kafka介绍和使用
1 Kafka简介
Kafka是最初由Linkedin公司开发,它是一个分布式、可分区、多副本,基于zookeeper协调的分布式日志系统;常见可以用于web/nginx日志、访问日志,消息服务等等。Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。主要应用场景是:日志收集系统和消息系统。
Kafka是一个分布式消息队列。具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。Kafka就是一种发布-订阅模式。将消息保存在磁盘中,以顺序读写方式访问磁盘,避免随机读写导致性能瓶颈。
消息(Message)
是指在应用之间传送的数据,消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。消息队列(Message Queue)
一种应用间的通信方式,消息发送后可以立即返回,通过消息系统来确保信息的可靠传递,消息发布者只管把消息发布到MQ中而不管谁来取,消息使用者只管从MQ中取消息而不管谁发布的,这样发布者和使用者都不用知道对方的存在。
2 Kafka特性
高吞吐、低延迟kafka 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒。
高伸缩性每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中。
持久性、可靠性Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失。
容错性允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作。
高并发支持数千个客户端同时读写。
3 Kafka集群架构
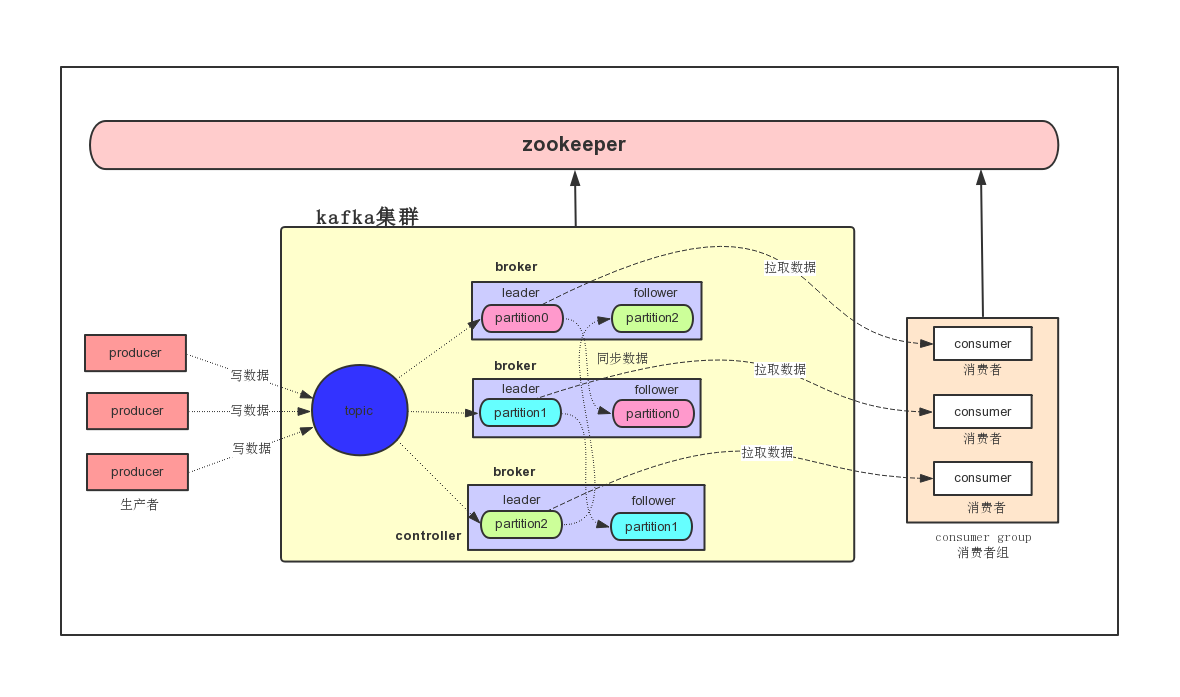
producer
消息生产者,发布消息到Kafka集群的终端或服务。
broker
Kafka集群中包含的服务器,一个borker就表示kafka集群中的一个节点。
topic
每条发布到Kafka集群的消息属于的类别,即Kafka是面向 topic 的。
更通俗的说Topic就像一个消息队列,生产者可以向其写入消息,消费者可以从中读取消息,一个Topic支持多个生产者或消费者同时订阅它,所以其扩展性很好。
partition
每个 topic 包含一个或多个partition。Kafka分配的单位是partition。
replica
partition的副本,保障 partition 的高可用。
consumer
从Kafka集群中消费消息的终端或服务。
consumer group
每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。 producer 和 consumer 只跟 leader 交互。
follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。
controller
知道大家有没有思考过一个问题,就是Kafka集群中某个broker宕机之后,是谁负责感知到他的宕机,以及负责进行Leader Partition的选举?
