对比分析LinkedBlockingQueue和SynchronousQueue
缘起
最近在 review 同事代码时,看到其使用了org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor 来构建线程池,而没有使用 Java 类库,部分代码如下:
@Bean
public ThreadPoolTaskExecutor queryToCExecutor() {
ThreadPoolTaskExecutor poolTaskExecutor = new ThreadPoolTaskExecutor();
//线程池维护线程的最少数量
poolTaskExecutor.setCorePoolSize(5);
//线程池维护线程的最大数量
poolTaskExecutor.setMaxPoolSize(32);
//允许的空闲时间,尽量复用,减少创建/销毁操作
poolTaskExecutor.setKeepAliveSeconds(60);
//缓存队列 0:不加入队列
poolTaskExecutor.setQueueCapacity(0);
poolTaskExecutor.setThreadGroupName("xxx");
//阻塞加入队列
poolTaskExecutor.setRejectedExecutionHandler(new QueryRejectedExecutionHandler());
return poolTaskExecutor;
}
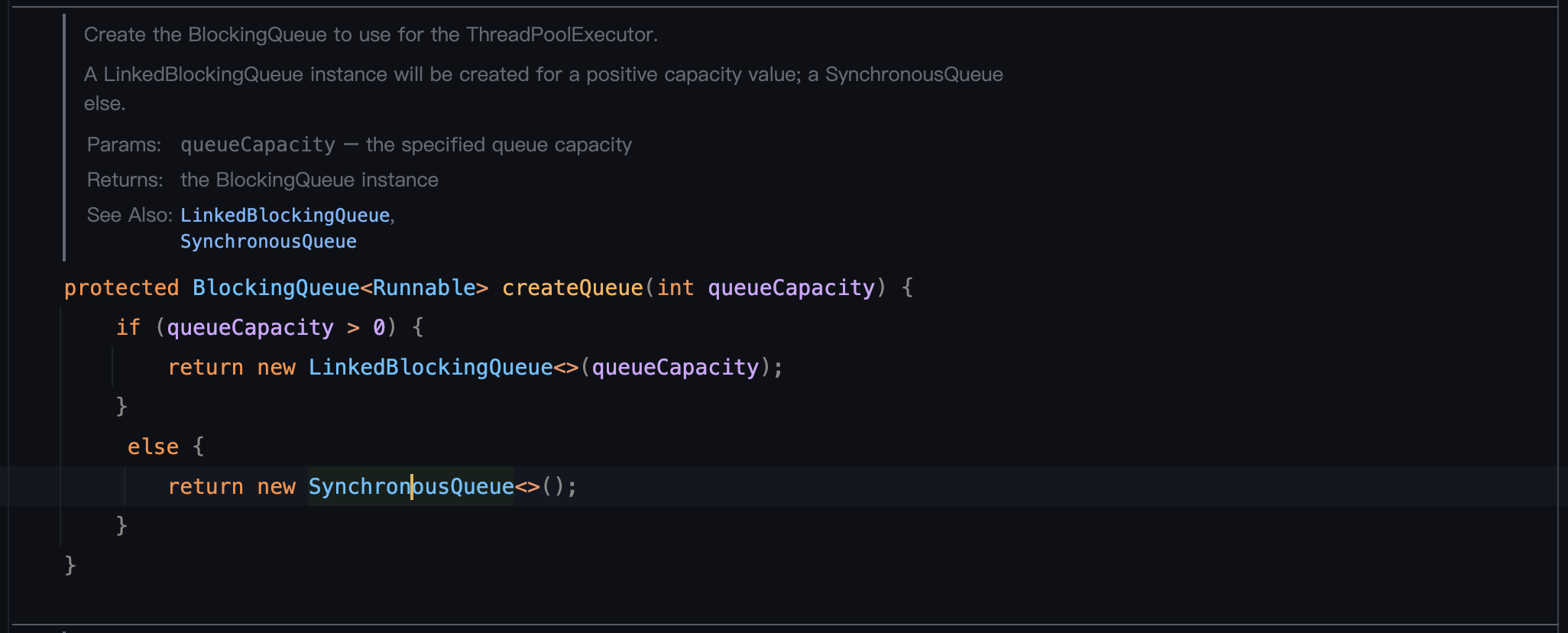
出于对注释中「缓存队列 0:不加入队列」的好奇,就看了下对应的源码(如下图),发现原来 Spring 会简单地根据容量值是否大于0而选择不同的Java阻塞队列作为其线程池的任务队列:队列容量大于0为 LinkedBlockingQueue,其他情况为 SynchronousQueue。看到这里,正好把我所了解到的有关这两个队列的内容梳理一下,是为温故而知新。
LinkedBlockingQueue面面观
设计目的:为了消弭生产者和消费者之间的速度差异,提供一个安全的线程间缓存队列。
