每天收获一点点------Hadoop之初始MapReduce
一、神马是高大上的MapReduce
MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算。对于大数据量的计算,通常采用的处理手法就是并行计算。但对许多开发者来说,自己完完全全实现一个并行计算程序难度太大,而MapReduce就是一种简化并行计算的编程模型,它使得那些没有多有多少并行计算经验的开发人员也可以开发并行应用程序。这也就是MapReduce的价值所在,通过简化编程模型,降低了开发并行应用的入门门槛。
1.1 MapReduce是什么
Hadoop MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。这个定义里面有着这些关键词,一是软件框架,二是并行处理,三是可靠且容错,四是大规模集群,五是海量数据集。
因此,对于MapReduce,可以简洁地认为,它是一个软件框架,海量数据是它的“菜”,它在大规模集群上以一种可靠且容错的方式并行地“烹饪这道菜”。
1.2 MapReduce做什么

简单地讲,MapReduce可以做大数据处理。所谓大数据处理,即以价值为导向,对大数据加工、挖掘和优化等各种处理。
MapReduce擅长处理大数据,它为什么具有这种能力呢?这可由MapReduce的设计思想发觉。MapReduce的思想就是“分而治之”。
(1)Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
(2)Reducer负责对map阶段的结果进行汇总。至于需要多少个Reducer,用户可以根据具体问题,通过在mapred-site.xml配置文件里设置参数mapred.reduce.tasks的值,缺省值为1。
一个比较形象的语言解释MapReduce:
We want to count all the books in the library. You count up shelf #1, I count up shelf #2. That’s map. The more people we get, the faster it goes.
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
Now we get together and add our individual counts. That’s reduce.
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
1.3 MapReduce工作机制

MapReduce的整个工作过程如上图所示,它包含如下4个独立的实体:
实体一:客户端,用来提交MapReduce作业。
实体二:JobTracker,用来协调作业的运行。
实体三:TaskTracker,用来处理作业划分后的任务。
实体四:HDFS,用来在其它实体间共享作业文件。
通过审阅MapReduce的工作流程图,可以看出MapReduce整个工作过程有序地包含如下工作环节:

二、Hadoop中的MapReduce框架
在Hadoop中,一个MapReduce作业通常会把输入的数据集切分为若干独立的数据块,由Map任务以完全并行的方式去处理它们。框架会对Map的输出先进行排序,然后把结果输入给Reduce任务。通常作业的输入和输出都会被存储在文件系统中,整个框架负责任务的调度和监控,以及重新执行已经关闭的任务。
通常,MapReduce框架和分布式文件系统是运行在一组相同的节点上,也就是说,计算节点和存储节点通常都是在一起的。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使得整个集群的网络带宽被非常高效地利用。
2.1 MapReduce框架的组成

(1)JobTracker
JobTracker负责调度构成一个作业的所有任务,这些任务分布在不同的TaskTracker上(由上图的JobTracker可以看到2 assign map 和 3 assign reduce)。你可以将其理解为公司的项目经理,项目经理接受项目需求,并划分具体的任务给下面的开发工程师。
(2)TaskTracker
TaskTracker负责执行由JobTracker指派的任务,这里我们就可以将其理解为开发工程师,完成项目经理安排的开发任务即可。
2.2 MapReduce的输入输出
MapReduce框架运转在<key,value>键值对上,也就是说,框架把作业的输入看成是一组<key,value>键值对,同样也产生一组<key,value>键值对作为作业的输出,这两组键值对有可能是不同的。
一个MapReduce作业的输入和输出类型如下图所示:可以看出在整个流程中,会有三组<key,value>键值对类型的存在。

2.3 MapReduce的处理流程
这里以WordCount单词计数为例,介绍map和reduce两个阶段需要进行哪些处理。单词计数主要完成的功能是:统计一系列文本文件中每个单词出现的次数,如图所示:

(1)map任务处理

(2)reduce任务处理

6、再跑wordcount例子
新建Map/Reduce Project:
【File】->【New】->【Project...】->【Map/Reduce】->【Map/Reduce Project】->【Project name: WordCount】->【Configure Hadoop install directory...】->【Hadoop installation directory: usr/local/hadoop/hadoop-1.2.1】->【Apply】->【OK】->【Next】->【Allow output folders for source folders】->【Finish】
新建WordCount类
添加/编写源代码:此代码是hadoop自带的,所以在hadoop安装目录下,如下图:(代码复制过来即可用)

上传模拟数据文件夹:此过程请参考本博客 http://www.cnblogs.com/yangxiao99/p/4574889.html
然后配置运行参数:
在新建的项目WordCount,点击WordCount.java,右键-->Run As-->Run Configurations

