Hadoop生态圈-Flume的组件之拦截器与选择器
Hadoop生态圈-Flume的组件之拦截器与选择器
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
本篇博客只是配置的是Flume主流的Interceptors,想要了解更详细的配置信息请参考官网:http://flume.apache.org/FlumeUserGuide.html#flume-interceptors。
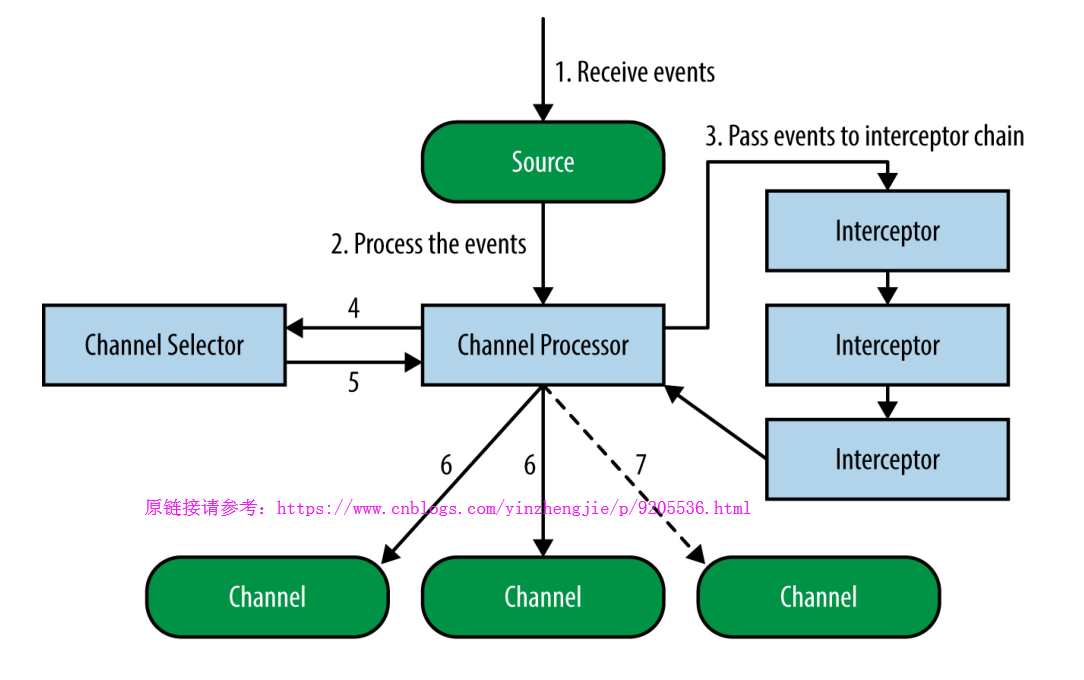
想必大家都知道Flume的组件有Source,channel和sink。其实在Flume还有一些更深层的东西,比如你知道soucre是如何将数据传送给channel的吗?那你有知道channel又是如何将数据发送给sink的吗?对于一个Agent来说,它只能有一个source,但是它可以有多个channel和sink,如下图:
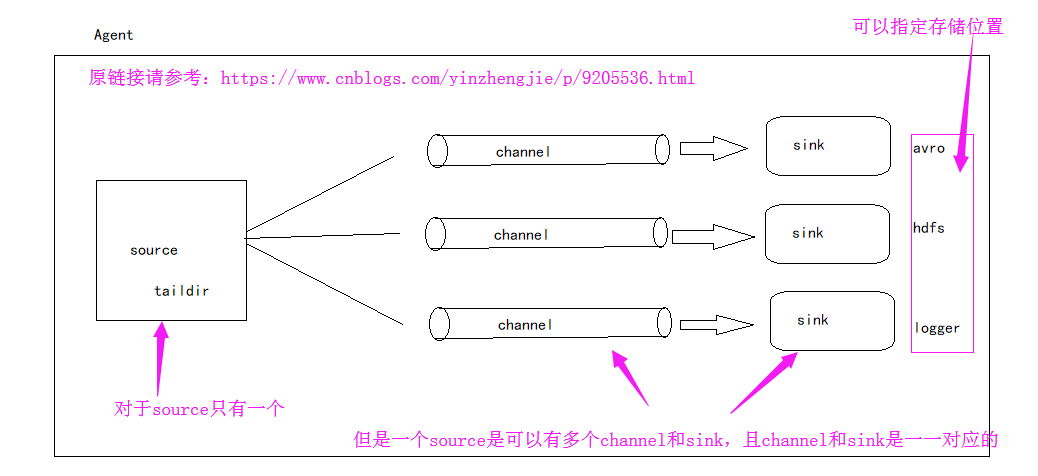
接下来就跟着我一起了了解一下更深层次的知识吧。接下来我们就一起探讨一下source是如何将数据发送到channel中的,以及sink是处理数据的。
一.Source端源码查看
1>.获取一行数据,使用其构建Event

2>.使用processEvent处理数据