实现机制:
LinkedBlockingQueue是基于链表的 FIFO(First In First Out,即先进先出)阻塞队列,即其内部维护了一个单向链表,插入元素时在队列尾部追加节点,删除元素时在队列头部取出节点,以保证FIFO;
对于生产/消费并发控制,内部定义了两个独立的锁:一把用于入队的 putLock,一把用于出队的 takeLock,这种锁分离机制,可以使生产者的入队操作和消费者的出队操作可以并行。
同时,为了协调生产者/消费者,其还配备了对应的条件变量:在队列满时阻塞生产者的
notFull(notFull=putLock.newCondition()),以及在队列空时阻塞消费者的notEmpty(notEmpty=takeLock.newCondition())。当生产者插入元素使队列从空变为非空时,会 signal notEmpty 通知等待的消费者线程;类似地,当消费者移除元素使队列从满变为未满时,会 signal notFull 通知等待的生产者线程。
容量特性:
默认为无界队列(容量为
Integer.MAX_VALUE),生产者不会因为队列满了而阻塞,实际上仍然受内存限制有界模式,可指定容量,如
new LinkedBlockingQueue(100);
操作特性:
支持异步操作,生产者可以独立插入元素(如果队列未满),消费者可以独立取出元素(如果队列非空);
插入/删除时间复杂度为
O(1),但遍历操作(如contains())时间复杂度为O(n)。
适用场景:
固定大小线程池(如
Executors.newFixedThreadPool())使用无界的 LinkedBlockingQueue 存放多余任务;通用生产-消费者模型需要缓冲时;
适合生产消费速率不一致、有突发流量需要缓冲的场景。
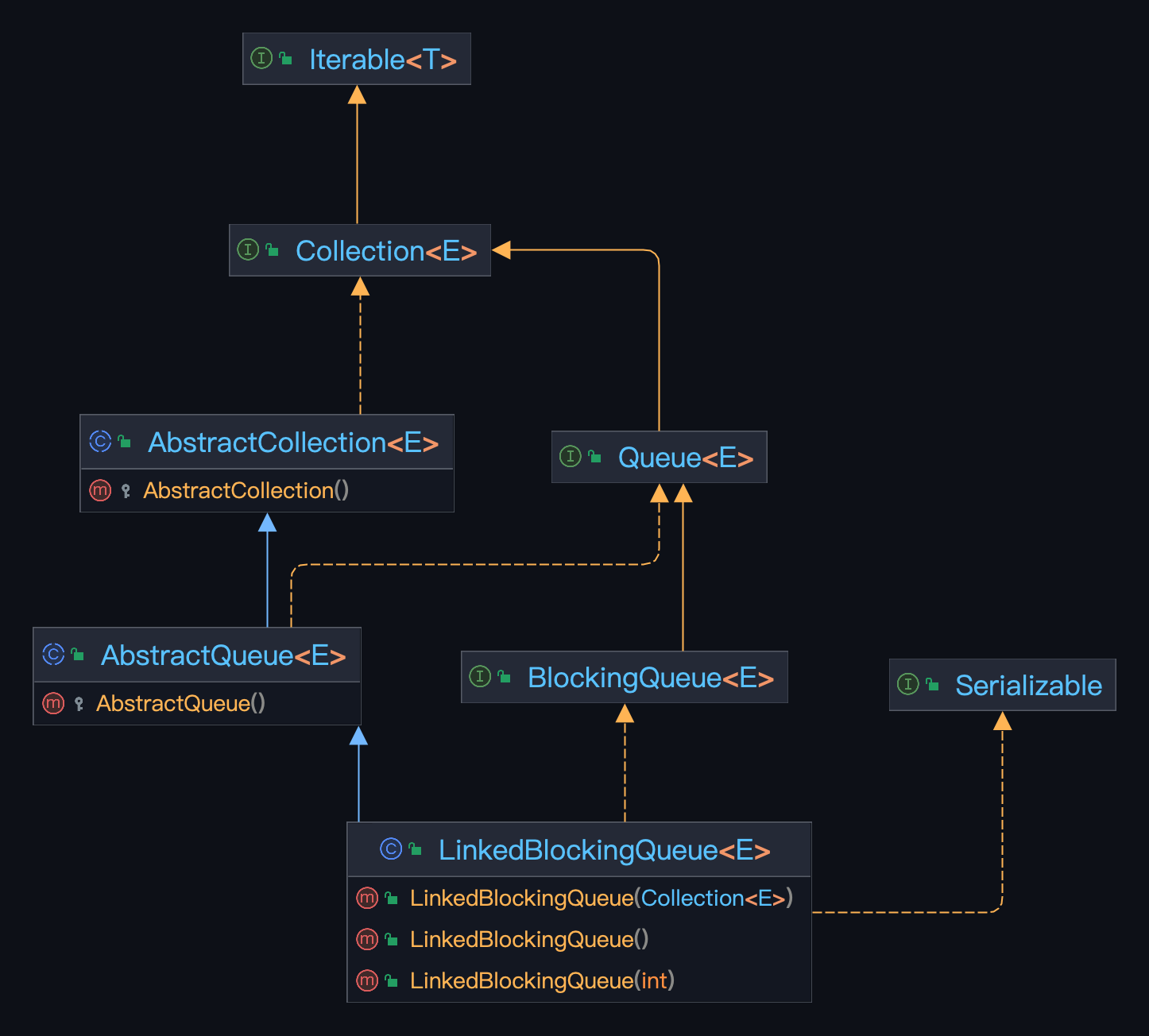
其在 JDK 实现的类UML 如下图:
SynchronousQueue面面观
设计目的:提供线程间同步交换数据的机制。
实现机制:
SynchronousQueue底层没有使用传统的数据结构,内部可理解为维护了两个队列/栈结构:一个等待中的生产者线程集合和一个等待中的消费者线程集合。