如果你在Kafka集群里新加入了一些机器,此时谁来负责把集群里的数据进行负载均衡的迁移?
包括你的Kafka集群的各种元数据,比如说每台机器上有哪些partition,谁是leader,谁是follower,是谁来管理的?
如果你要删除一个topic,那么背后的各种partition如何删除,是谁来控制?
还有就是比如Kafka集群扩容加入一个新的broker,是谁负责监听这个broker的加入?
如果某个broker崩溃了,是谁负责监听这个broker崩溃? 这里就需要一个Kafka集群的总控组件,Controller。他负责管理整个Kafka集群范围内的各种东西。
zookeeper
(1)Kafka 通过 zookeeper 来存储集群的meta元数据信息。
(2)一旦controller所在broker宕机了,此时临时节点消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就争抢再次创建临时节点,
保证有一台新的broker会成为controller角色。
* offset
* 偏移量
消费者在对应分区上已经消费的消息数(位置),offset保存的地方跟kafka版本有一定的关系。
kafka0.8 版本之前offset保存在zookeeper上。
kafka0.8 版本之后offset保存在kafka集群上。
它是把消费者消费topic的位置通过kafka集群内部有一个默认的topic,名称叫 __consumer_offsets,它默认有50个分区。
Kafka集群安装部署
1 集群安装部署
1、下载安装包(http://kafka.apache.org)
kafka_2.11-1.1.0.tgz
2、规划安装目录
/bigdata/install
3、上传安装包到服务器中
通过FTP工具上传安装包到node01服务器上
4、解压安装包到指定规划目录
tar -zxvf kafka_2.11-1.1.0.tgz -C /bigdata/install
5、重命名解压目录
mv kafka_2.11-1.1.0 kafka
6、在hadoop01上修改配置文件
进入到kafka安装目录下有一个
config目录,修改配置信息 vi server.properties#指定kafka对应的broker id ,唯一
broker.id=0
#指定数据存放的目录
log.dirs=/bigdata/install/kafka/kafka-logs
#指定zk地址
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
#指定是否可以删除topic ,默认是false 表示不可以删除
delete.topic.enable=true
#指定broker主机名
host.name=hadoop01
配置kafka环境变量 sudo vi /etc/profile
export KAFKA_HOME=/bigdata/install/kafka
export PATH=$PATH:$KAFKA_HOME/bin
6、分发kafka安装目录到其他节点
scp -r kafka hadoop02:/bigdata/install
scp -r kafka hadoop03:/bigdata/install ## hadoop02/hadoop03上都加上环境变量
export KAFKA_HOME=/bigdata/install/kafka
export PATH=$PATH:$KAFKA_HOME/bin
7、修改hadoop02和hadoop03上的配置
hadoop02 上修改配置文件 vi server.properties
#指定kafka对应的broker id ,唯一
broker.id=1
#指定数据存放的目录
log.dirs=/bigdata/install/kafka/kafka-logs
#指定zk地址
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
#指定是否可以删除topic ,默认是false 表示不可以删除
delete.topic.enable=true
#指定broker主机名
host.name=hadoop02
hadoop03 上修改配置文件 vi server.properties
#指定kafka对应的broker id ,唯一
broker.id=2
#指定数据存放的目录
log.dirs=/bigdata/install/kafka/kafka-logs
#指定zk地址
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
#指定是否可以删除topic ,默认是false 表示不可以删除
delete.topic.enable=true
#指定broker主机名
host.name=hadoop03
8、让每台节点的kafka环境变量生效
在每台服务器执行命令
source /etc/profile
2 kafka集群启动和停止
1、启动kafka集群
先启动zookeeper集群,然后在所有节点如下执行脚本
nohup kafka-server-start.sh /bigdata/install/kafka/config/server.properties >/dev/null 2>&1 &
SHELL 复制 全屏
2、停止kafka集群
所有节点执行关闭kafka脚本
kafka-server-stop.sh
kafka命令行的管理使用
1、创建topic
使用
