6. Calcite添加自定义函数
1. 简介
在上篇博文中介绍了如何使用calcite进行sql验证, 但是真正在实际生产环境中我们可能需要使用到
- 用户自定义函数(UDF): 通过代码实现对应的函数逻辑并注册给calcite
- sql验证: 将UDF信息注册给calcite,
SqlValidator.validator验证阶段即可通过验证 - sql执行: calcite通过调用UDF逻辑实现函数逻辑
- sql验证: 将UDF信息注册给calcite,
- 自定义db函数: 数据库中创建的自定义函数
- sql验证: 将自定义的db函数信息注册给calcite,
SqlValidator.validator验证阶段即可通过验证 - sql执行: 下推到db执行对应的db函数
- sql验证: 将自定义的db函数信息注册给calcite,
此时我们需要将自定义的函数注册到calcite中, 用于sql验证和执行. 例如注册一个简单的函数 如: 将数据库中的性别字段值做字典转换.
2. Maven
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<version>1.37.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
2. UDF
如上述所说, UDF是将用户自定义的方法注册为函数使用的, 首先看一下calcite是如何注册UDF的
SchemaPlus#add(String name, Function function);
其Function的实现类如下:
定义UDF实现
public class Udf {
public static String dictSex(String code) {
if (StringUtils.isBlank(code)) {
return code;
}
if (StringUtils.equals(code, "1")) {
return "男";
} else if (StringUtils.equals(code, "2")) {
return "女";
}
else {
return "未知";
}
}
}
把
dictSex方法注册到calcite中, 因为上述的方法输入返回的都是单一值, 所以直接注册为标量函数即可(如果是聚合函数可以使用AggregateFunction)// 指定函数名称 和 对应函数的class & method name
rootSchema.add("dict_sex", ScalarFunctionImpl.create(Udf.class, "dictSex"));
测试执行
final ResultSet resultSet = statement.executeQuery("SELECT username, dict_sex(sex) sex_name FROM `user`");
printResultSet(resultSet);
表数据如下
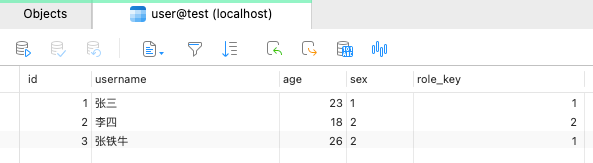
输出结果
c.l.c.CalciteFuncTest - [printResultSet,86] - Number of columns: 2
c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=男, username=张三}
c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=李四}
c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=张铁牛}
3. 自定义db函数
首先 我们定义一个db 函数实现字典值的转换
DELIMITER //
CREATE FUNCTION dict_sex(code VARCHAR(10))
RETURNS VARCHAR(10)
DETERMINISTIC
BEGIN
-- 如果code为空或只包含空白字符,则直接返回code
IF code IS NULL OR TRIM(code) = '' THEN
RETURN code;
END IF;
-- 如果code为'1'则返回'男'
IF code = '1' THEN
RETURN '男';
-- 如果code为'2'则返回'女'
ELSEIF code = '2' THEN
RETURN '女';
ELSE
RETURN '未知';
END IF;
END //
DELIMITER ;
验证函数功能

ok, 函数创建完成, 我们将函数注册到calcite中
calcite中sqlfunction有很多其已经实现的类, 我们这里使用SqlBasicFunction来创建我们的函数
定义SqlFunction
/*
* SqlBasicFunction create(String name, SqlReturnTypeInference returnTypeInference, SqlOperandTypeChecker operandTypeChecker)
* name: 函数名称
* returnTypeInference: 返回值类型
* operandTypeChecker: 函数入参的校验器
*/
SqlFunction DICT_SEX = SqlBasicFunction.create("dict_sex", ReturnTypes.VARCHAR, OperandTypes.family(SqlTypeFamily.CHARACTER));
注册SqlFunction
从上篇博文中我们知道, calcite的sql函数都注册到了
SqlStdOperatorTable类中, 所以我们只需要将自定义的函数注册进即可final SqlStdOperatorTable sqlStdOperatorTable = SqlStdOperatorTable.instance();
sqlStdOperatorTable.register(DICT_SEX);
对, 就这么简单. 因为
SqlStdOperatorTable类是单例模式, 所以我们可以随时随地的进行注册, 其验证逻辑就可以直接调用了当然, 看了其他博客大多数都是继承
SqlStdOperatorTable类实现自定义SqlStdOperatorTable的 如下, 最后使用自己的SqlStdOperatorTable即可public static class SqlCustomOperatorTable extends SqlStdOperatorTable {
private static SqlCustomOperatorTable instance;
// 只需要申明为成员变量即可, instance.init() 的时候会反射取变量进行注册
public static final SqlFunction DICT_SEX = SqlBasicFunction.create("dict_sex", ReturnTypes.VARCHAR, OperandTypes.family(SqlTypeFamily.CHARACTER)); public static synchronized SqlCustomOperatorTable instance() {
if (instance == null) {
instance = new SqlCustomOperatorTable();
instance.init();
} return instance;
} /**
* 如果想修改获取函数的过程, 可以重写此方法
*/
@Override
protected void lookUpOperators(String name, boolean caseSensitive, Consumer<SqlOperator> consumer) {
super.lookUpOperators(name, caseSensitive, consumer);
}
}
测试执行