当有生产者线程执行
put时,如果此时有消费者线程在等待获取元素,双方直接配对完成元素交接;如果没有消费者等待,那么生产者线程就会自己阻塞并进入等待集合。对消费者线程执行take时也是类似的:如有等待中的生产者,它们配对交接;如果没有生产者等待,则消费者线程阻塞进入等待集合。对于生产/消费并发控制,JDK 底层的实现对上面这种等待线程的管理分为两种模式:非公平模式下使用栈结构后进先出(LIFO)地管理等待线程(内部类称为
TransferStack),公平模式下使用队列结构先进先出(FIFO)地管理等待线程(内部类TransferQueue)。对于协调生产者/消费者,没有像LinkedBlockingQueue使用锁机制,而是采用了 CAS 来管理。
容量特性:容量为0,无法缓存任何元素。
操作特性:
严格同步,生产者和消费者必须成对出现:插入操作(
put())必须等待对应删除操作(take()),反之亦然;不支持迭代和查看元素(如
peek()永远返回null)。
适用场景:
缓存线程池(如
Executors.newCachedThreadPool())使用SynchronousQueue直接把任务交给线程或创建新线程执行;需要严格同步交接的场景(比如两个线程交替工作)。
适合生产消费速率相当、要求低延迟无排队的场景
其在 JDK 实现的类UML 如下图:
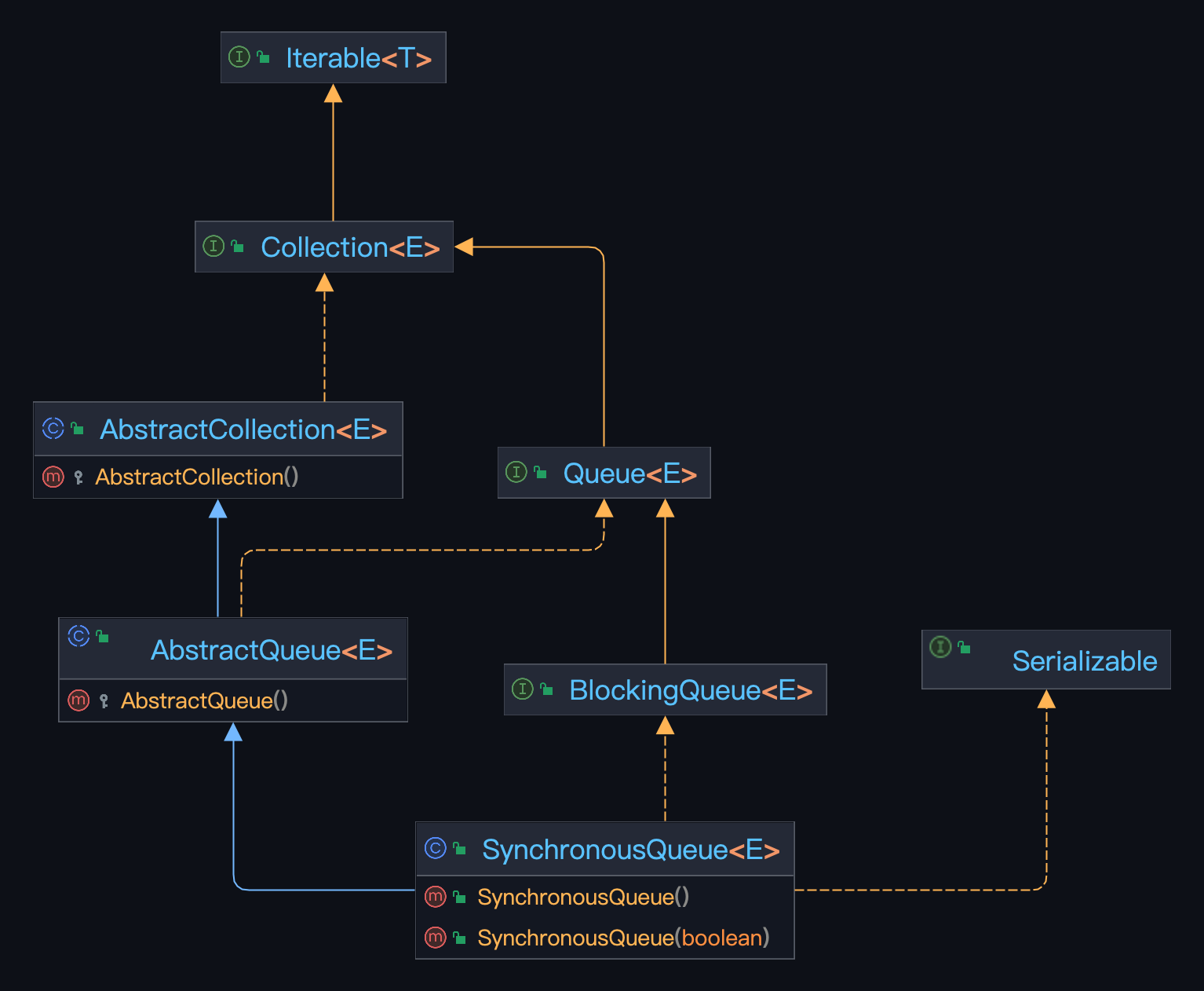
一表式总结
根据上面的两个类的 UML 图,可以发现两者都实现了相同的接口BlockingQueue,所以都是阻塞队列,在特定条件下都会阻塞线程调用,只是底层实现不相同而已。
对于不相同的地方,下面的表格总结了 LinkedBlockingQueue 和 SynchronousQueue 在各方面的差异:
| 对比维度 | LinkedBlockingQueue(LBQ) | SynchronousQueue (SQ) |
|---|---|---|
| 容量 | 可选有界/无界(默认)的FIFO阻塞队列,基于链表节点存储元素 | 容量为0的阻塞队列,不存储元素,只在线程间直接交换数据 |