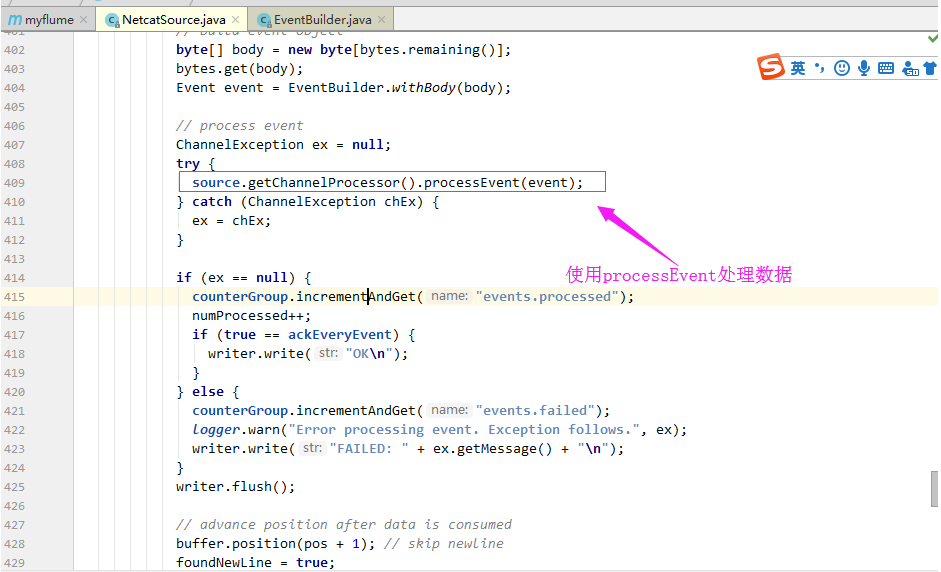
3>.在处理过程中,event需要通过拦截器链,相当于过滤数据
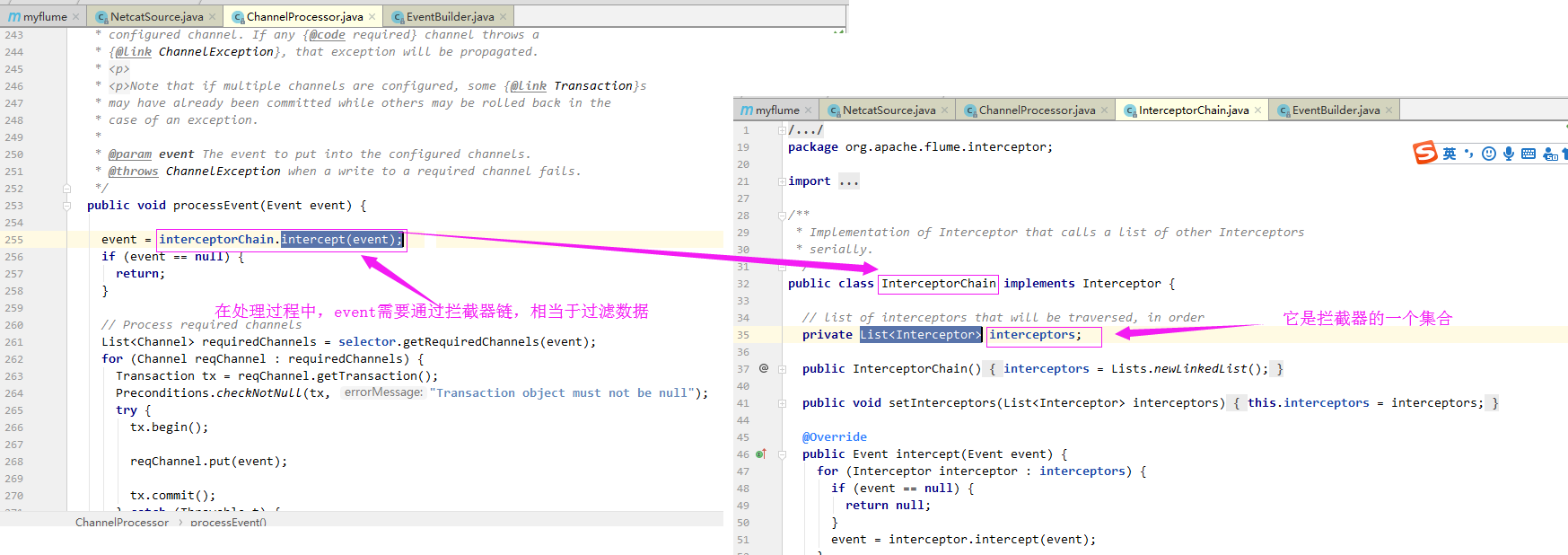
4>.在拦截器链中,通过迭代所有拦截器,对数据进行多次处理(例如:host拦截器,是对event进行添加头部操作)
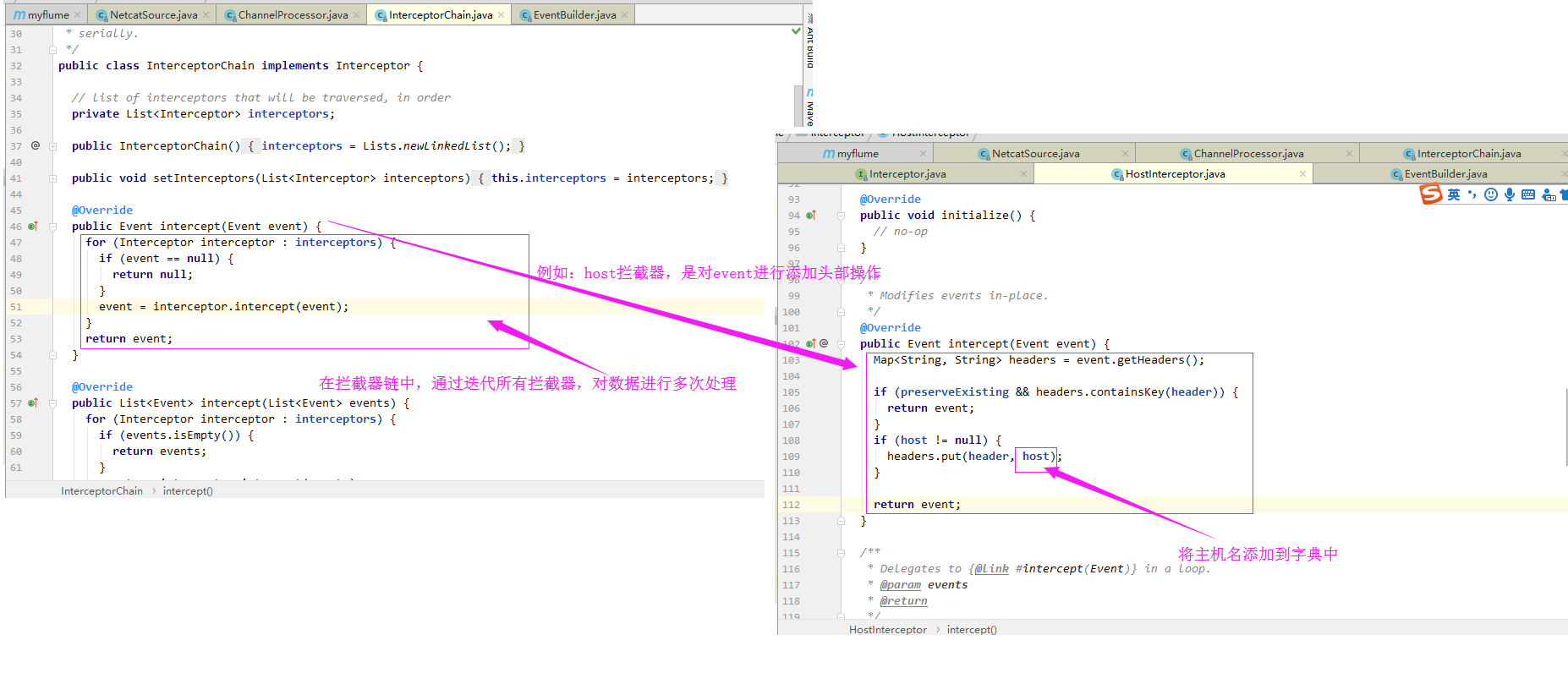
5>.通过拦截器处理后的event,再次进入到通道挑选器
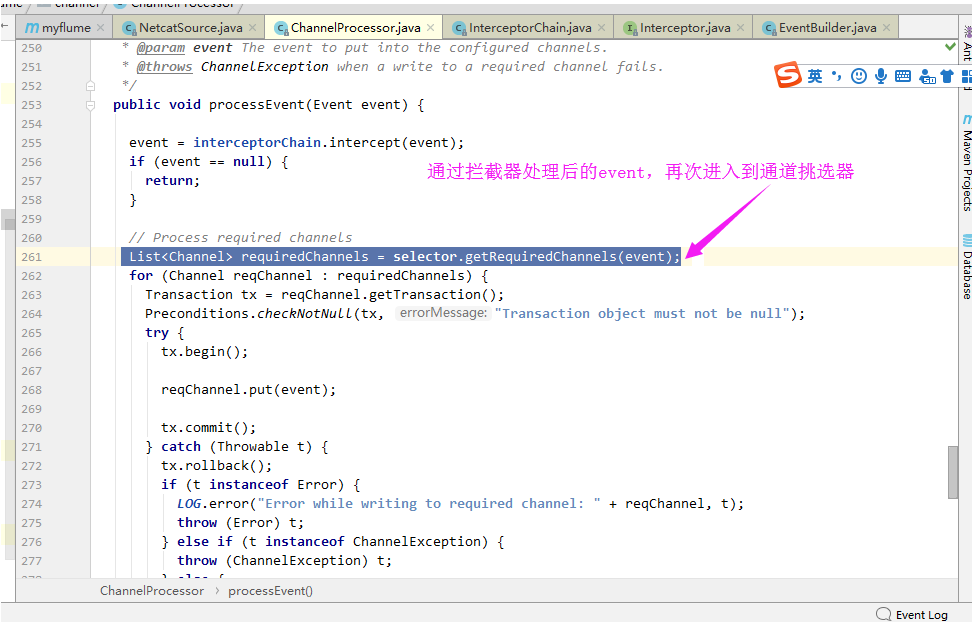
6>.迭代所有channel,将数据放进channel中

通过上面的源码解析,看下面这张图应该就不是什么难事了吧:
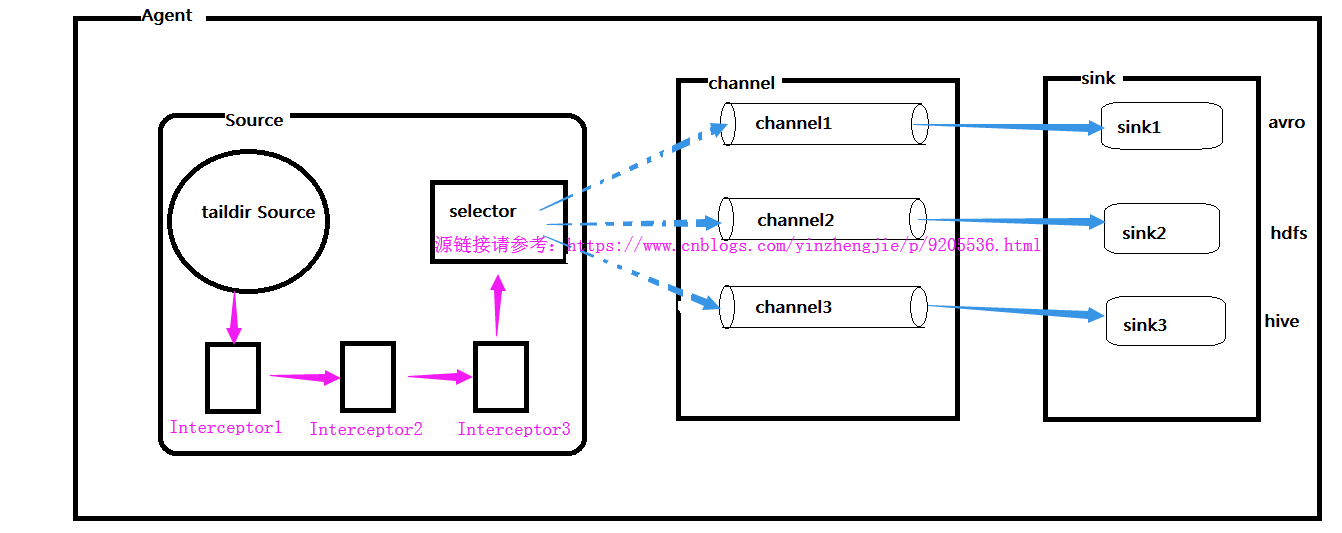
这个时候,你是否绝对第一张图画得并不自信呢?这个时候我们可以把第一张图的Source端流程画得更详细一点,如下:
二.拦截器(Interceptors)
1>.Interceptors 功能
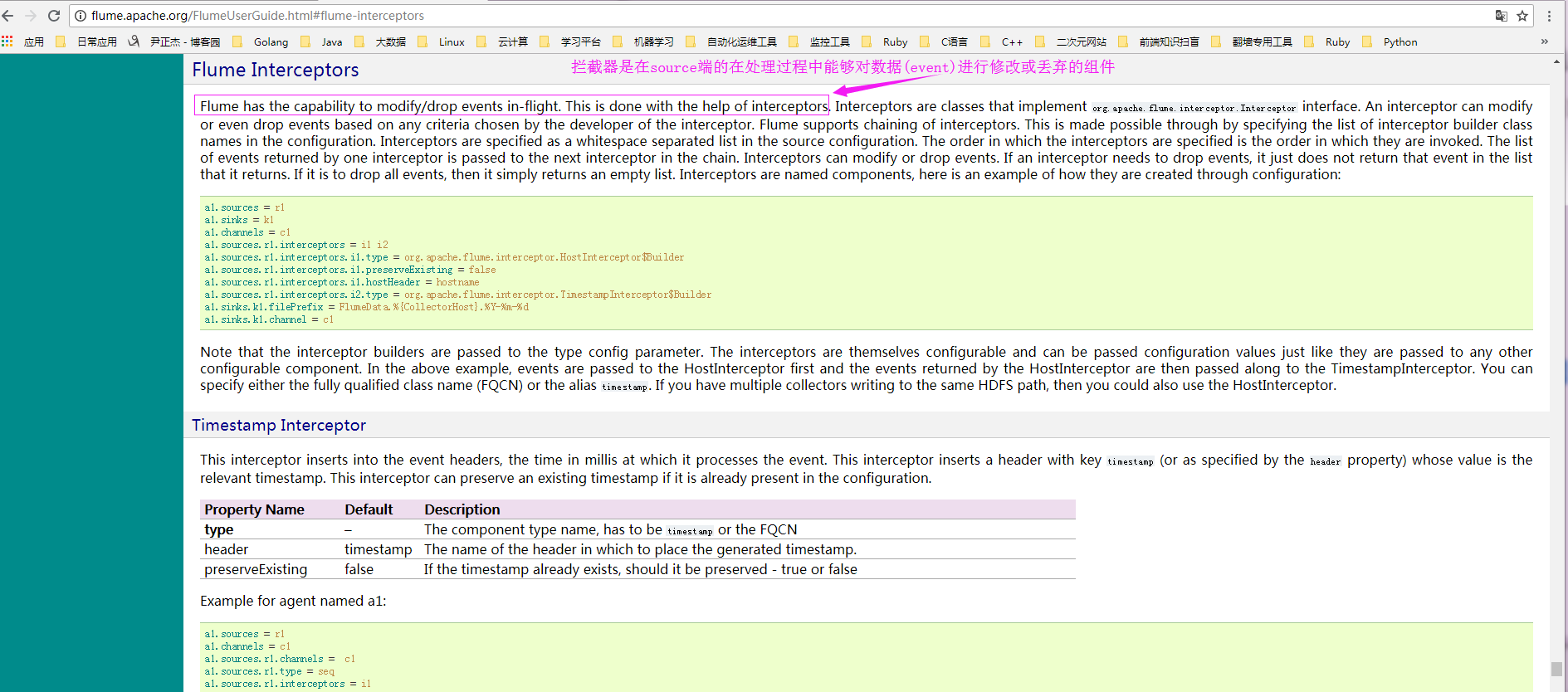
答:拦截器是在source端的在处理过程中能够对数据(event)进行修改或丢弃的组件。
2>.官方文档
3>.host interceptor(将发送的event添加主机名的header)配置案例