kafka-topics.sh脚本kafka-topics.sh --create --partitions 3 --replication-factor 2 --topic test --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181
2、查询所有的topic
使用
kafka-topics.sh脚本kafka-topics.sh --list --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181
3、查看topic的描述信息
使用
kafka-topics.sh脚本kafka-topics.sh --describe --topic test --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181
4、删除topic
使用
kafka-topics.sh脚本kafka-topics.sh --delete --topic test --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181
5、模拟生产者写入数据到topic中
使用
kafka-console-producer.sh脚本kafka-console-producer.sh --broker-list hadoop01:9092,hadoop02:9092,hadoop03:9092 --topic test
6、模拟消费者拉取topic中的数据
使用
kafka-console-consumer.sh脚本kafka-console-consumer.sh --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 --topic test --from-beginning
或者
kafka-console-consumer.sh --bootstrap-server hadoop01:9092,hadoop02:9092,hadoop03:9092 --topic test --from-beginning
kafka集群起停脚本
脚本位置
cd /home/hadoop/bin
脚本内容
vi kafka.sh
#输入以下内容
#!/bin/bash
case $1 in
"start" ){
for(( i = 1;i <= 3;i = $i +1));do
echo ============ hadoop0$i kafka $1 ===================
ssh hadoop$i "source /etc/profile;nohup kafka-server-start.sh /bigdata/install/kafka/config/server.properties >/dev/null 2>&1 &"
done
};;
"stop" ){
for(( i = 1;i <= 3;i = $i +1));do
echo ============ hadoop0$i kafka $1 ===================
ssh hadoop$i "source /etc/profile;kafka-server-stop.sh"
done
};;
esac
修改文件权限
chmod 777 kafka.sh
执行脚本,验证脚本
# 先确保已经启动了zookeeper
kafka.sh start
xcall jps
# 输出以下内容
============= hadoop1 jps =============
9616 Jps
9267 Kafka
9191 QuorumPeerMain
============= hadoop2 jps =============
8291 Kafka
8213 QuorumPeerMain
8632 Jps
============= hadoop3 jps =============
7129 Kafka
7053 QuorumPeerMain
7470 Jps
kafka.sh stop
xcall jps
# 输出以下内容
============= hadoop1 jps =============
9191 QuorumPeerMain
9740 Jps
============= hadoop2 jps =============
8213 QuorumPeerMain
8748 Jps
============= hadoop3 jps =============
7585 Jps
7053 QuorumPeerMainkafka介绍和使用的更多相关文章
- Apache Kafka - 介绍
原文地址地址: http://blogxinxiucan.sh1.newtouch.com/2017/07/12/Apache-Kafka-介绍/ Apache Kafka教程 之 Apache Ka ...
- 1、Kafka介绍
1.Kafka介绍 1)在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算. 2)Kafka是一个分布式消息队列. 3)Kafka对消息保存时根据Topic进行归类, ...
- [转]kafka介绍
转自 https://www.cnblogs.com/hei12138/p/7805475.html kafka介绍 1.1. 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台 ...
- Kafka介绍及安装部署
本节内容: 消息中间件 消息中间件特点 消息中间件的传递模型 Kafka介绍 安装部署Kafka集群 安装Yahoo kafka manager kafka-manager添加kafka cluste ...