| 底层结构 | 链表结构:内部有节点类存放元素,维护头尾指针和计数器。使用两把锁(putLock/takeLock)分别控制入队出队。有条件变量 notFull/notEmpty 用于阻塞等待。 |
无具体数据结构容器。JDK内部通过等待线程队列/栈管理:非公平模式用栈(LIFO),公平模式用队列(FIFO)存放等待的线程节点。通过 CAS 和 LockSupport 挂起/唤醒线程来交换元素。 |
| 线程交互 | 生产者插入操作在队列满时阻塞,消费者移除操作在队列空时阻塞;可以同时有多个元素在队列中等待处理。 | 每次插入操作必须等待有对应的移除操作才能进行,反之亦然。队列中始终不会有多于一个元素存在(实际上最多瞬间有一个正在交接的元素),生产和消费必须配对完成。 |
| 性能特点 | 插入和移除使用独立锁,支持一定程度并行,吞吐量高;在高并发下存在锁竞争和上下文切换,性能可能不够稳定。内有缓冲会增加任务延迟但减少生产者阻塞。 | 采用无锁算法,线程直接配对交换,极低的同步开销,单对线程下吞吐极高;无缓冲减少了排队延迟,但如果一方线程不足会使另一方阻塞等待。大量线程不匹配时可能出现许多线程挂起,极端高并发下吞吐可能下降。公平模式下性能略低于非公平模式,因为要额外开销保证 FIFO。 |
| 典型应用 | 固定大小线程池(如 Executors.newFixedThreadPool())使用无界LBQ存放多余任务;通用生产-消费者模型需要缓冲时。适合生产消费速率不一致、有突发流量需要缓冲的场景。 |
缓存线程池(如 Executors.newCachedThreadPool())使用SQ直接把任务交给线程或创建新线程执行;需要严格同步交接的场景。适合生产消费速率相当、要求低延迟无排队的场景。 |
| 公平策略 | 不支持 | 支持 |
| 迭代能力 | 提供弱一致性迭代 | 不支持迭代 |
如何快速理解两者的工作原理
为了能够快速理解两者的工作原理,这里以快递送达为比喻进行解释:
LinkedBlockingQueue像是菜鸟物流,快递员(生产者)总是把包裹(任务)放到菜鸟驿站(里面有固定数量的储物架,可理解为任务队列),收件人(消费者)可以在空闲时去菜鸟驿站取件,而不用必须等快递员把包裹送到面前,即强调双方的时间是可以错开的,包裹的送达(入队)和领取(出队)的动作是可以异步进行的。SynchronousQueue就像是闪送,快递员(生产者)必须把包裹(任务)当面交给收件人(消费者),因没有储物架(没有任务队列)而不能提前送达:如果收件人没有来,快递员则会一直等待收件人出现,同理,收件人也只能等待快递员出现才能当面领到包裹,即强调双方必须同时在场。
以上。如有错误疏漏,欢迎评论一起探讨!
如果你觉得我的工作对你有帮助,可以通过分享和推荐这篇文字或者关注同名公众号来支持我,你的支持是我持续创作的动力:

转载以及引用请注明原文链接。
本博客所有文章除特别声明外,均采用CC 署名-非商业使用-相同方式共享 许可协议。
对比分析LinkedBlockingQueue和SynchronousQueue的更多相关文章
- 浅谈C++之冒泡排序、希尔排序、快速排序、插入排序、堆排序、基数排序性能对比分析之后续补充说明(有图有真相)
如果你觉得我的有些话有点唐突,你不理解可以想看看前一篇<C++之冒泡排序.希尔排序.快速排序.插入排序.堆排序.基数排序性能对比分析>. 这几天闲着没事就写了一篇<C++之冒泡排序. ...
- wait、notify、sleep、interrupt对比分析
对比分析Java中的各个线程相关的wait().notify().sleep().interrupt()方法 方法简述 Thread类 sleep:暂停当前正在执行的线程:(类方法) yield:暂停 ...
- Android和Linux应用综合对比分析
原文地址:http://www.cnblogs.com/beer/p/3325242.html 免责声明: 当时写完这篇调查报告,给同事看了后,他觉得蛮喜欢,然后想把这篇文章修改一下,然后往期刊上发表 ...
- GitHub & Bitbucket & GitLab & Coding 的对比分析
目前基于 Git 做版本控制的代码托管平台有很多种,比较流行的服务有 Github.Bitbucket. GitLab. Coding,他们各自有什么特点,个人使用者和开发团队又该如何选择? 在这篇文 ...