a>.实际配置参数:
[yinzhengjie@s101 ~]$ more /soft/flume/conf/yinzhengjie_hostInterceptor.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = # 指定添加拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.HostInterceptor$Builder
a1.sources.r1.interceptors.i1.preserveExisting = false
# 指定header的key
a1.sources.r1.interceptors.i1.hostHeader = hostname
# 指定header的value为主机ip
a1.sources.r1.interceptors.i1.useIP = true # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
[yinzhengjie@s101 ~]$
b>启动agent进程:
c>.source端产生数据(启动nc):
d>.检查sink端数据(检查定义好的目录"/home/yinzhengjie/log2")
4>.static interceptor(静态拦截器,手动指定key-value)配置案例
a>.实际配置参数:
[yinzhengjie@s101 ~]$ more /soft/flume/conf/yinzhengjie_staticInterceptor.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = # 指定添加拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = name
a1.sources.r1.interceptors.i1.value = yinzhengjie # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
[yinzhengjie@s101 ~]$
b>启动agent进程:
c>.source端产生数据(启动nc):
d>.检查sink端数据(检查定义好的目录"/home/yinzhengjie/log2")
5>.timestamp interceptor(将发送的event添加时间戳的header)配置案例
a>.实际配置参数:
[yinzhengjie@s101 ~]$ more /soft/flume/conf/yinzhengjie_timestampInterceptor.