点击Run,运行程序
在此刻看到运行结果,如下图:
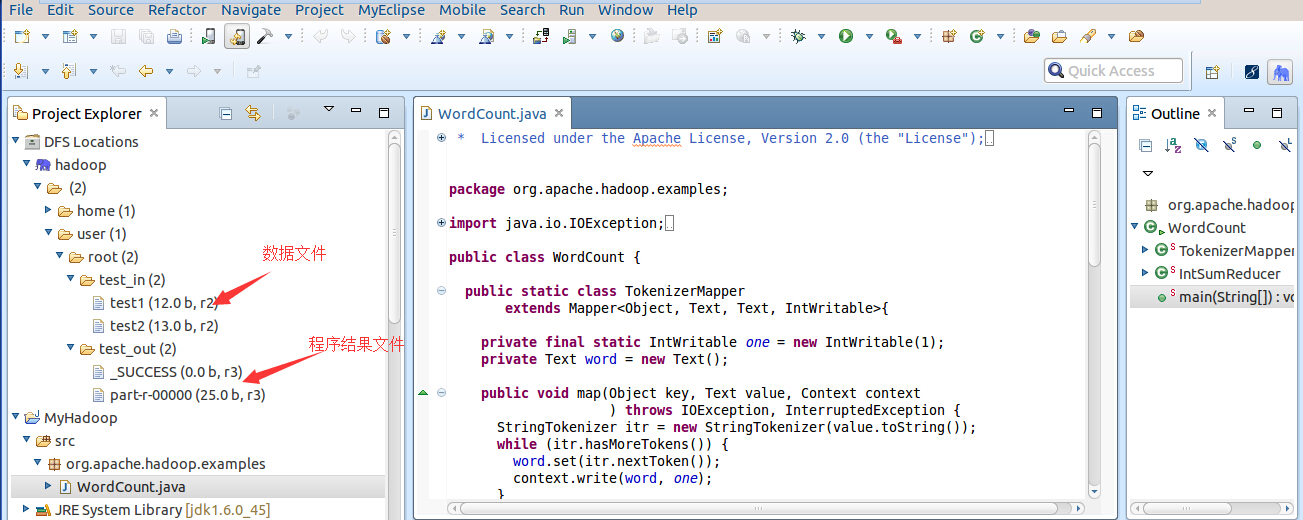
完毕!!!
欢迎各位来探讨交流:QQ:747861092
QQ群:163354117 (群名称:CodeForFuture)
每天收获一点点------Hadoop之初始MapReduce的更多相关文章
- 每天收获一点点------Hadoop基本介绍与安装配置
一.Hadoop的发展历史 说到Hadoop的起源,不得不说到一个传奇的IT公司—全球IT技术的引领者Google.Google(自称)为云计算概念的提出者,在自身多年的搜索引擎业务中构建了突破性的G ...
- 每天收获一点点------Hadoop概述
一.Hadoop来历 Hadoop的思想来源于Google在做搜索引擎的时候出现一个很大的问题就是这么多网页我如何才能以最快的速度来搜索到,由于这个问题Google发明了倒排索引算法,通过加入了Map ...
- 每天收获一点点------Hadoop Eclipse插件的使用
本文所用软件版本:myeclipe2014 hadoop1.2.1 1.安装Hadoop开发插件 下载hadoop-eclipse-plugin-1.2.1.jar,拷贝到myeclipse根目 ...
- 每天收获一点点------Hadoop RPC机制的使用
一.RPC基础概念 1.1 RPC的基础概念 RPC,即Remote Procdure Call,中文名:远程过程调用: (1)它允许一台计算机程序远程调用另外一台计算机的子程序,而不用去关心底层的网 ...
- 每天收获一点点------Hadoop之HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- Hadoop生态圈-使用MapReduce处理HBase数据
Hadoop生态圈-使用MapReduce处理HBase数据 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.对HBase表中数据进行单词统计(TableInputFormat) ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 从Hadoop框架与MapReduce模式中谈海量数据处理(含淘宝技术架构) (转)
转自:http://blog.csdn.net/v_july_v/article/details/6704077 从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到 ...
- Hadoop权威指南:MapReduce应用开发
Hadoop权威指南:MapReduce应用开发 [TOC] 一般流程 编写map函数和reduce函数 编写驱动程序运行作业 用于配置的API Hadoop中的组件是通过Hadoop自己的配置API ...
随机推荐
- KVC该机制
KVC该机制 KVC是cocoa的大招,用来间接获取或者改动对象属性的方式. 一.KVC的作用: KVC大招之中的一个: [self setValuesForKeysWithDictionary:di ...
- Qt中截图功能的实现
提要 需求:载入一张图片并显示,能够放大缩小,能够截取图片的某个矩形并保存. 原以为蛮简单的一个功能,事实上还是有点小复杂. 最简单Qt图片浏览器能够參考Qt自带的Demo:Image Viewer ...
- json2.js参考
json2.js使用參考 json2.js提供了json的序列化和反序列化方法,能够将一个json对象转换成json字符串,也能够将一个json字符串转换成一个json对象. <html> ...
- 于Unity3D动态创建对象和创建Prefab三种方式的原型对象
于Unity3D动态创建对象和创建Prefab三种方式的原型对象 u3d在动态创建的对象,需要使用prefab 和创建时 MonoBehaviour.Instantiate( GameObject o ...
- centos安装和卸载软件
==如何卸载: 1.打开一个SHELL终端 2.因为Linux下的软件名都包括版本号,所以卸载前最好先确定这个软件的完整名称. 查找RPM包软件:rpm -qa ×××* 注意:×××指软件名称开头的 ...
- tomcat 重启进程
查看端口: ps -aux | grep tomcat 发现并没有8080端口的Tomcat进程. 使用命令:netstat –apn 查看所有的进程和端口使用情况.发现下面的进程列表,其中最后一栏是 ...
- COM模块三---根的形成和注册代理server(Building and Registering a Proxy DLL)
Prerequisite:C++ 程序员,熟windows计划,熟Win32 Dll,了解windows注册表. 笔者:割者 上一篇文章中,我们定义了COM接口.通过编译生成了四个文件,本文使用这四个 ...
- Java 的布局管理器GridBagLayout的使用方法(转)
GridBagLayout是java里面最重要的布局管理器之一,可以做出很复杂的布局,可以说GridBagLayout是必须要学好的的, GridBagLayout 类是一个灵活的布局管理器,它不要求 ...
- RH033读书笔记(3)-Lab 4 Browsing the Filesystem
Lab 4 Browsing the Filesystem Sequence 1: Directory and File Organization 1. Log in as user student ...
- 管理Android通信录
Android提供了Contacts应用程序来管理联系人,并且Android系统还为联系人管理提供了ContentProvider,这就同意其他应用程序以ContentResolver来管理联系人数据 ...