final ResultSet resultSet = statement.executeQuery("SELECT username, dict_sex(sex) sex_name FROM `user`");
printResultSet(resultSet);
输出结果
c.l.c.CalciteFuncTest - [printResultSet,86] - Number of columns: 2
c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=男, username=张三}
c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=李四}
c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=张铁牛}
经测试: 如果udf 和 sqlfunction 同时存在的时候 优先使用udf
4. 完整代码
4.1 udf
package com.ldx.calcite;
import com.google.common.collect.Maps;
import com.mysql.cj.jdbc.MysqlDataSource;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.apache.calcite.adapter.jdbc.JdbcSchema;
import org.apache.calcite.config.Lex;
import org.apache.calcite.jdbc.CalciteConnection;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.schema.impl.ScalarFunctionImpl;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Map;
import java.util.Properties;
import static org.apache.calcite.config.CalciteConnectionProperty.LEX;
@Slf4j
public class CalciteFuncWithUdfTest {
private static Statement statement;
@BeforeAll
@SneakyThrows
public static void beforeAll() {
Properties info = new Properties();
// 不区分sql大小写
info.setProperty("caseSensitive", "false");
info.setProperty(LEX.camelName(), Lex.MYSQL.name());
// 创建Calcite连接
Connection connection = DriverManager.getConnection("jdbc:calcite:", info);
CalciteConnection calciteConnection = connection.unwrap(CalciteConnection.class);
// 构建RootSchema,在Calcite中,RootSchema是所有数据源schema的parent,多个不同数据源schema可以挂在同一个RootSchema下
SchemaPlus rootSchema = calciteConnection.getRootSchema();
// 设置默认的schema, 如果不设置sql中需要加上对应数据源的名称
calciteConnection.setSchema("my_mysql");
final DataSource mysqlDataSource = getMysqlDataSource();
final JdbcSchema schemaWithMysql = JdbcSchema.create(rootSchema, "my_mysql", mysqlDataSource, "test", null);
final SchemaPlus myMysqlSchema = rootSchema.add("my_mysql", schemaWithMysql);
// 全局注册
rootSchema.add("dict_sex", ScalarFunctionImpl.create(Udf.class, "dictSex"));
statement = calciteConnection.createStatement();
// 只注册到mysql schema中
// myMysqlSchema.add("dict_sex", ScalarFunctionImpl.create(Udf.class, "dictSex"));
// 创建SQL语句执行查询
statement = calciteConnection.createStatement();
}
@Test
@SneakyThrows
public void test_udf_func() {
final ResultSet resultSet = statement.executeQuery("SELECT username, dict_sex(sex) sex_name FROM `user`");
printResultSet(resultSet);
}
private static DataSource getMysqlDataSource() {
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/test");
dataSource.setUser("root");
dataSource.setPassword("123456");
return dataSource;
}
public static void printResultSet(ResultSet resultSet) throws SQLException {
// 获取 ResultSet 元数据
ResultSetMetaData metaData = resultSet.getMetaData();
// 获取列数
int columnCount = metaData.getColumnCount();
log.info("Number of columns: {}",columnCount);
// 遍历 ResultSet 并打印结果
while (resultSet.next()) {
final Map<String, String> item = Maps.newHashMap();
// 遍历每一列并打印
for (int i = 1; i <= columnCount; i++) {
String columnName = metaData.getColumnName(i);
String columnValue = resultSet.getString(i);
item.put(columnName, columnValue);
}
log.info(item.toString());
}
}
}
4.2 db func
package com.ldx.calcite;
import com.google.common.collect.Maps;
import com.mysql.cj.jdbc.MysqlDataSource;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.apache.calcite.adapter.jdbc.JdbcSchema;
import org.apache.calcite.config.Lex;
import org.apache.calcite.jdbc.CalciteConnection;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.sql.SqlBasicFunction;
