for循环,第一层循环是循环行数,第二层两个平行for循环一个打印空格一个打印*号 ...
- LeetCode:36. Valid Sudoku,数独是否有效
LeetCode:36. Valid Sudoku,数独是否有效 : 题目: LeetCode:36. Valid Sudoku 描述: Determine if a Sudoku is valid, ...
- UART通信
UART0串口调试过程:1.配置DTS节点 在Z:\rk3399\kernel\arch\arm64\boot\dts\rockchip路径下打开rk3399.dtsi文件,里面已经有UART0相关节 ...
- Scala基础 - 下划线使用指南
下划线这个符号几乎贯穿了任何一本Scala编程书籍,并且在不同的场景下具有不同的含义,绕晕了不少初学者.正因如此,下划线这个特殊符号无形中增加Scala的入门难度.本文希望帮助初学者踏平这个小山坡. ...
- angular.js的表格指令
html div.col-sm-12 table.table.table-bordered.table-condensed.table-hover.table-striped.dataTable.no ...
- 传感器系列之4.12GPS定位传感器
4.12 GPS定位实验 一.实验目的 了解GPS的基本概念 了解NMEA-0183格式数据串的组成和关于GPS的常用语句 GPS的数据串解析 二.实验材料 具有串口通讯的电脑一台 ADS1.2开发环 ...
- 《Android进阶》之第三篇 深入理解android的消息处理机制
Android 异步消息处理机制 让你深入理解 Looper.Handler.Message三者关系 android的消息处理机制(图+源码分析)——Looper,Handler,Message an ...
- CollectioView滚动到指定section的方法
项目中的需求:collectionView顶部有一个scrollView组成的标签,点击标签,让collectionView滚动到指定的行,滚动collectionView自动切换到顶部指定的标签 实 ...