- kafka介绍与搭建(单机版)
一.kafka介绍 1.1 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台,它主要有3种功能: 1:It lets you publish and subscribe to ...
- kafka介绍及安装配置(windows)
Kafka介绍 Kafka是分布式的发布—订阅消息系统.它最初由LinkedIn(领英)公司发布,使用Scala和Java语言编写,与2010年12月份开源,成为Apache的顶级项目.Kafka是一 ...
- 一、kafka 介绍 && kafka-client
一.kafka 介绍 1.1.kafka 介绍 Kafka 是一个分布式消息引擎与流处理平台,经常用做企业的消息总线.实时数据管道,有的还把它当做存储系统来使用. 早期 Kafka 的定位是一个高吞吐 ...
- 3 kafka介绍
本博文的主要内容有 .kafka的官网介绍 http://kafka.apache.org/ 来,用官网上的教程,快速入门. http://kafka.apache.org/documentatio ...
- Kafka介绍
本文介绍LinkedIn开源的Kafka,久仰大名了,依照其官方文档做些翻译和二次创作.相应能够查看整份官方文档. 基本术语 topics,维护的消息源种类(更像是业务上的数据种类/分类) produ ...
- 漫游Kafka介绍章节简介
原文地址:http://blog.csdn.net/honglei915/article/details/37564521 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息 ...
随机推荐
- hbase的管理相关看法
运维任务 regionserver添加/删除节点 master备份 1 添加新节点 复制hbase目录并进行配置文件修改(regionserver增加新节点)并保持配置文件在全集群一致,在新节点上启动 ...
- 题解:【XR-3】核心城市
题解:[XR-3]核心城市 思路一:考虑由特例推广到一般 1.很容易想到先考虑一个关键点的情况,然后再推广到一般情况. 2.一个点肯定选距离上最平衡的那个点,即树的中心.接着在中心周围贪心的选剩下的( ...
- 使用switch语句的注意事项
目录 case后需要手动break switch内的变量定义 变量没有定义在语句块内 变量定义在语句块内 表述多情况时不能用逗号 case后需要手动break switch(i){ case 1: 语 ...
- .NET Core 反射底层原理浅谈
简介 反射,反射,程序员的快乐. 前期绑定与后期绑定 在.NET中,前期绑定(Early Binding)是指在编译时就确定了对象的类型和方法,而后期绑定(Late Binding)或动态绑定是在运行 ...
- JESD79-5C_v1.30-2024 JEDEC DDR5 SOLID STATE TECHNOLOGY ASSOCIATION 最新内存技术规范
JESD79-5C_v1.30-2024 JEDEC DDR5 SOLID STATE TECHNOLOGY ASSOCIATION 最新DDR5内存技术规范 JEDEC 技术协会公布新 DDR5 ...
- php 安装扩展 event
本地环境php8.1,然后我想安装event扩展,找了找资料,直接一句话 sudo pecl install event 然后执行的过程中提示这些 configure.ac:165: the top ...
- MMORPG技能管线设计经验总结
导语: 表现丰富.机制多变的技能作为MMORPG游戏战斗体验的核心组成部分,是吸引玩家的一大亮点,本文总结了在MMORPG技能系统设计上的一些经验,供大家参考. 1.设计思路 早期的MMORPG手游中 ...
- ibatis源码分析
背景:调试模式下,单步运行一个查询订单协议操作,记录了ibatis框架的执行动作,侧面剖析其原理. 一.简介: 1. dal 层的dao接口实现类通常会继承SqlMapClientDaoSupport ...
- Mybatis【9】-- Mybatis占位符#{}和拼接符${}有什么区别?
代码直接放在Github仓库[https://github.com/Damaer/Mybatis-Learning ],可直接运行,就不占篇幅了. 目录 1.#{}占位符 2.${}拼接符 3.#{} ...
- Word转Pdf方式
最近在工作中需要将word文件转换为pdf文件,找了很多种方式.以下简单列一下: 一.Aspose-words(推荐) 使用Aspose比较方便,转换之后格式这些基本没什么问题.我也使用的此种方式.正 ...