import org.apache.calcite.sql.SqlFunction;
import org.apache.calcite.sql.SqlOperator;
import org.apache.calcite.sql.fun.SqlStdOperatorTable;
import org.apache.calcite.sql.type.OperandTypes;
import org.apache.calcite.sql.type.ReturnTypes;
import org.apache.calcite.sql.type.SqlTypeFamily;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Map;
import java.util.Properties;
import java.util.function.Consumer;
import static org.apache.calcite.config.CalciteConnectionProperty.LEX;
@Slf4j
public class CalciteFuncWithDbTest {
private static Statement statement;
public static final SqlFunction DICT_SEX = SqlBasicFunction.create("dict_sex", ReturnTypes.VARCHAR, OperandTypes.family(SqlTypeFamily.CHARACTER));
@BeforeAll
@SneakyThrows
public static void beforeAll() {
Properties info = new Properties();
// 不区分sql大小写
info.setProperty("caseSensitive", "false");
info.setProperty(LEX.camelName(), Lex.MYSQL.name());
// 创建Calcite连接
Connection connection = DriverManager.getConnection("jdbc:calcite:", info);
CalciteConnection calciteConnection = connection.unwrap(CalciteConnection.class);
// 构建RootSchema,在Calcite中,RootSchema是所有数据源schema的parent,多个不同数据源schema可以挂在同一个RootSchema下
SchemaPlus rootSchema = calciteConnection.getRootSchema();
// 设置默认的schema, 如果不设置sql中需要加上对应数据源的名称
calciteConnection.setSchema("my_mysql");
final DataSource mysqlDataSource = getMysqlDataSource();
final JdbcSchema schemaWithMysql = JdbcSchema.create(rootSchema, "my_mysql", mysqlDataSource, "test", null);
rootSchema.add("my_mysql", schemaWithMysql);
final SqlStdOperatorTable sqlStdOperatorTable = SqlStdOperatorTable.instance();
sqlStdOperatorTable.register(DICT_SEX);
statement = calciteConnection.createStatement();
}
@Test
@SneakyThrows
public void test_db_func() {
final ResultSet resultSet = statement.executeQuery("SELECT dict_sex(sex) sex_name FROM `user`");
printResultSet(resultSet);
}
private static DataSource getMysqlDataSource() {
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/test");
dataSource.setUser("root");
dataSource.setPassword("123456");
return dataSource;
}
public static void printResultSet(ResultSet resultSet) throws SQLException {
// 获取 ResultSet 元数据
ResultSetMetaData metaData = resultSet.getMetaData();
// 获取列数
int columnCount = metaData.getColumnCount();
log.info("Number of columns: {}",columnCount);
while (resultSet.next()) {
final Map<String, String> item = Maps.newHashMap();
// 遍历每一列并打印
for (int i = 1; i <= columnCount; i++) {
String columnName = metaData.getColumnName(i);
String columnValue = resultSet.getString(i);
item.put(columnName, columnValue);
}
log.info(item.toString());
}
}
public static class SqlCustomOperatorTable extends SqlStdOperatorTable {
private static SqlCustomOperatorTable instance;
// 只需要申明为成员变量即可, instance.init() 的时候会反射取变量进行注册
public static final SqlFunction DICT_SEX = SqlBasicFunction.create("dict_sex", ReturnTypes.VARCHAR, OperandTypes.family(SqlTypeFamily.CHARACTER));
public static synchronized SqlCustomOperatorTable instance() {
if (instance == null) {
instance = new SqlCustomOperatorTable();
instance.init();
}
return instance;
}
/**
* 如果想修改获取函数的过程, 可以重写此方法
*/
@Override
protected void lookUpOperators(String name, boolean caseSensitive, Consumer<SqlOperator> consumer) {
super.lookUpOperators(name, caseSensitive, consumer);
}
}
}
6. Calcite添加自定义函数的更多相关文章
- KnockoutJS 3.X API 第七章 其他技术(6) 使用“fn”添加自定义函数
有时,您可能会通过向Knockout的核心值类型添加新功能来寻找机会来简化您的代码. 您可以在以下任何类型中定义自定义函数: 因为继承,如果你附加一个函数到ko.subscribable,它将可用于所 ...