- ArrayList和LinkedList的几种循环遍历方式及性能对比分析(转)
主要介绍ArrayList和LinkedList这两种list的五种循环遍历方式,各种方式的性能测试对比,根据ArrayList和LinkedList的源码实现分析性能结果,总结结论. 通过本文你可以 ...
- ArrayList和LinkedList的几种循环遍历方式及性能对比分析
最新最准确内容建议直接访问原文:ArrayList和LinkedList的几种循环遍历方式及性能对比分析 主要介绍ArrayList和LinkedList这两种list的五种循环遍历方式,各种方式的性 ...
- ArrayList和LinkedList的几种循环遍历方式及性能对比分析(转载)
原文地址: http://www.trinea.cn/android/arraylist-linkedlist-loop-performance/ 原文地址: http://www.trinea.cn ...
- ArrayList和LinkedList遍历方式及性能对比分析
ArrayList和LinkedList的几种循环遍历方式及性能对比分析 主要介绍ArrayList和LinkedList这两种list的五种循环遍历方式,各种方式的性能测试对比,根据ArrayLis ...
- 【产品对比分析】See做了明星衣橱想做的东西?
不断地发现.联想.思考,让学到的东西互通起来吧! 先来两张See的界面图镇楼—— See简介: See是一个专注找同款的时尚社区,主打功能是一键拍照找同款,由社区为你提供最佳商品或 ...
- 【转】ArrayList和LinkedList的几种循环遍历方式及性能对比分析
原文网址:http://www.trinea.cn/android/arraylist-linkedlist-loop-performance/ 主要介绍ArrayList和LinkedList这两种 ...
随机推荐
- 使用Python完成设备巡检
在企业网络中,设备巡检是保持网络稳定性和安全性的核心任务.无论是路由器.交换机,还是防火墙和服务器等设备,都需要定期进行巡检,以确保网络设施的正常运行.然而,传统的设备巡检通常是通过手动登录设备.查看 ...
- Joker 前端框架组件的生命周期:深度解析与实践应用
在 Joker 前端框架的开发体系中,组件的生命周期犹如一颗精准的导航星,指引着开发者构建高效.稳定且富有交互性的应用程序.它完整地涵盖了从组件实例诞生的那一刻起,直至其完成使命被销毁的全过程,每一个 ...
- WEBGL 笔记
目录 前言 h2 { text-align: center } 前言 WebGL 是一个在浏览器里使用的高效渲染二维和三维图形的 javascript API,于 2006 年起源,该技术基于 Ope ...
- ThreeJs-16智慧城市项目(重磅以及未来发展ai)
 项目源 ...
- 离线版nrfutil工具安装方法
简介 nrfutil是Nordic提供的命令行工具集.支持以下功能: 基于Jlink的固件烧录.读取.flash擦除.recover 基于MCUBOOT的固件升级(DFU) 基于nRF5 bootlo ...
- tesseract引擎RVV代码学习笔记
Tesseract 是一个开源的 OCR(Optical Character Recognition,光学字符识别)引擎,可将图像中的文本转换为机器可读的文本格式.由于组内曾经有同事为这个项目贡献 ...
- 智能驾驶致死、AI聊天自杀,安全成最大的奢侈
提供AI咨询+AI项目陪跑服务,有需要回复1 前几天<高层论坛:实现汽车产业高质量发展>才刚召开,因为汽车行业卷得不行,现在大家都想在智能驾驶上发力,其中有句话令我影响深刻: 对智能驾驶来 ...
- CentOS 7 部署 GLPI 系统及集成方案
一.系统环境准备 1. 安装必要依赖 # 更新系统sudo yum update -y # 安装EPEL仓库sudo yum install -y epel-release # 安装必要组件sudo ...
- Java 中的 young GC、old GC、full GC 和 mixed GC 的区别是什么?
Java 中的 young GC.old GC.full GC 和 mixed GC 的区别 在 Java 中,垃圾回收(GC)可以分为几种不同类型,包括 young GC.old GC.full G ...
- kettle介绍-Step之CSV Input
CSV Input/CSV 文件输入介绍 CSV 文件输入步骤主要用于将 CSV 格式的文本文件按照一定的格式输入至 流中 Step name:步骤的名称,在单一转换中,名称必须唯一 Filename ...