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = # 指定添加拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
[yinzhengjie@s101 ~]$
b>启动agent进程:
c>.source端产生数据(启动nc):
d>.检查sink端数据(检查定义好的目录"/home/yinzhengjie/log2")
6>.interceptor chain(连接器链)配置案例
a>.实际配置参数:
[yinzhengjie@s101 ~]$ more /soft/flume/conf/yinzhengjie_chainInterceptor.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = # 指定添加拦截器
a1.sources.r1.interceptors = i1 i2 i3
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.HostInterceptor$Builder
a1.sources.r1.interceptors.i1.preserveExisting = false
# 指定header的key
a1.sources.r1.interceptors.i1.hostHeader = hostname
# 指定header的value为主机ip
a1.sources.r1.interceptors.i1.useIP = true # 添加i2拦截器
a1.sources.r1.interceptors.i2.type = timestamp # 添加i3拦截器
a1.sources.r1.interceptors.i3.type = remove_header
a1.sources.r1.interceptors.i3.withName = timestamp # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 [yinzhengjie@s101 ~]$
b>启动agent进程:
c>.source端产生数据(启动nc):
d>.检查sink端数据(检查定义好的目录"/home/yinzhengjie/log2")
Hadoop生态圈-Flume的组件之拦截器与选择器的更多相关文章
- Hadoop生态圈-Flume的组件之自定义拦截器(interceptor)
Hadoop生态圈-Flume的组件之自定义拦截器(interceptor) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是举例了一个自定义拦截器的方法,测试字节传输速 ...