- Hadoop3集群搭建之——hive添加自定义函数UDTF (一行输入,多行输出)
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- Hadoop3集群搭建之——hive添加自定义函数UDTF
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- Hadoop3集群搭建之——hive添加自定义函数UDF
上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hive安装 Hadoo ...
- dede添加自定义函数
在dede安装目录下的include/extend.func.php添加自定义函数: /** * 获取文章第一张图片 */ function getFirstImg($arcId) { global ...
- jmeter的使用--添加自定义函数和导入自定义jar
1.添加自定义函数,增加 号码生成函数 MobileGenerator和身份证生成函数IdCardGenerator 在package org.apache.jmeter.functions;中增加 ...
- qt实现-给SQLITE添加自定义函数
需要使用sqlite里的password对某个字段进行加密,由于使用的sqlite是由QT封装好的QSqlDatabase,没有发现加载扩展函数的方法,所以自己实现了一个. 在网上也没找到相应的参考, ...
- JMeter-Eclipse添加自定义函数 MD5加密 32位和16位
最近公司的接口都是MD5 16位加密,所以要使用加密功能. 之前也做过加密,因为用的比较少,所以是写了一个加密方法,导出JAR包,调用的.用起来需要很多设置,并且换算效率也不高.听前同事说,jmet ...
- 性能测试Jmeter扩展学习-添加自定义函数
我们在使用jmeter的时候有时候会碰到jmeter现有插件或功能也无法支持的场景,比如前端加密,此时我们就需要自己手动编写函数并导入了,下面就是手动修改并导入的过程. 首先我们需要下载jmeter源 ...
- Jmeter函数助手中添加自定义函数
最近,群里的牛肉面大神有个需求,是将每个post请求的body部分做一个加密操作,其实这个需求不算难,用beanshell引入加密函数的包,然后调用就行了.只是,如果请求多了,每次都要调用一下自己加密 ...
随机推荐
- JavaScript 的 Mixin 问题
JavaScript 从 ES6 开始支持 class 了, 如何在现在的 class 上实现 mixin 呢? 很多人推荐这种搞法 Object.assign(MyClass.prototype, ...
- JEP 462 结构化并发是一个很愚蠢的提案
https://openjdk.org/jeps/462 Motivation Developers manage complexity by breaking tasks down into mul ...
- d2js 中实现 memcached 共享 session 的过程
https://github.com/inshua/d2js/blob/master/WebContent/guide/memcached-session.md 基于 https://github.c ...
- 2024年1月Java项目开发指南9:密码加密存储
提前声明: 你不会写这加密算法没关系啊,你会用就行. 要求就是:你可以不会写这个加密算法,但是你要知道加密流程,你要会用. @Service public class PasswordEncrypto ...
- POST、GET、@RequestBody和@RequestParam区别
参考链接: 1.POST.GET.@RequestBody和@RequestParam区别 2.@RequestBody的使用
- 一篇文章弄懂 JavaScript 中通过import导入模块的原理
原文链接: 1.import 2.彻底理解JavaScript ES6中的import和export 3.JavaScript ES6中export.import与export default的用法和 ...
- 深入理解ASP.NET Core 管道的工作原理
在 .NET Core 中,管道(Pipeline)是处理 HTTP 请求和响应的中间件组件的有序集合.每个中间件组件都可以对请求进行处理,并将其传递给下一个中间件组件,直到请求到达最终的处理程序.管 ...
- Solution Set - “说选个晴日,露能滴出彩虹”
目录 0.「BZOJ #3457」Ring 1.「CF 1824C」LuoTianyi and XOR-Tree 2.「CF 1824D」LuoTianyi and the Function 3.「C ...
- JS利用浏览器进行语言识别
JS利用浏览器进行语言识别 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- 连接Redis 错误的解决方法: It was not possible to connect to the redis server(s); to create a disconnected multiplexer
The error you are getting is usually a sign that you have not set abortConnect=false in your connect ...