Storm与Hadoop的角色和组件比较
Storm与Hadoop的角色和组件比较
Storm 集群和 Hadoop 集群表面上看很类似。但是 Hadoop 上运行的是 MapReduce 作业,而在 Storm 上运行的是拓扑 Topology,这两者之间是非常不同的。一个关键的区别是:一个MapReduce 作业最终会结束,而一个 Topology 拓扑会永远运行(除非手动杀掉)。表 1-1 列出了 Hadoop 与 Storm 的不同之处。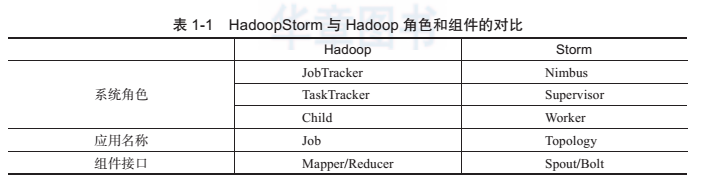
如果只用一个短语来描述 Storm,可能会是这样:分布式实时计算系统。按照 Storm 作者的说法, Storm 对于实时计算的意义类似于 Hadoop 对于批处理的意义。众所周知,根据Google MapReduce 来实现的 Hadoop 提供了 Map 和 Reduce 原语,使批处理程序变得非常简单和优美。那么 Storm 则是在批处理之前,及时处理了数据。
Storm 与其他大数据解决方案的不同之处在处理方式上。Hadoop 在本质上是一个批处理系统。数据被引入 HDFS 并分发到各个节点进行处理。当处理完成时,结果数据返回到HDFS 供始发者使用。 Storm 支持创建拓扑结构来转换没有终点的数据流。不同于 Hadoop 作业,这些转换从不停止,它们会持续处理到达的数据。
Hadoop 专注于批处理。这种模型对许多情形(如为网页建立索引)已经足够,但还存在其他一些使用模型,它们需要来自高度动态来源的实时信息。为了解决该问题,就得借助 Twitter 推出的 Storm。 Storm 不处理静态数据,但它处理预计会连续的流数据。考虑到Twitter 用户每天生成 1.4 亿条推文,很容易看到此技术的巨大用途。
Storm 不只是一个传统的大数据分析系统:它是复杂事件处理(CEP)系统的一个示例。CEP 系统通常分为计算和面向检测两类,其中每个系统都可通过用户定义的算法在 Storm 中实现。例如, CEP 可用于识别事件洪流中有意义的事件,然后实时处理这些事件。
Storm 作者 Nathan Marz 提供了在 Twitter 中使用 Storm 的大量示例。一个最有趣的示例是生成趋势信息。 Twitter 从海量的推文中提取所浮现的趋势,并在本地和国家级别维护这些趋势信息。这意味着当一个案例开始浮现时, Twitter 的趋势主题算法就会实时识别该主题。这种实时算法是使用 Storm 实现的基于 Twitter 数据的一种连续分析。
Storm与Hadoop的角色和组件比较的更多相关文章
- Storm概念学习系列之Storm与Hadoop的角色和组件比较
不多说,直接上干货! Storm与Hadoop的角色和组件比较 Storm 集群和 Hadoop 集群表面上看很类似.但是 Hadoop 上运行的是 MapReduce 作业,而在 Storm 上运行 ...
- 大数据框架hadoop服务角色介绍
翻了一下最近一段时间写的分享,DKHadoop发行版本下载.安装.运行环境部署等相关内容几乎都已经写了一遍了.虽然有的地方可能写的不是很详细,个人理解水平有限还请见谅吧!我记得在写DKHadoop运行 ...
- Storm和Hadoop 区别
Storm - 大数据Big Data实时处理架构 什么是Storm? Storm是:• 快速且可扩展伸缩• 容错• 确保消息能够被处理• 易于设置和操作• 开源的分布式实时计算系统- 最初由Na ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop生态圈-Flume的组件之自定义拦截器(interceptor)
Hadoop生态圈-Flume的组件之自定义拦截器(interceptor) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是举例了一个自定义拦截器的方法,测试字节传输速 ...
- Hadoop生态圈-Flume的组件之自定义Sink
Hadoop生态圈-Flume的组件之自定义Sink 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客主要介绍sink相关的API使用两个小案例,想要了解更多关于API的小技 ...
- Hadoop生态圈-Flume的组件之sink处理器
Hadoop生态圈-Flume的组件之sink处理器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. 二.
- Hadoop生态圈-Flume的组件之拦截器与选择器
Hadoop生态圈-Flume的组件之拦截器与选择器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Interceptors,想要了解更详细 ...
- Hadoop YARN学习之组件功能简述(3)
Hadoop YARN学习之组件功能简述(3) 1. YARN的三大组件功能简述: ResourceManager(RM)是集群的资源的仲裁者, 它有两部分:一个可插拔的调度器和一个Applicati ...
随机推荐
- C#.net winform 控件和皮肤大全
1. 东日IrisSkin IrisSkin 共有两个版本,一个是IrisSkin.dll 用于.Net Framework1.0/1.1 和IrisSkin2.dll 用于.Net Framewor ...
- DOS系统里,分屏显示目录的命令是什么??
dir /sdir /pdir /w 我记得这三个都是我当年常用的命令,有分瓶的,有滚动时候每页停顿的,还有去掉详细信息的吧,, 可以放在一起使用.如dir /p/w /p是滚动时候中间停顿的,/w是 ...
- Hibernate与数据库分表
数据库分片(shard)是一种在数据库的某些表变得特别大的时候采用的一种技术. 通过按照一定的维度将表切分,可以使该表在常用的检索中保持较高的效率,而那些不常用的记录则保存在低访问表中.比如:销售记录 ...
- C#.net调用axis2webService
用C#.net调用axis2webService的时候需要引用web服务, 比如访问地址为:http://111.21.32.213:8080/axis2/services/AdService/get ...
- 转 JavaScript 操作select控件大全(新增、修改、删除、选中、清空、判断存在等)
收藏一下 1.判断select选项中 是否存在Value=”paraValue”的Item2.向select选项中 加入一个Item3.从select选项中 删除一个Item4.删除select中选中 ...
- sqlserver 2008express版本启用混合登陆和sa
本机环境:win10 64位 vs2010及其自带的数据库 sqlserver2008 express版本 用命令行登陆数据库: osql -E -Slocalhost\sqlexpress 登陆成 ...
- 计算器(console version)
题目描述 请用python编写一个计算器的控制台程序,支持加减乘除.乘方.括号.小数点,运算符优先级为括号>乘方>乘除>加减,同级别运算按照从左向右的顺序计算. 输入描述 数字包括& ...
- MySql从服务器延迟解决方案
在从服务器上执行show slave status;可以查看到很多同步的参数,我们需要特别注意的参数如下:Master_Log_File: SLAVE中的I/ ...
- linux如何关闭防火墙
1) 重启后生效 开启: chkconfig iptables on 关闭: chkconfig iptables off 2) 即时生效,重启后失效 开启: service iptables sta ...
- [unity菜鸟] 修改发布成web后的logo
1. 原始效果 (tip:在4.x的书中有介绍) 2. 打开.html文件原始代码如下 <script type='text/javascript' src='jquery.min.js'&g ...