- Hadoop生态圈-Flume的组件之自定义Sink
Hadoop生态圈-Flume的组件之自定义Sink 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客主要介绍sink相关的API使用两个小案例,想要了解更多关于API的小技 ...
- Hadoop生态圈-Flume的组件之sink处理器
Hadoop生态圈-Flume的组件之sink处理器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. 二.
- Hadoop生态圈-Flume的主流source源配置
Hadoop生态圈-Flume的主流source源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Source,想要了解更详细的配置信息请参 ...
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- 基于ambari搭建hadoop生态圈大数据组件
Ambari介绍1Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应.管理和监控.Ambari已支持大多数Hadoop组件,包括HDFS.MapReduce.H ...
- Hadoop生态圈-Flume的主流Channel源配置
Hadoop生态圈-Flume的主流Channel源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. 二. 三.
- Hadoop生态圈-Flume的主流Sinks源配置
Hadoop生态圈-Flume的主流Sinks源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Sinks,想要了解更详细的配置信息请参考官 ...
- Flume 拦截器(interceptor)详解
flume 拦截器(interceptor)1.flume拦截器介绍拦截器是简单的插件式组件,设置在source和channel之间.source接收到的事件event,在写入channel之前,拦截 ...
随机推荐
- 校内模拟赛 coin
题意: n*m的棋盘,每个格子可能是反着的硬币,正着的硬币,没有硬币,每次可以选未选择的一行或者未选择的一列,将这一行/列的硬币取反.如果没有可选的或者硬币已经全部正面,那么游戏结束. 最后一次操作的 ...
- Codeforces 946D - Timetable (预处理+分组背包)
题目链接:Timetable 题意:Ivan是一个学生,在一个Berland周内要上n天课,每天最多会有m节,他能逃课的最大数量是k.求他在学校的时间最小是多少? 题解:先把每天逃课x节在学校呆的最小 ...
- vue中的单项数据流
在VUE中,数据从父组件流向(传递)给子组件,只能单向绑定,在子组件内部不应该修改父组件传递过来的数据. 如果必须修改子组件中接收的数据,可以: 1. 作为data中局部数据,进行改动 2. 作为子组 ...
- anaconda安装opencv3
opencv是C和C++语言编写的,很多教程都是基于C++语言进行学习的,可是机器学习最多的库是python写的,所以还是学学python怎么安装opencv3, 面向学习的大都是使用了anacond ...
- Java关键字 Finally执行与break, continue, return等关键字的关系
长文短总结: 在程序没有在执行到finally之前异常退出的情况下,finally是一定执行的,即在finally之前的return语句将在finally执行之后执行. finally总是在控制转移语 ...
- 《Deep Learning》(深度学习)中文版PDF免费下载
<Deep Learning>(深度学习)中文版PDF免费下载 "深度学习"经典著作<Deep Learning>中文版pdf免费下载. <Deep ...
- 科普贴 | 数字钱包MetaMask安装使用详解,活用MetaMask轻松驾驭以太坊
MetaMask 是一款浏览器插件钱包,不需下载安装客户端,只需添加至浏览器扩展程序即可使用,非常方便.它是很多支持 ETH 参投的 ICO 项目推荐使用的钱包之一. 2018年初最火的一个币,应该就 ...
- 华为笔试——C++平安果dp算法
题目:平安果 题目介绍:给出一个m*n的格子,每个格子里有一定数量的平安果,现在要求从左上角顶点(1,1)出发,每次走一格并拿走那一格的所有平安果,且只能向下或向右前进,最终到达右下角顶点(m,n), ...
- js中文汉字按拼音排序
JavaScript 提供本地化文字排序,比如对中文按照拼音排序,不需要程序显示比较字符串拼音. String.prototype.localeCompare 在不考虑多音字的前提下,基本可以完美实现 ...
- 《Linux内核分析》第三周
[李行之原创作品 转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000] <Linux内 ...